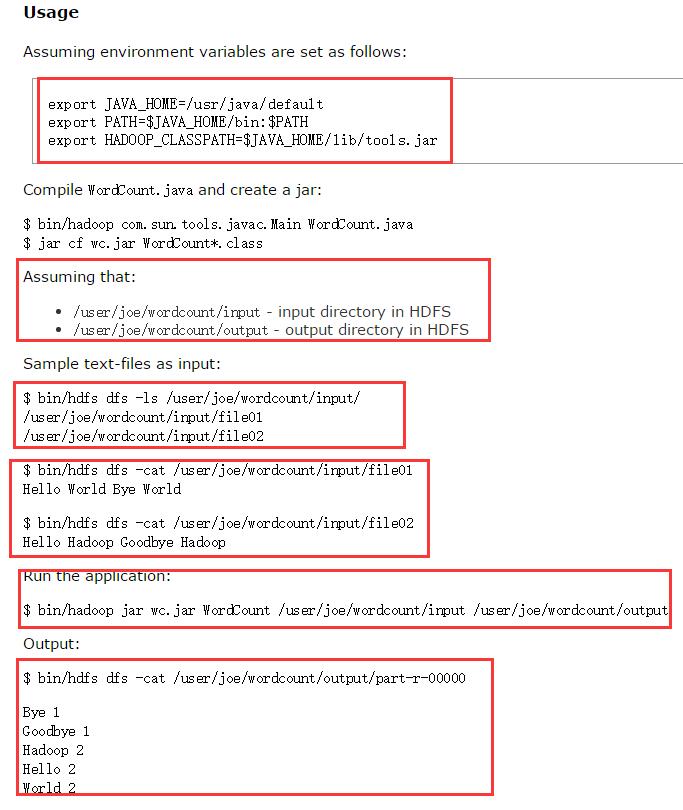
看了官网上的示例:但是给的不是很清楚,这里依托官网给出的示例,加上自己的实践,解析worcount程序的操作
1.首先你的确定你的集群正确安装,并且启动你的集群,应为这个是hadoop2.6.0,所以你的启动以下的守护进程:
$sbin/ ./start-dfs.sh
$sbin/ ./start-yarn.sh
$sbin/ mr-jobhistory-daemon.sh start historyserver
2.在lccal系统上创建两个文件,记住是文件,命名:file01,file02
笔者在/opt/localdata 下创建的file01,file02,内容如下


3.将本地的file01,file02上传至hdfs文件系统,利用命令
首先在hdfs文件系统上创建目录:输入目录 /library/wordcount/input/ 输出目录 /library/wordcount/output/
创建输入目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/input/
创建输出目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/output/
将本地的文件copy到hdfs文件系统
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file01 /library/wordcount/input/
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file02 /library/wordcount/input/
完成之后可以查看文件是否copy过去
$bin/ hdfs dfs -ls /library/wordcount/input/

4.可以运行程序了
进入目录:cd $HADOOP_HOME/share/hadoop/mapreduce
运行命令$ hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /library/wordcount/input/ /library/wordcount/output/rs_wordcount
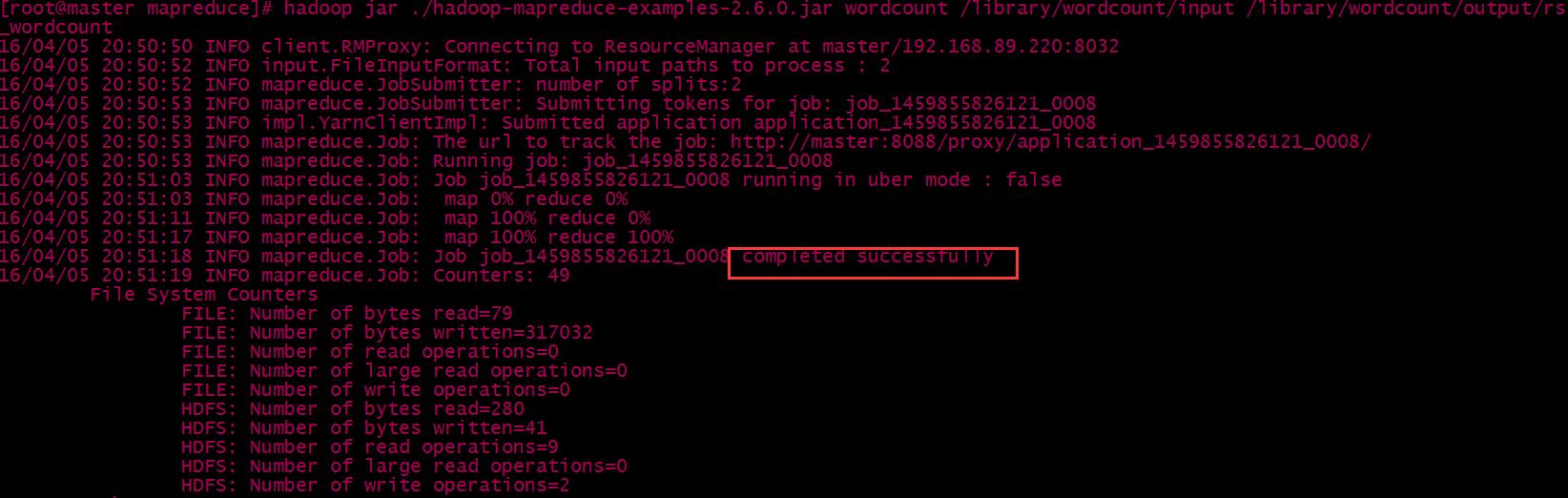
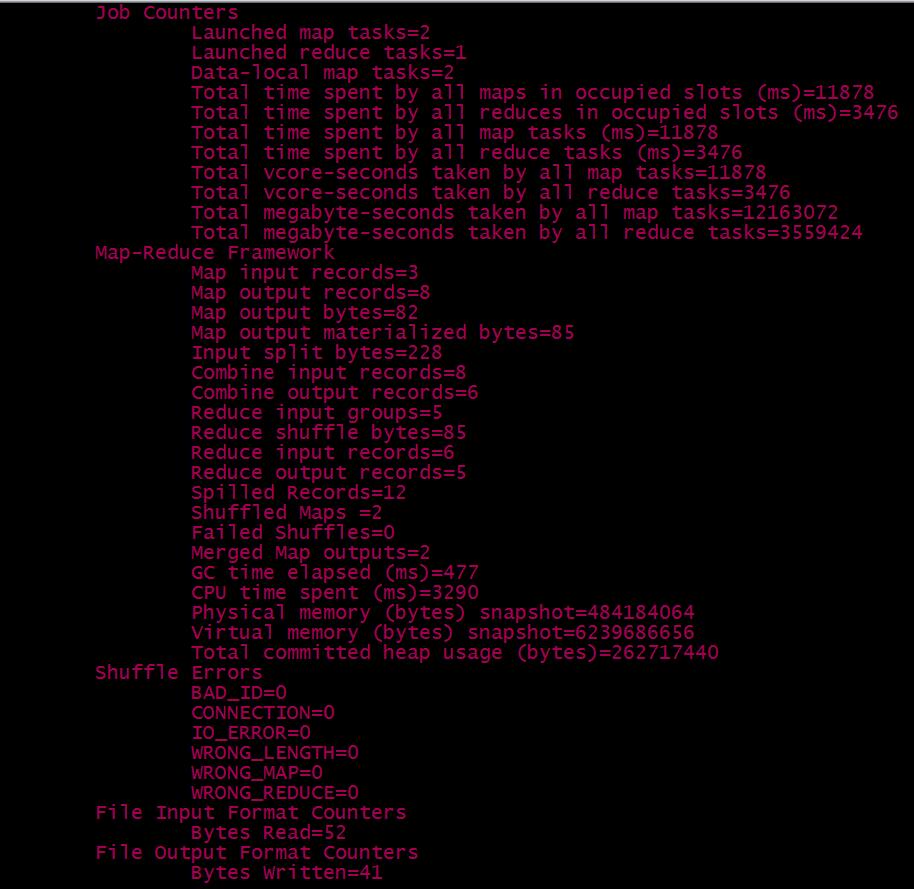
运行成功
5.查看运行结果
①web查看,首先需要设置web的,可以参考我的另外一篇博客http://www.cnblogs.com/jasonHome/p/5303040.html 自行设置
在浏览器输入:master:50070 (笔者将namenode的主机设置为master)
点击utilities ->brows the file system 如下图
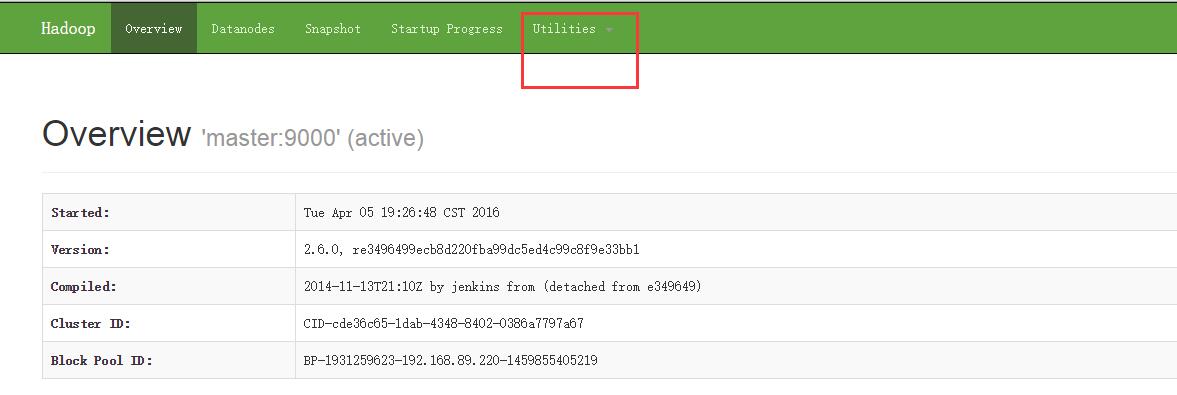
在hdfs文件系统中查看生成的文件结果文件:搜索 /library/wordcount/output/rs_wordcount
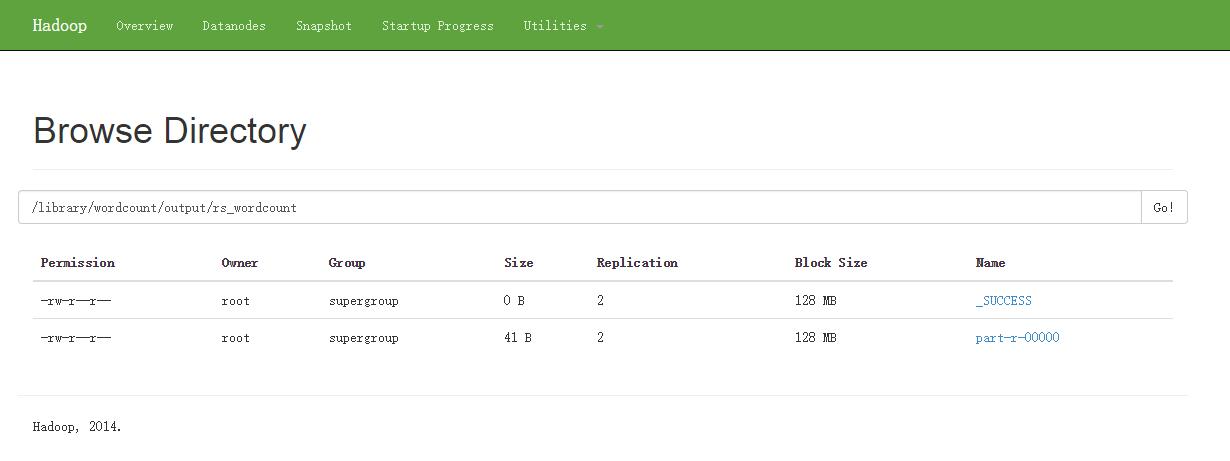
点击part-r-00000,就可以查看了
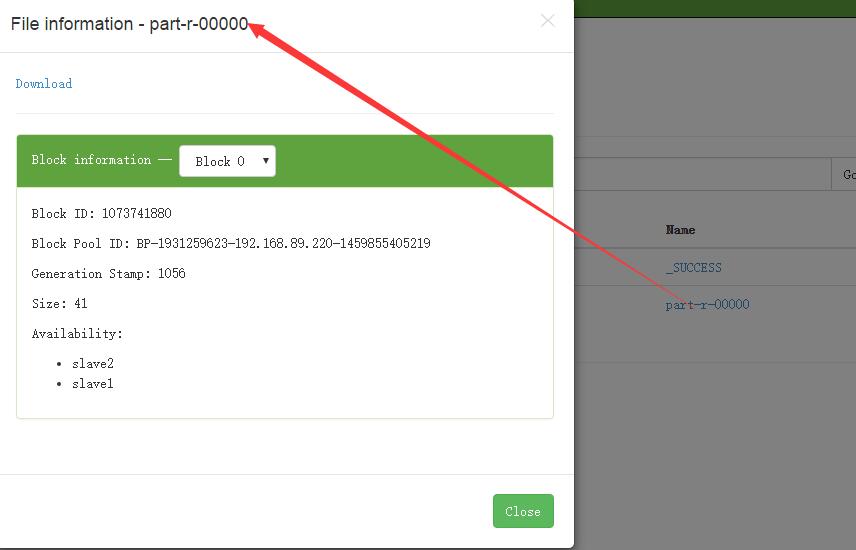
②可以通过命令行查看:
$ bin/hdfs dfs -cat /library/wordcount/output/part-r-00000
结果如下

补充:还可以通过 master:8088查看集群的情况, master:19888查看历史提交的任务和记录,如下图
master:8088

master:19888

好了,这就是我想和大家分享的,自己琢磨了 ,5个小时左右,如有问题,希望大家指正。