本文主要介绍SparkSQL的优化器系统Catalyst,其设计思路基本都来自于传统型数据库,而且和大多数当前的大数据SQL处理引擎设计基本相同(Impala、Presto、Hive(Calcite)等),因此通过本文的学习也可以基本了解所有其他SQL处理引擎的工作原理。
SQL优化器核心执行策略主要分为两个大的方向:基于规则优化(RBO)以及基于代价优化(CBO),基于规则优化是一种经验式、启发式地优化思路,更多地依靠前辈总结出来的优化规则,简单易行且能够覆盖到大部分优化逻辑,但是对于核心优化算子Join却显得有点力不从心。举个简单的例子,两个表执行Join到底应该使用BroadcastHashJoin还是SortMergeJoin?当前SparkSQL的方式是通过手工设定参数来确定,如果一个表的数据量小于这个值就使用BroadcastHashJoin,但是这种方案显得很不优雅,很不灵活。基于代价优化就是为了解决这类问题,它会针对每个Join评估当前两张表使用每种Join策略的代价,根据代价估算确定一种代价最小的方案。
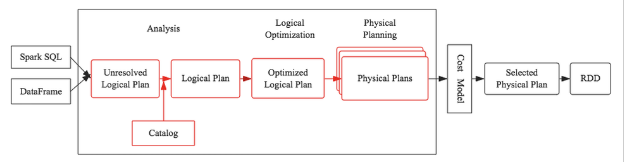
在介绍SQL优化器工作原理之前,有必要首先介绍两个重要的数据结构:Tree和Rule。相信无论对SQL优化器有无了解,都肯定知道SQL语法树这个概念,不错,SQL语法树就是SQL语句通过编译器之后会被解析成一棵树状结构。这棵树会包含很多节点对象,每个节点都拥有特定的数据类型,同时会有0个或多个孩子节点(节点对象在代码中定义为TreeNode对象)。在任何一个SQL优化器中,通常会定义大量的Rule(后面会讲到),SQL优化器会遍历语法树中每个节点,针对遍历到的节点模式匹配所有给定规则(Rule),如果有匹配成功的,就进行相应转换,如果所有规则都匹配失败,就继续遍历下一个节点。
