一、一致性hash算法要解决的问题
在目前的分布式系统中,面对大数据量我们一般采用分片存储,从而满足系统的需要。
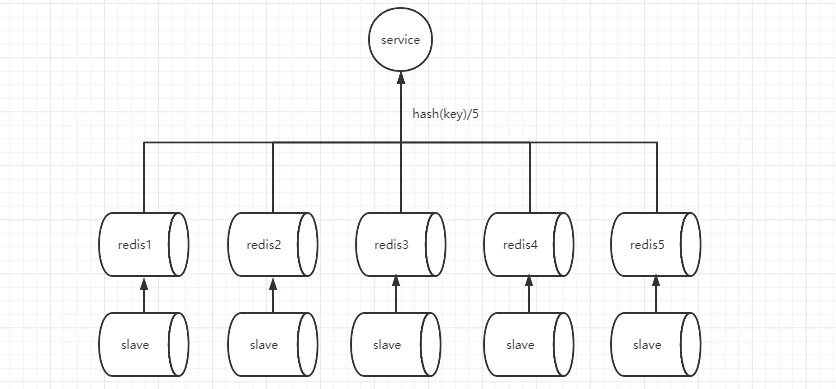
如图所示我们采用hash取模的方式计算数据的应该存储在那个redis中,获取数据也采用相同的方式;但是当我们需要再加一台redis服务器的时候,这种算法将无法获取老数据,这就需要我们把所有的数据重新插入一次,显然这样处理生产环境是不合理的。
二、一致性hash算法
来源: 一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
原理:

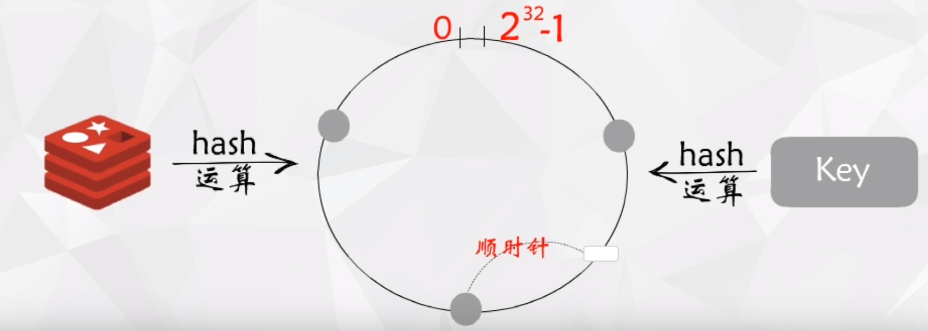
如图上图所示:我们先把redis服务器按照服务器名进行hash,然后确定服务器在hash环上的位置,当有key加入缓存时,我们根据key进行hash,这样可以确定该key在hash环上的位置,最后按照顺时针的方式找距离自己最近的服务器。
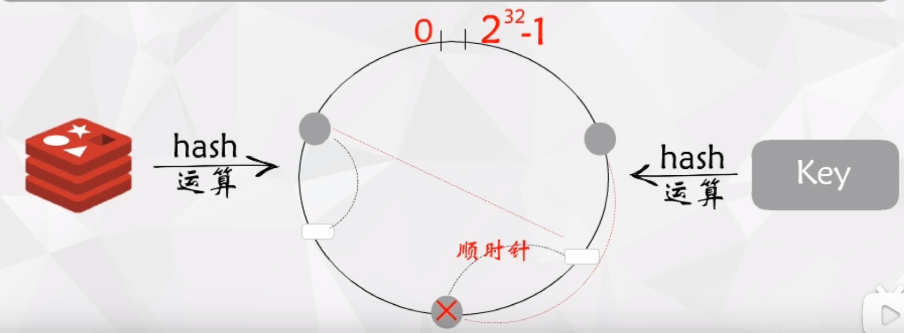
如图上图所示:当有一个服务器结点被下线后,我们只需要把之前落在该范围内的key迁移到他的前一个结点即可,由此我们发现该算法在服务器数量发生变化时只是局部数据需要调整,而hash取模的方式需要处理全部的数据。
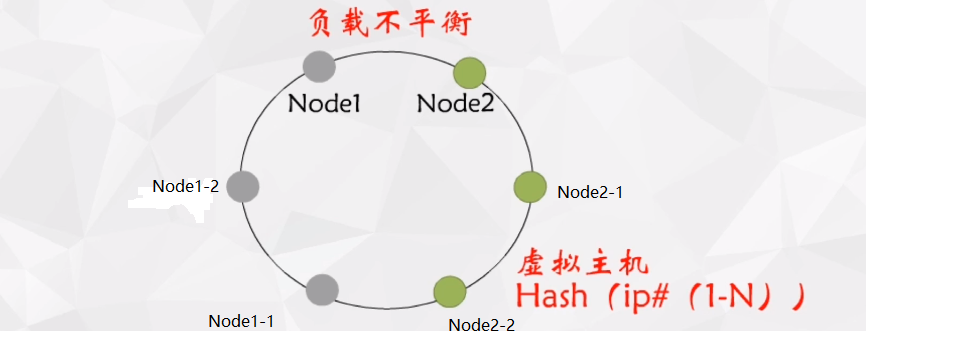
三、一致性hash算法不均衡问题
数据分布不均衡:如下图两个服务结点分布在hash环上的位置,则Node2接收的数据量远远小于Node1接收的数据量。

解决方案:引入虚拟结点,如下图所示我们引入虚拟结点,每个虚拟结点与真实结点是对应的(一个虚拟结点只能对应一个真实结点),当数据分布到虚拟结点时,我们把数据存储在真实节点上。