在Mysql中我们常常用order by来进行排序,使用limit来进行分页,当需要先排序后分页时我们往往使用类似的写法select * from 表名 order by 排序字段 limt M,N。但是这种写法却隐藏着较深的使用陷阱。在排序字段有数据重复的情况下,会很容易出现排序结果与预期不一致的问题。
比如现在有一张user表,表结构及数据如下:

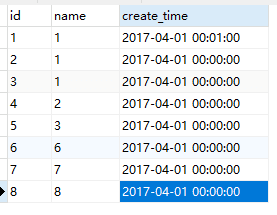
现在想根据创建时间升序查询user表,并且分页查询,每页2条,那很容易写出sql为:select * from user order by create_time limit pageNo,2;
在执行查询过程中会发现:
1、查询第一页数据时:
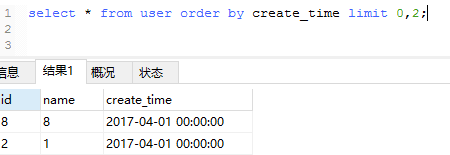
2、查询第四页数据时:
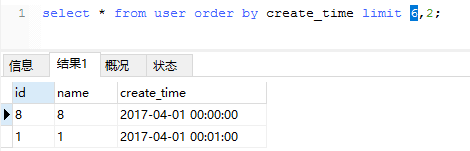
user表共有8条数据,有4页数据,但是实际查询过程中第一页与第四页竟然出现了相同的数据。
这是什么情况?难道上面的分页SQL不是先将两个表关联查询出来,然后再排好序,再取对应分页的数据吗???
上面的实际执行结果已经证明现实与想像往往是有差距的,实际SQL执行时并不是按照上述方式执行的。这里其实是Mysql会对Limit做优化,具体优化方式见官方文档:https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
这个是5.7版本的说明,提取几个问题直接相关的点做下说明。

上面官方文档里面有提到如果你将Limit row_count与order by混用,mysql会找到排序的row_count行后立马返回,而不是排序整个查询结果再返回。如果是通过索引排序,会非常快;如果是文件排序,所有匹配查询的行(不带Limit的)都会被选中,被选中的大多数或者全部会被排序,直到limit要求的row_count被找到了。如果limit要求的row_count行一旦被找到,Mysql就不会排序结果集中剩余的行了。
这里我们查看下对应SQL的执行计划:

可以确认是用的文件排序,表确实也没有加额外的索引。所以我们可以确定这个SQL执行时是会找到limit要求的行后立马返回查询结果的。
不过就算它立马返回,为什么分页会不准呢?
官方文档里面做了如下说明:

如果order by的字段有多个行都有相同的值,mysql是会随机的顺序返回查询结果的,具体依赖对应的执行计划。也就是说如果排序的列是无序的,那么排序的结果行的顺序也是不确定的。
基于这个我们就基本知道为什么分页会不准了,因为我们排序的字段是create_time,正好又有几个相同的值的行,在实际执行时返回结果对应的行的顺序是不确定的。对应上面的情况,第一页返回的name为8的数据行,可能正好排在前面,而第四页查询时name为8的数据行正好排在后面,所以第四页又出现了。
那这种情况应该怎么解决呢?
官方给出了解决方案:

如果想在Limit存在或不存在的情况下,都保证排序结果相同,可以额外加一个排序条件。例如id字段是唯一的,可以考虑在排序字段中额外加个id排序去确保顺序稳定。
所以上面的情况下可以在SQL再添加个排序字段,比如fund_flow的id字段,这样分页的问题就解决了。修改后的SQL可以像下面这样:
SELECT * FROM user ORDER BY create_time,id LIMIT 6,2;
再次测试问题解决!!