-
1. 概述
-
2. 主流程
-
3. ShareJoin
-
3.1 JoinParser
-
3.2 ShareJoin.processSQL(...)
-
3.3 BatchSQLJob
-
3.4 ShareDBJoinHandler
-
3.5 ShareRowOutPutDataHandler
-
4. 彩蛋
1. 概述
MyCAT 支持跨库表 Join,目前版本仅支持跨库两表 Join。虽然如此,已经能够满足我们大部分的业务场景。况且,Join 过多的表可能带来的性能问题也是很麻烦的。
本文主要分享:
-
整体流程、调用顺序图
-
核心代码的分析
前置阅读:《MyCAT 源码分析 —— 【单库单表】查询》。
2. 主流程
当执行跨库两表 Join SQL 时,经历的大体流程如下:

SQL 上,需要添加注解 /*!mycat:catlet=io.mycat.catlets.ShareJoin */${SQL} 。 RouteService#route(...) 解析注解 mycat:catlet 后,路由给 HintCatletHandler 作进一步处理。
HintCatletHandler 获取注解对应的 Catlet 实现类, io.mycat.catlets.ShareJoin 就是其中一种实现(目前也只有这一种实现),提供了跨库两表 Join 的功能。从类命名上看, ShareJoin 很大可能性后续会提供完整的跨库多表的 Join 功能。
核心代码如下:
-
// HintCatletHandler.java -
public RouteResultset route(SystemConfig sysConfig, SchemaConfig schema, -
int sqlType, String realSQL, String charset, ServerConnection sc, -
LayerCachePool cachePool, String hintSQLValue, int hintSqlType, Map hintMap) -
throws SQLNonTransientException { -
String cateletClass = hintSQLValue; -
if (LOGGER.isDebugEnabled()) { -
LOGGER.debug("load catelet class:" + hintSQLValue + " to run sql " + realSQL); -
} -
try { -
Catlet catlet = (Catlet) MycatServer.getInstance().getCatletClassLoader().getInstanceofClass(cateletClass); -
catlet.route(sysConfig, schema, sqlType, realSQL, charset, sc, cachePool); -
catlet.processSQL(realSQL, new EngineCtx(sc.getSession2())); -
} catch (Exception e) { -
LOGGER.warn("catlet error " + e); -
throw new SQLNonTransientException(e); -
} -
return null; -
}
3. ShareJoin
目前支持跨库两表 Join。 ShareJoin 将 SQL 拆分成左表 SQL 和 右表 SQL,发送给各数据节点执行,汇总数据结果进行合后返回。
伪代码如下:
-
// SELECT u.id, o.id FROM t_order o -
// INNER JOIN t_user u ON o.uid = u.id -
// 【顺序】查询左表 -
String leftSQL = "SELECT o.id, u.id FROM t_order o"; -
List leftList = dn[0].select(leftSQL) + dn[1].select(leftSQL) + ... + dn[n].select(leftsql); -
// 【并行】查询右表 -
String rightSQL = "SELECT u.id FROM t_user u WHERE u.id IN (${leftList.uid})"; -
for (dn : dns) { // 此处是并行执行,使用回调逻辑 -
for (rightRecord : dn.select(rightSQL)) { // 查询右表 -
// 合并结果 -
for (leftRecord : leftList) { -
if (leftRecord.uid == rightRecord.id) { -
write(leftRecord + leftRecord.uid 拼接结果); -
} -
} -
} -
}
实际情况会更加复杂,我们接下来一点点往下看。
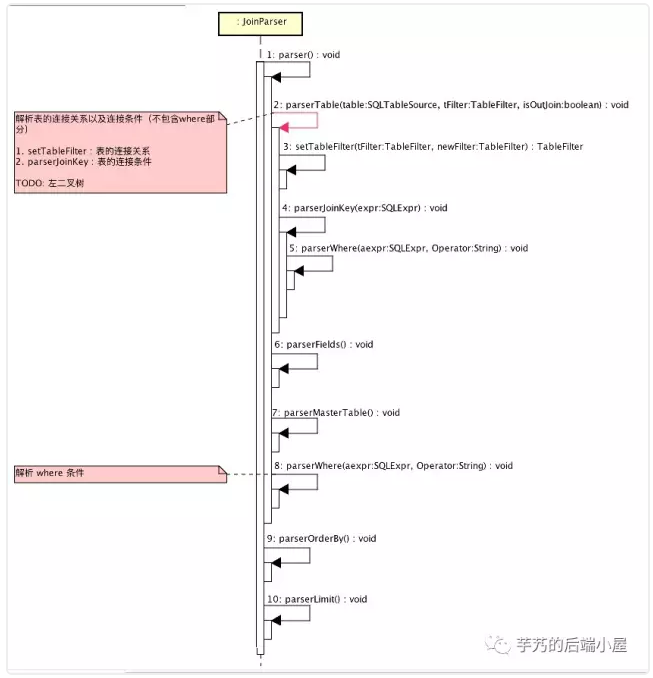
3.1 JoinParser
JoinParser 负责对 SQL 进行解析。整体流程如下:
举个例子, /*!mycat:catlet=io.mycat.catlets.ShareJoin */SELECT o.id,u.usernamefromt_order o join t_user u on o.uid=u.id; 解析后, TableFilter 结果如下:
-
tName :表名
-
tAlia :表自定义命名
-
where :过滤条件
-
order :排序条件
-
parenTable :左连接的 Join 的表名。
t_user表 在join属性 的parenTable为 "o",即t_order。 -
joinParentkey :左连接的 Join 字段
-
joinKey :join 字段。
t_user表 在join属性 为id。 -
join :子 tableFilter。即,该表连接的右边的表。
-
parent :和
join属性 相对。
看到此处,大家可能有疑问,为什么要把 SQL 解析成 TableFilter。 JoinParser 根据 TableFilter 生成数据节点执行 SQL。代码如下:
-
// TableFilter.java -
public String getSQL() { -
String sql = ""; -
// fields -
for (Entry<String, String> entry : fieldAliasMap.entrySet()) { -
String key = entry.getKey(); -
String val = entry.getValue(); -
if (val == null) { -
sql = unionsql(sql, getFieldfrom(key), ","); -
} else { -
sql = unionsql(sql, getFieldfrom(key) + " as " + val, ","); -
} -
} -
// where -
if (parent == null) { // on/where 等于号左边的表 -
String parentJoinKey = getJoinKey(true); -
// fix sharejoin bug: -
// (AbstractConnection.java:458) -close connection,reason:program err:java.lang.IndexOutOfBoundsException: -
// 原因是左表的select列没有包含 join 列,在获取结果时报上面的错误 -
if (sql != null && parentJoinKey != null && -
!sql.toUpperCase().contains(parentJoinKey.trim().toUpperCase())) { -
sql += ", " + parentJoinKey; -
} -
sql = "select " + sql + " from " + tName; -
if (!(where.trim().equals(""))) { -
sql += " where " + where.trim(); -
} -
} else { // on/where 等于号右边边的表 -
if (allField) { -
sql = "select " + sql + " from " + tName; -
} else { -
sql = unionField("select " + joinKey, sql, ","); -
sql = sql + " from " + tName; -
//sql="select "+joinKey+","+sql+" from "+tName; -
} -
if (!(where.trim().equals(""))) { -
sql += " where " + where.trim() + " and (" + joinKey + " in %s )"; -
} else { -
sql += " where " + joinKey + " in %s "; -
} -
} -
// order -
if (!(order.trim().equals(""))) { -
sql += " order by " + order.trim(); -
} -
// limit -
if (parent == null) { -
if ((rowCount > 0) && (offset > 0)) { -
sql += " limit" + offset + "," + rowCount; -
} else { -
if (rowCount > 0) { -
sql += " limit " + rowCount; -
} -
} -
} -
return sql; -
}
-
当
parent为空时,即on/where 等于号左边的表。例如:selectid,uidfromt_order。 -
当
parent不为空时,即on/where 等于号右边的表。例如:selectid,usernamefromt_userwhereidin(1,2,3)。
3.2 ShareJoin.processSQL(...)
当 SQL 解析完后,生成左边的表执行的 SQL,发送给对应的数据节点查询数据。大体流程如下:
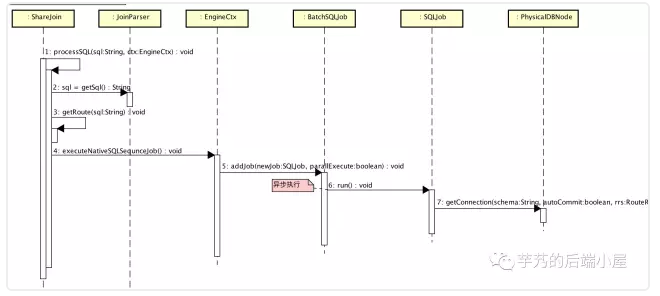
当 SQL 为 /*!mycat:catlet=io.mycat.catlets.ShareJoin */SELECT o.id,u.usernamefromt_order o join t_user u on o.uid=u.id; 时, sql=getSql() 的返回结果为 selectid,uidfromt_order。
生成左边的表执行的 SQL 后,顺序顺序顺序发送给对应的数据节点查询数据。具体顺序查询是怎么实现的,我们来看下章 BatchSQLJob。
3.3 BatchSQLJob

EngineCtx 对 BatchSQLJob 封装,提供上层两个方法:
-
executeNativeSQLSequnceJob :顺序(非并发)在每个数据节点执行SQL任务
-
executeNativeSQLParallJob :并发在每个数据节点执行SQL任务
核心代码如下:
-
// EngineCtx.java -
public void executeNativeSQLSequnceJob(String[] dataNodes, String sql, -
SQLJobHandler jobHandler) { -
for (String dataNode : dataNodes) { -
SQLJob job = new SQLJob(jobId.incrementAndGet(), sql, dataNode, -
jobHandler, this); -
bachJob.addJob(job, false); -
} -
} -
public void executeNativeSQLParallJob(String[] dataNodes, String sql, -
SQLJobHandler jobHandler) { -
for (String dataNode : dataNodes) { -
SQLJob job = new SQLJob(jobId.incrementAndGet(), sql, dataNode, -
jobHandler, this); -
bachJob.addJob(job, true); -
} -
}
BatchSQLJob 通过执行中任务列表、待执行任务列表来实现顺序/并发执行任务。核心代码如下:
-
// BatchSQLJob.java -
/** -
* 执行中任务列表 -
*/ -
private ConcurrentHashMap<Integer, SQLJob> runningJobs = new ConcurrentHashMap<Integer, SQLJob>(); -
/** -
* 待执行任务列表 -
*/ -
private ConcurrentLinkedQueue<SQLJob> waitingJobs = new ConcurrentLinkedQueue<SQLJob>(); -
public void addJob(SQLJob newJob, boolean parallExecute) { -
if (parallExecute) { -
runJob(newJob); -
} else { -
waitingJobs.offer(newJob); -
if (runningJobs.isEmpty()) { // 若无正在执行中的任务,则从等待队列里获取任务进行执行。 -
SQLJob job = waitingJobs.poll(); -
if (job != null) { -
runJob(job); -
} -
} -
} -
} -
public boolean jobFinished(SQLJob sqlJob) { -
runningJobs.remove(sqlJob.getId()); -
SQLJob job = waitingJobs.poll(); -
if (job != null) { -
runJob(job); -
return false; -
} else { -
if (noMoreJobInput) { -
return runningJobs.isEmpty() && waitingJobs.isEmpty(); -
} else { -
return false; -
} -
} -
}
-
顺序执行时,当
runningJobs存在执行中的任务时,#addJob(...)时,不立即执行,添加到waitingJobs。当SQLJob完成时,顺序调用下一个任务。 -
并发执行时,
#addJob(...)时,立即执行。
SQLJob SQL 异步执行任务。其 jobHandler(SQLJobHandler) 属性,在 SQL 执行有返回结果时,会进行回调,从而实现异步执行。
在 ShareJoin 里, SQLJobHandler 有两个实现: ShareDBJoinHandler、 ShareRowOutPutDataHandler。前者,左边的表执行的 SQL 回调;后者,右边的表执行的 SQL 回调。
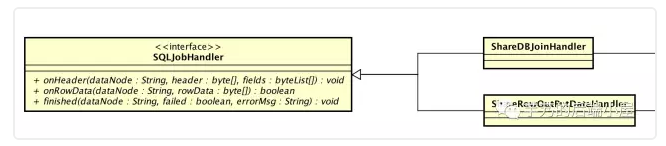
3.4 ShareDBJoinHandler
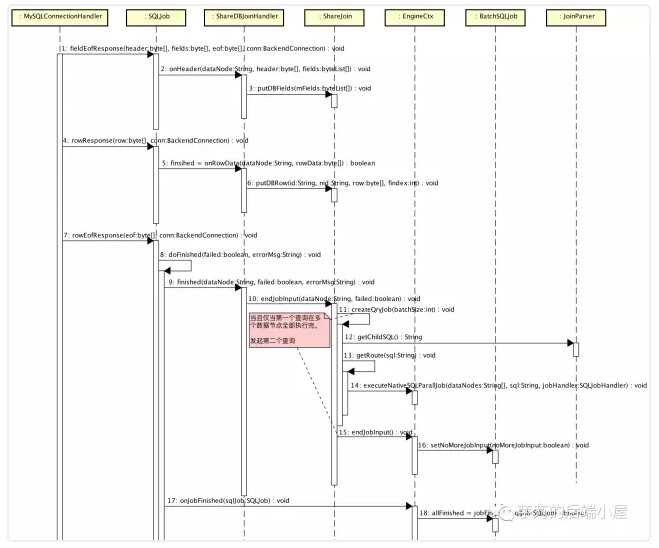
ShareDBJoinHandler,左边的表执行的 SQL 回调。流程如下:
-
#fieldEofResponse(...):接收数据节点返回的 fields,放入内存。 -
#rowResponse(...):接收数据节点返回的 row,放入内存。 -
#rowEofResponse(...):接收完一个数据节点返回所有的 row。当所有数据节点都完成 SQL 执行时,提交右边的表执行的 SQL 任务,并行执行,即图中#createQryJob(...)。
当 SQL 为 /*!mycat:catlet=io.mycat.catlets.ShareJoin */SELECT o.id,u.usernamefromt_order o join t_user u on o.uid=u.id; 时, sql=getChildSQL() 的返回结果为selectid,usernamefromt_userwhereidin(1,2,3)。
核心代码如下:
-
// ShareJoin.java -
private void createQryJob(int batchSize) { -
int count = 0; -
Map<String, byte[]> batchRows = new ConcurrentHashMap<String, byte[]>(); -
String theId = null; -
StringBuilder sb = new StringBuilder().append('('); -
String svalue = ""; -
for (Map.Entry<String, String> e : ids.entrySet()) { -
theId = e.getKey(); -
byte[] rowbyte = rows.remove(theId); -
if (rowbyte != null) { -
batchRows.put(theId, rowbyte); -
} -
if (!svalue.equals(e.getValue())) { -
if (joinKeyType == Fields.FIELD_TYPE_VAR_STRING -
|| joinKeyType == Fields.FIELD_TYPE_STRING) { // joinkey 为varchar -
sb.append("'").append(e.getValue()).append("'").append(','); // ('digdeep','yuanfang') -
} else { // 默认joinkey为int/long -
sb.append(e.getValue()).append(','); // (1,2,3) -
} -
} -
svalue = e.getValue(); -
if (count++ > batchSize) { -
break; -
} -
} -
if (count == 0) { -
return; -
} -
jointTableIsData = true; -
sb.deleteCharAt(sb.length() - 1).append(')'); -
String sql = String.format(joinParser.getChildSQL(), sb); -
getRoute(sql); -
ctx.executeNativeSQLParallJob(getDataNodes(), sql, new ShareRowOutPutDataHandler(this, fields, joinindex, joinParser.getJoinRkey(), batchRows, ctx.getSession())); -
}
3.5 ShareRowOutPutDataHandler
ShareRowOutPutDataHandler,右边的表执行的 SQL 回调。流程如下:
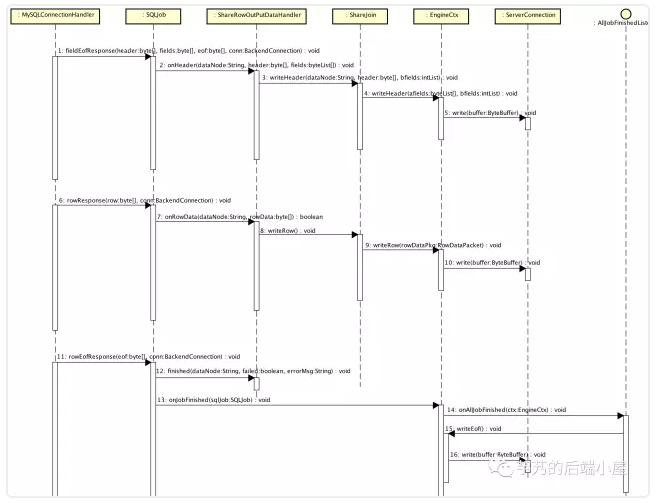
-
#fieldEofResponse(...):接收数据节点返回的 fields,返回 header 给 MySQL Client。 -
#rowResponse(...):接收数据节点返回的 row,匹配左表的记录,返回合并后返回的 row 给 MySQL Client。 -
#rowEofResponse(...):当所有 row 都返回完后,返回 eof 给 MySQL Client。
核心代码如下:
-
// ShareRowOutPutDataHandler.java -
public boolean onRowData(String dataNode, byte[] rowData) { -
RowDataPacket rowDataPkgold = ResultSetUtil.parseRowData(rowData, bfields); -
//拷贝一份batchRows -
Map<String, byte[]> batchRowsCopy = new ConcurrentHashMap<String, byte[]>(); -
batchRowsCopy.putAll(arows); -
// 获取Id字段, -
String id = ByteUtil.getString(rowDataPkgold.fieldValues.get(joinR)); -
// 查找ID对应的A表的记录 -
byte[] arow = getRow(batchRowsCopy, id, joinL); -
while (arow != null) { -
RowDataPacket rowDataPkg = ResultSetUtil.parseRowData(arow, afields);//ctx.getAllFields()); -
for (int i = 1; i < rowDataPkgold.fieldCount; i++) { -
// 设置b.name 字段 -
byte[] bname = rowDataPkgold.fieldValues.get(i); -
rowDataPkg.add(bname); -
rowDataPkg.addFieldCount(1); -
} -
// huangyiming add -
MiddlerResultHandler middlerResultHandler = session.getMiddlerResultHandler(); -
if (null == middlerResultHandler) { -
ctx.writeRow(rowDataPkg); -
} else { -
if (middlerResultHandler instanceof MiddlerQueryResultHandler) { -
byte[] columnData = rowDataPkg.fieldValues.get(0); -
if (columnData != null && columnData.length > 0) { -
String rowValue = new String(columnData); -
middlerResultHandler.add(rowValue); -
} -
//} -
} -
} -
arow = getRow(batchRowsCopy, id, joinL); -
} -
return false; -
}
4. 彩蛋
如下是本文涉及到的核心类,有兴趣的同学可以翻一翻。

ShareJoin 另外不支持的功能:
-
只支持 inner join,不支持 left join、right join 等等连接。
-
不支持 order by。
-
不支持 group by 以及 相关聚合函数。
-
即使 join 左表的字段未声明为返回 fields 也会返回。
恩,MyCAT 弱XA 源码继续走起!