本文转自:(4条消息) xilinx ddr3 MIG ip核使用详解_admiraion123的博客-CSDN博客
1,DDR3基本内容介绍
1.1,DDR3简介
DDR3全称double-data-rate 3 synchronous dynamic RAM,即第三代双倍速率同步动态随机存储器。所谓同步,是指DDR3数据的读取写入是按时钟同步的;所谓动态,是指DDR3中的数据掉电无法保存,且需要周期性的刷新,才能保持数据;所谓随机存取,即可以随机操作任一地址的数据;所谓double-data-rate,即时钟的上升沿和下降沿都发生数据传输。
DDR3读取速度是SDRAM的8倍,为什么呢?这里不是太懂,也一直没懂,因为感觉网上的资料都有问题,官方的DDR3手册也没有介绍这点。不过官方手册讲到DDR3采用8n prefetch技术,数据在存储矩阵和IO口之间有一个类似于FIFO的缓存结构。以16bit位宽的ddr3来说,存储矩阵与这个fifo的接口就为8*16bit = 124bit。那么问题来了,要实现最终的8倍传输,由于上下沿都采样,时钟可以扩展为原来的2倍;那么剩下的4倍就需要IO口频率来提高了;那么对于存储矩阵与fifo的接口的时钟是多少呢?这就不知道了,按照网上说的核心频率(为IO频率的1/4)的说法,那就需要数据线128根,这可能吗?不过这会不会也是单片ddr3位宽不能太高的原因?问题先留在这里,以后懂了在来解答。
以micron的MT41K256M16TW-107为例,MT41K为型号,256M16表示大小为256M*16 = 4Gb,TW为96pin BGA封装,-107为速度等级(时钟1.07ns,933Mhz,速度1866MT/s),平常说的DDR3 1333也就是指1s内传输1333次数据。该DDR3是8Bank配置,即BA[2:0];数据位宽配置为16bit;行地址A[14:0],列地址A[9:0],那么算下来正好4Gb。不过需要注意,由于8n prefetch,列地址A[2:0]实际上并不使用,因为存储矩阵中一个单元(CELL)为128bit,即一个Bank内是按32768*128*128划分的,如下图所示。

顺便讲一下逻辑Bank和物理Bank的区别,逻辑Bank即一片DDR3颗粒的Bank;物理Bank是在存储系统中才有的概念,计算机CPU为64bit,故向存储设备取数据也为64bit,那么就需要4片DDR3颗粒并联,那么总共的容量就位4Gb;那么问题来了,如果需要32Gb的容量呢?那么就需要32片DDR3颗粒,该DDR3最小位宽可配置为4bit,那么按照直接并联的方式就变成128bit位宽了,这时候就需要做成2个物理Bank。
DDR3的数据写入与读取都是按burst方式进行的,BC4一次burst进行4长度数据位宽传输,BL8一次burst进行8长度数据位宽传输,on-the-fly由用户控制8还是4。Burst模式有两种,sequential和interleaved,具体如图所示。

DDR3的运行流程大体为:上电复位;然后进入初始化流程,进行write leveling、ZQ校准后进入空闲状态,此后用户可对其进行读写操作;we#,ras#,cas#为控制信号;操作时,先激活某一bank某一行,然后再给列地址,写完后换另一行需要进行precharge操作;为了保持数据,DDR3需要refresh操作,一般规定行刷新周期为64ms,这里的行是针对所有bank的同一行,与precharge需要区分。具体如下图所示。
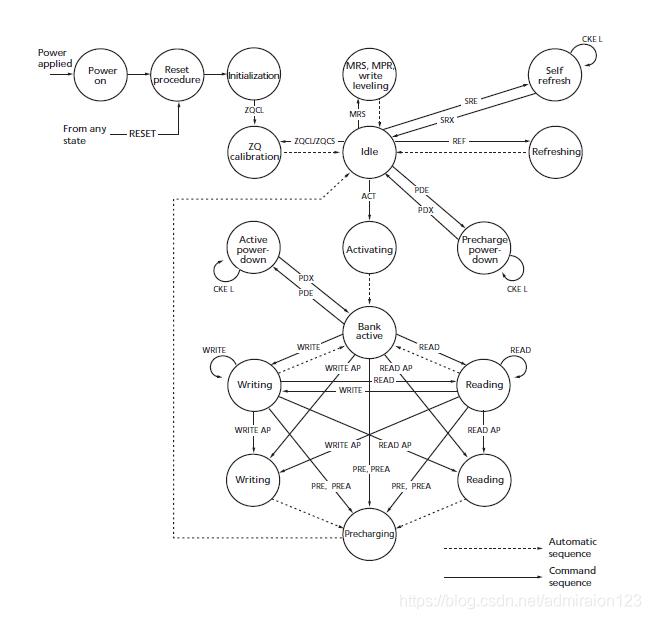
1.2,DDR3中一些关键信号及时间参数
1.2.1 关键信号
a,RAS#,行地址选通信号。
b,CAS#,列地址选通信号。
c,WE#,读写信号。
d,DQS差分信号,数据选通信号,与读数据边沿对齐,与写数据中心对齐。
e,CK差分信号,ddr3输入时钟,所有的控制、地址信号都以CK交叉点为采样点,DQS信号也是基于此信号得到。
2.2 时间参数
a,tRCD,行选通指令到列选通指令的延迟,以CK为计量单位,指行激活指令到读写指令的最小间隔。
b,CL,列选通指令潜伏期延迟,以CK为计量单位,指读指令到数据读出的最小间隔。
c,tRP,行预充电时间,以CK为计量单位,指预充电指令到行激活指令的延迟。
1.3,DDR3中常用指令
1. 3.1 precharge
预充电指令,ddr3换行操作时,需要先执行预充电指令,关闭当前工作行,然后再进行激活指令。地址线中的A10为1,则对所有bank进行预充电;如果A10位0,则选择ba[2:0]对应的bank进行预充电。
1.3.2 refresh
刷新指令,ddr3需要周期性刷新来维持存储单元中的数据,刷新指令针对所有bank,刷新中的行指所有bank中地址相同的行。具体如下图。
1.3.3 active
激活指令,用于激活某一bank的某一行。
1.3.4 read/write
读写指令,用于对某一起始地址进行操作。
1. 3.5 指令表
ddr3的指令表如下图所示。主要由RAS#、CAS#、WE#控制。比如刷新就是001,写就是100,读就是101。表中,V表示高电平或低电平,需要是一个确定的电平;CA表示列地址;H表示高电平;L表示低电平;BA表示bank地址;RFU我也不知道是什么意思。
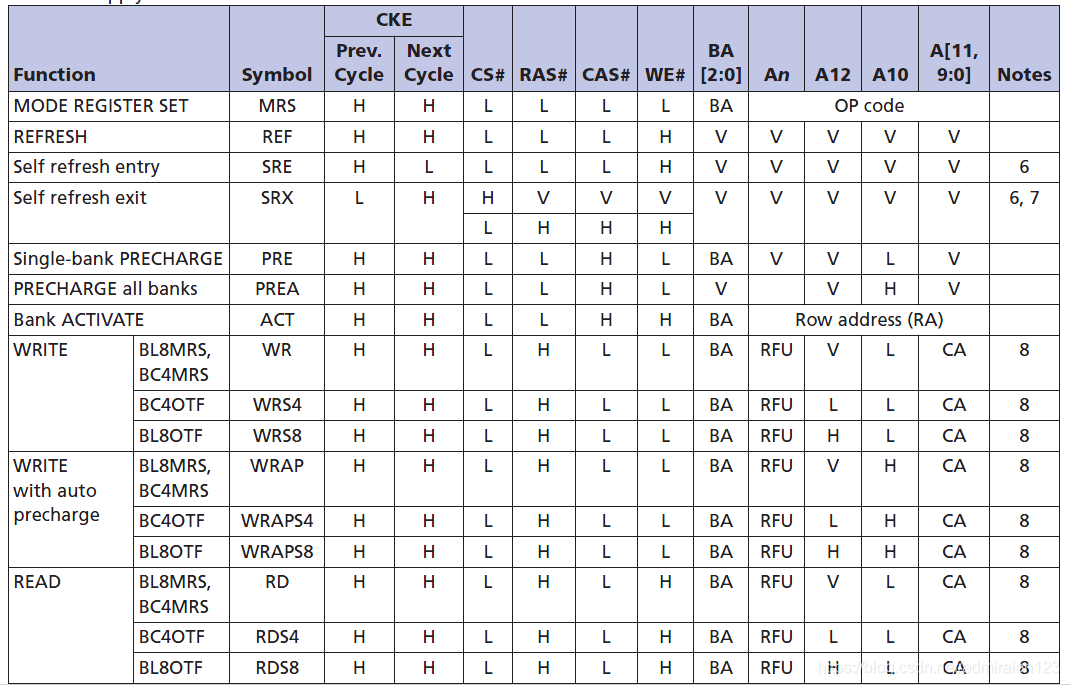
2,DDR3仿真
2.1,MIG核介绍
xilinx的ddr3控制IP核叫memory interface generator,下面介绍一下该IP核中的一些设置。MIG核的整体框图如下图所示,分为用户接口模块,存储控制模块、物理层模块,存储控制模块和phy模块完成ddr3相关时序控制,我们关注用户接口即可。用户接口大体分为指令路径和数据路径,都是基于握手协议的。如指令中必须app_en和app_rdy同时为高,app_cmd才被有效接收;又例如写数据通道中app_wdf_wren和app_wdf_rdy同时为高,app_wdf_data才会写入fifo。
MIG核配置需要注意的几点:
a,时钟频率,需要配置phy接口时钟,也就是ddr3的ck信号,如对于ddr3 1333,我们就需要配置为667Mhz,当然低于这个也是可以的(xilinx 7系列芯片ddr引脚支持的最大速率可查看ds181);还需要配置用户时钟,也就是fpga用户侧时钟,该时钟可按2:1和4:1配置,如果前面配置的phy时钟为667Mhz,那么2:1配置就为333Mhz,4:1配置就为167Mhz;还需要配置一个系统时钟,这个时钟主要为MIG各个时钟提供源,通过倍频得到用户时钟和phy时钟;最后还有一个参考时钟,该时钟用于Idelayctrl模块,控制fpga dq等引脚的延迟,一般为200Mhz。
b,系统时钟引脚,当使用内部mmcm产生时钟时,需设置no buffer;当使用引脚引入时钟时,那么外部差分时钟需要IBUFDS或者IBUG接入mig系统时钟引脚。同时,系统时钟所在的CC(clock capable)引脚必须和memory接口在同一column,且推荐放在和控制引脚一个bank,7系列fpga具体查询ug475 中的die level bank numbering。
c,phy时钟引脚,推荐放在一个字节组的dqs引脚。
d,当DDR3速率低于800Mhz时,可以设置internal Vref,释放Vref引脚作为普通io口使用。
e,其余管脚分配,7系列fpga需要查看UG475来看哪些bank可以用作memory接口,一般一个bank放数据组(对于32位ddr3,有4个字节组,一个字节组为8+2+1),一个bank放地址和控制引脚。需要注意的一点是有的bank虽然带有memory接口属性,但是不要使用,例如bank14,因为ddr3电平为1.5v或者1.35v,而bank14又是系统bank,flash引脚在这一bank,一般为3.3v,就冲突了。

2,MIG用户接口
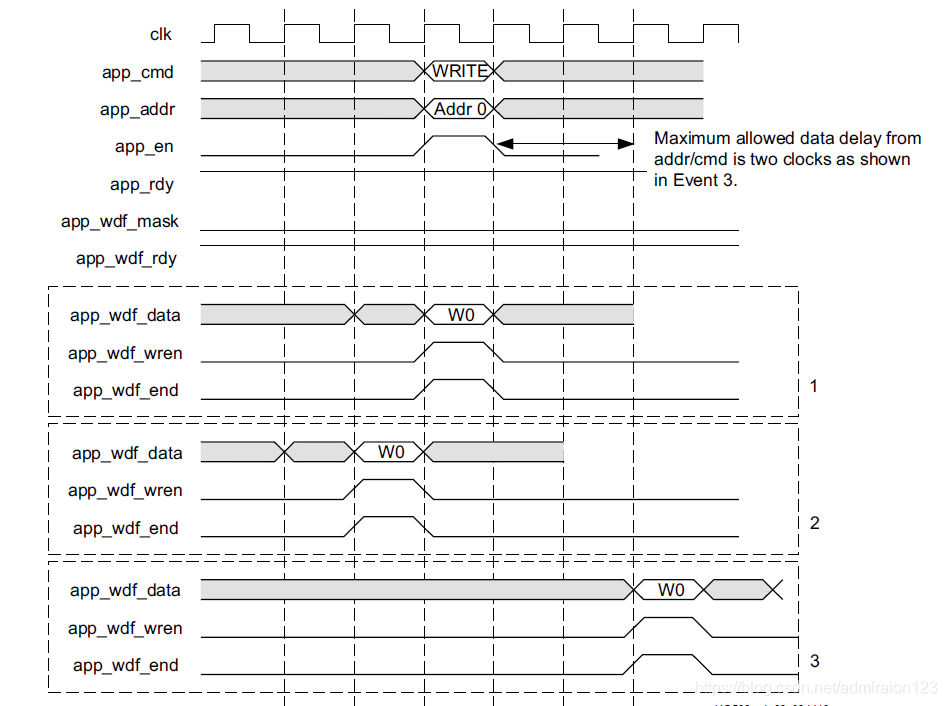
下图为一个写时序图,MIG核规定,写数据可以先与写指令,也可以和写指令同时发出,也可以在写指令之后,但是最多延迟2个周期,同时发出了写指令就一定要有写数据。写流程需要注意两点:
a,以32位ddr3为例,对于BL8模式,如果设置时钟比率为2:1,那么用户数据app_wdf_data位宽为128,那么一次burst需要两个app_wdf_data,那么app_wdf_end就应该在第二个app_wdf_data拉高;如果设置比率为4:1,那么用户数据app_wdf_data位宽为256,那么一次burst就需要一个app_wdf_data,同时app_wdf_end在每一个app_wdf_data拉高。
b,app_addr在BL8模式中按8增加。
c,内存数据的写入都是按intel模式,即小端模式,低地址放低字节,高地址放高字节,比如一个64‘h0001_0002_0003_0004’,那么写入dram的数据就为04 00 03 00 02 00 01 00。
下图为读时序,没什么好说的。
2.2 仿真结果
没啥好看的,前面说的差不多了。
3,实际应用
实际应用中,视频处理器就会用ddr3来作为视频帧缓存介质。
视频处理器一般的结构为:1,视频源接口(hdmi、dvi、dp、sdi等)经过视频解码芯片(sil9233、ep91a2e等),信号由模拟转为数字,供fpga使用(v_clk、vsync、hsync、de、dq)。2,fpga根据场同步信号vsync做帧同步,根据数据有效信号de或者行同步信号hsync做行同步。对于8位rgb图像,图像信号dq为24位。3,按流水线进行图像处理的相关操作(色域校正、色温校正、gama等),然后存入ddr3。4,网口根据面积区域参数,从ddr3中读出相应的数据并发出。
这其中有一些关键点:
1,时钟域的转换,最开始数据是在解码芯片出来的像素时钟域,一般做处理时需要转换到系统时钟域,存储时又需要转换到ddr3时钟域,最后网口发送又需要转换到网口时钟域,如果用到光纤,那么会用到serdes ip,那么这里还有一个网口时钟到serdes tx时钟的转换 ,我们使用serdes时,一般接收、发送都采用内部时钟,最终收数据或者发数据都采用serdes ip发出来的时钟 。功能实现当然是通过异步fifo实现的。
2,数据处理,这里主要包含两个部分:一是数据位宽的处理,一个像素点是24bit(按8bit图像计算),而最终存储的ddr3用户接口为256bit(按4:1时钟,32位位宽),那么就有一个24bit到256bit的转换。 二是图像处理,即将像素点并行处理,做乘法运算,具体一个处理几个点,根据速度定,点数越多,需要的并行模块越多,消耗的资源越多。
实际应用中,我是先将24bit数据转换为48bit数据,图像一行一行来,可能是奇数个点,也可能是偶数个点,如果一行图像为奇数个点,那么最后一个48bit的高24bit就是无效数据,为了后面处理方便,我将每个点加上两个标志位,一个数据有效信号de,一个最后一个像素点信号de_last,每个像素点变为26bit,然后通过fifo进行跨时钟域处理(这里fifo非空就读)。在系统时钟域中,我们做图像校正处理,一次处理两个点,那么就需要并行6个乘法器;如果还需要做其他处理,就继续以流水线的方式处理,注意最后要把两个标志位时序对齐。接下来就是48bit到256bit的转化,我先找出两者的最小公倍数即768,那么48bit就需要16个单元,设计时按0~15计数,向256x2的两个ram中写数据(这里有pingpong操作的思想),在计数为5、10、15以及最后de_last信号处,置高fifo写使能信号即可,同样,由于图像点不一定能组成256的倍数,因此最后还需要强制写一次。至于什么时候读,看自己考虑,可以等fifo计数为128时开始读fifo,正好写一行ddr3,但是需要注意最后要强制读一次。最后就是从ddr3读数据通过网口发出去,一般情况下各个网口通过轮询的方式将上位机设置的面积发送出去,这里生每个网口发送模块需要用到fifo,而且此fifo的读时机和深度选择是需要慎重考虑的,既要保证数据无溢出,又要保证fifo不被读空。同时,上位机的面积参数转换到ddr3的地址,也是需要计算的。
总的来说,ddr3的使用难点并不在于本身的控制,而在于带宽的分配。一般对ddr3的操作都采用pingpong操作,提高速度。另外,数据流的处理应该慎重考虑什么地方分开,什么地方聚合;数据怎么写入,就应该怎么读出,提前设计好ddr3的存储模型。
4,后话
由于sdram的控制和ddr3差不多,这里也提几句吧。sdram不能像ddr3那样缓存多个指令,因此控制起来较为简单,可以自己写驱动,具体思路就是先初始化,然后等待相应的操作跳转到对应状态机,修改we、ras、cas、地址、数据等信号,没有操作就跳转到刷新。实际应用中,我的sdram操作主要包含4个状态两两互为pingpong,一是图像的存储,一行一行的存储,数据没有紧密排列,而是一个点24bit占一个存储单元32bit;二是从一中读取存储的图像,做图像处理,如gamma校正、亮度色度校正、修缝、切片交织等,这两个互为pingpong。三是将处理的数据重新写入sdram,四是从三写入的数据中读出供显示驱动使用,这两个互为pingpong。当然还有一些其他占用sdram带宽的地方,比如上电校正系数的加载、快速升级等。
————————————————
版权声明:本文为CSDN博主「admiraion123」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/admiraion123/article/details/107891017