1、Numpy
Numpy的核心对象:ndarray多维数组对象,数组允许使用类似于标量的操作语法在整块数据上进行数学计算(数组是一个矢量)。一个ndarray是一个通用的多维同类型数据容器,
它包含的每一个元素均为相同类型。
两个重要属性:shape,dtype,ndim
生成ndarray的方法:
(1)、array函数,可接收任意的序列型对象(包括数组),比如列表、元组、字符串、数组,生成一个新的包含传递数据的Numpy数组。
(2)、创建特殊数组:zeros,zeros_like,ones,ones_like,empty,empty_like,full,full_like,eye(或者identity)。其中full有几个重要参数:
shape,fill_value,dtype,order,fill_value指定元素值,order指定在内存中的存储方式,选项{'C','F'},是否在内存中以行为主(C风格)或列为主(Fortran风格)
连续(行或列)顺序存储多维数据
(3)、其他:asarray,arange。
astype:转换数组的数据类型
算术运算:批量操作,无需循环
注意:Numpy的切片不复制数据,而只是原数组的视图。这话怎么理解呢?Python中对列表的切片是会自动进行复制的,也就是说你切片得到的数据与原列表已经没有关系了,
对切片得到的数据的任何操作不影响原列表,而Numpy不一样,对数组切片或者索引只是给出原数组的一个视图,如果你熟悉内存的存储原理的话,可以这样理解,
切片或者索引得到的数据依然指向原数组的内存地址,而不是重新开辟一块内存。通俗地讲,不论是索引还是切片,相当于打开了一个窗口,借此浏览原数组的全部或部分元素,
而不重新生成数据(开辟内存),所以对索引或者切片得到的数据的操作也就是对原数组的操作,不论是重新赋值给其他变量还是直接操作,都会反映到原数组上。
2、Pandas
a.过滤缺失值:dropna函数 参数:axis : {0 or ‘index’, 1 or ‘columns’} how : {‘any’, ‘all’},默认值 any
any : 如果存在任何NA值,则放弃该标签
all : 如果所以的值NA值,则放弃该标签
thresh : int, 默认值 None
int value :要求每排至少N个非NA值
subset : 类似数组
inplace : boolean, 默认值 False
如果为True,则进行操作并返回None。
返回:被删除的DataFrame
b.pandas中索引对象:索引对象不可变,可通过pandas中的Index函数事先单独构建索引对象
1 import numpy as np 2 import pandas as pd 3 4 lables = pd.Index(['a','b','c']) 5 obj1 = pd.Series(np.arange(3),index=lables)
b.pandas中的rank函数
1 obj2 = pd.Series(np.random.randint(-15,20,size=20)) 2 obj21 = obj.sort_values() 3 obj22 = obj.rank()
obj2 obj21 obj22
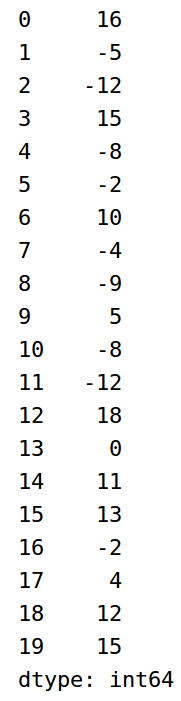
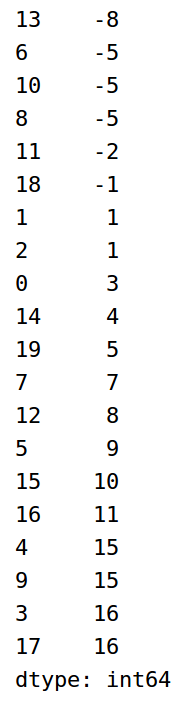
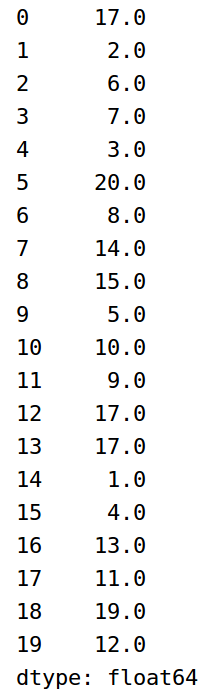
sort_values函数按元素大小排序,大小相同的按整数索引值排序,序号从1开始,以数据总个数结束,可以得到每个元素的唯一序号,rank函数以sort_values排序为基础,大小相同的元素以序号的平均值作为名次。
(1)pandas的两种数据类型之Series
1 mylist = list(['abcdefghijklmn'])2 myarr = np.arange(26) 3 mydict = {'a':1,'b':2,'c':3} 4 ser1 = pd.Series(mylist) 5 ser2 = pd.Series(myarr) 6 ser3 = pd.Series(mydict)
Series的属性与方法
属性:values,index,name(value的name),index.name(索引的name)
方法:使用布尔索引过滤,使用numpy的函数或numpy风格的操作
检查是否有缺失值:使用pandas对象的实例方法isnull,notnull,这同时也是pandas的函数
(2)pandas的两种数据类型之DataFrame
3、一些好用容易忘的API
日期字符串转换为datetime类型:to_datetime()
datetime类型转换成字符串格式:dates.dt.strftime()
4、利用numpy生成等比数列、等差数列
(1)生成等差数列
1)arange
例如:a = np.arange(0.1,1,10)
arange侧重于增量,不管产生多少个数;
2)linspace
例如:np.linspace(0.1,1,10,enpoint=True) # 默认为True
linspace侧重于产出多少个元素,不在乎增量;
(2)生成等比数列:logspace
例如:np.logspace(1, 4, 4, endpoint=True, base=2) # 默认为True
base代表基数,(1,4)代表起始幂和终止幂,4代表元素个数(如果换成随意数n,按起始幂和终止幂等分成n个数作为幂的取值),endpoint代表是否取终止值。
结果:2**1……2**4
5、numpy常用函数
numpy.loadtxt():直接读取文本文件并且获取ndarray数组对象;
numpy.mean():算术平均值;
np.average(closing_prices, weights=volumes):加权平均值;
np.max(),np.min(),np.ptp():返回一个数组中最大值/最小值/极差;
np.argmax(),mp.argmin():返回一个数组中最大/最小元素的下标;
np.maximum(),np.minimum():将两个同维数组中对应元素中最大/最小元素构成一个新的数组;
np.median():中位数;
np.sqrt():开方;
np.var():计算总体方差;
np.var(a,ddof=1):计算样本方差;
np.std():标准差;
np.convolve(a,b,卷积类型):有效卷积(valid),同维卷积(same),完全卷积(full);
6、apply_along_axis函数
新数组 = numpy.apply_along_axis(自定义的处理函数,轴向,ndarray对象)
功能:将多维数组某一个轴的数据作为参数给处理函数,并将处理函数的返回值添加到新数组,处理函数一般是聚合函数,用于计算轴向的数据和、平均值、最大值等
注:处理行或者列