一、hibernate配置文件和映射
配置文件:hibernate.cfg.xml


<?xml version="1.0" encoding="GBK"?>
<!-- 指定Hibernate配置文件的DTD信息 -->
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<!-- hibernate- configuration是连接配置文件的根元素 -->
<hibernate-configuration>
<session-factory>
<!-- 指定连接数据库所用的驱动 -->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<!-- 指定连接数据库的url,hibernate连接的数据库名 -->
<property name="connection.url">jdbc:mysql://localhost/数据库名</property>
<!-- 指定连接数据库的用户名 -->
<property name="connection.username">root</property>
<!-- 指定连接数据库的密码 -->
<property name="connection.password">32147</property>
<!-- 指定连接池里最大连接数 -->
<property name="hibernate.c3p0.max_size">20</property>
<!-- 指定连接池里最小连接数 -->
<property name="hibernate.c3p0.min_size">1</property>
<!-- 指定连接池里连接的超时时长 -->
<property name="hibernate.c3p0.timeout">5000</property>
<!-- 指定连接池里最大缓存多少个Statement对象 -->
<property name="hibernate.c3p0.max_statements">100</property>
<property name="hibernate.c3p0.idle_test_period">3000</property>
<property name="hibernate.c3p0.acquire_increment">2</property>
<property name="hibernate.c3p0.validate">true</property>
<!-- 指定数据库方言 -->
<property name="dialect">org.hibernate.dialect.MySQLInnoDBDialect</property>
<!-- 根据需要自动创建数据表 -->
<property name="hbm2ddl.auto">update</property>
<!-- 显示Hibernate持久化操作所生成的SQL -->
<property name="show_sql">true</property>
<!-- 将SQL脚本进行格式化后再输出 -->
<property name="hibernate.format_sql">true</property>
<!-- 罗列所有的映射文件 -->
<mapping resource="映射文件路径/News.hbm.xml"/>
</session-factory>
</hibernate-configuration>
映射文件:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<!--
<hibernate-mapping>一般不去配置,采用默认即可。
schema:指定映射数据库的schema(模式/数据库),如果指定该属性,则表名会自动添加该schema前缀
package:指定包前缀 指定持久化类所在的包名 这样之后calss子元素中就不必使用全限定性的类名
default-cascade="none":默认的级联风格,表与表联动。
default-lazy="true":默认延迟加载
-->
<hibernate-mapping>
<!--
<class>:使用class元素定义一个持久化类。
name="cn.javass.user.vo.UserModel":持久化类的java全限定名;
table="tbl_user":对应数据库表名,默认持久化类名作为表名;
proxy:指定一个接口,在延迟装载时作为代理使用,也可在这里指定该类自己的名字。
mutable="true":默认为true,设置为false时则不可以被应用程序更新或删除,等价于所有<property>元素的update属性为false,表示整个实例不能被更新。
dynamic-insert="false":默认为false,动态修改那些有改变过的字段,而不用修改所有字段;
dynamic-update="false":默认为false,动态插入非空值字段;
select-before-update="false":默认为false,在修改之前先做一次查询,与用户的值进行对比,有变化都会真正更新;
optimistic-lock="version":默认为version(检查version/timestamp字段),取值:all(检查全部字段)、dirty(只检查修改过的字段);
none(不使用乐观锁定),此参数主要用来处理并发,每条值都有固定且唯一的版本,版本为最新时才能执行操作;
如果需要采用继承映射,则class元素下还会增加<subclass.../>元素等用于定义子类。
-->
<class name="cn.javass.user.vo.UserModel" table="tbl_user" >
<!--
<id>:定义了该属性到数据库表主键字段的映射。
type 指定该标识属性的数据类型,该类型可以是Hibernate的内建类型,也可以是java类型,如果是java类型则需要使用全限定类名(带包名)。该属性可选,如果没有指定类型, 则hibernate自行判断该标识属性数据类型。通常建议设定。
name="userId":标识属性的名字;
column="userId":表主键字段的名字,如果不填写与name一样;
-->
<id name="userId">
<!-- <generator>:指定主键由什么生成,推荐使用uuid,assigned指用户手工填入。设定标识符生成器
适应代理主键的有:
increment:有Hibernat自动以递增的方式生成标识符,每次增量1;
identity:由底层数据库生成标识符,前提条件是底层数据库支持自动增长字段类型。(DB2,MYSQL)
uuid:用128位的UUID算法生成字符串类型标识符。
适应自然主键:
assigned:由java程序负责生成标识符,为了能让java应用程序设置OID,不能把setId()方法设置成private类型。
让应用程序在save()之前为对象分配一个标识符。相当于不指定<generator.../>元素时所采用的默认策略。
应当尽量避免自然主键
-->
<generator class="uuid"/>
</id>
<!--
<version/>:使用版本控制来处理并发,要开启optimistic-lock="version"和dynamic-update="true"。
name="version":持久化类的属性名,column="version":指定持有版本号的字段名;
-->
<version name="version" column="version"/>
<!--
<property>:为类定义一个持久化的javaBean风格的属性。
name="name":标识属性的名字,以小写字母开头;
column="name":表主键字段的名字,如果不填写与name一样;
update="true"/insert="true":默认为true,表示可以被更新或插入;
access="property/field":指定Hibernate访问持久化类属性的方式。默认property。property表示使用setter/getter方式。field表示运用java反射机制直接访问类的属性。
formula="{select。。。。。}":该属性指定一个SLQ表达式,指定该属性的值将根据表达式类计算,计算属性没有和它对应的数据列。
formula属性允许包含表达式:sum,average,max函数求值的结果。
例如:formula="(select avg(p.price) from Product P)"
-->
<property name="name" column="name" />
<property name="sex" column="sex"/>
<property name="age" column="age"/>
<!--
组件映射:把多个属性打包在一起当一个属性使用,用来把类的粒度变小。
<component name="属性,这里指对象">
<property name="name1"></property>
<property name="name2"></property>
</component>
-->
<!--
<join>:一个对象映射多个表,该元素必须放在所有<property>之后。
<join table="tbl_test:子表名">
<key column="uuid:子表主键"></key>
<property name="name1:对象属性" column="name:子表字段"></property>
</join>
-->
</class>
</hibernate-mapping>
二、hibernate查询
2.1 HQL查询方式
public class TestGetHql {
private static Configuration cfg = new Configuration().configure();
private static SessionFactory fac = cfg.buildSessionFactory();
private static Session son = fac.openSession();
// hql普通查询 Card为类名,不是表名,可以写全路径
public static void from() {
String hql = "from Card";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName());
System.out.println(c.getCreateDate());
}
}
// 条件查询 where
public static void where() {
String hql = "from Card where cardName='三国无双'";
Query query = son.createQuery(hql);
List<Card> cardss = query.list();
for (Card c : cardss) {
System.out.println(c.getCardName());
System.out.println(c.getCreateDate());
}
}
// 模糊查询 like
public static void like() {
String hql = "from Card where cardName like '%世%'";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName());
System.out.println(c.getCreateDate());
}
}
// 逻辑条件查询 >
public static void gt() {
String hql = "from Card c where c.createDate >'2011-08-08'";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName());
System.out.println(c.getCreateDate());
}
}
// 逻辑条件查询 between and 此处用了别名,省略了as关键字
public static void between() {
String hql = "from Card c where c.createDate between '2011-08-08' and '2022-11-11'";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName());
System.out.println(c.getCreateDate());
}
}
// 逻辑多条件查询and
public static void and() {
String hql = "from Card c where c.createDate between '2011-01-08' and '2022-11-11' and c.cardName like '%世%'";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName());
System.out.println(c.getCreateDate());
}
}
// update 更新
public static void update() {
String hql = "update Card as c set c.createDate='2011-03-03' where c.cardType.cardTypeId=3";
Query query = son.createQuery(hql);
int num = query.executeUpdate();
System.out.println(num + "行被更新。。。");
}
// delete删除
public static void delete() {
String hql = "delete from Card as c where c.createDate='2011-03-04'";
Query query = son.createQuery(hql);
int num = query.executeUpdate();
System.out.println(num + "行被删除。。。");
}
// 单个属性查询
public static void simpleProperty() {
String hql = "select c.cardName from Card as c where c.cardType.cardTypeId=1";
Query query = son.createQuery(hql);
List<String> name = query.list();
for (String s : name) {
System.out.println(s);
}
}
// 多个属性查询 其中cardTypeName直接通过card对象的cardType对象获得,省去了使用普通的sql语句必须多表连接查询的麻烦
public static void mulProperty() {
String hql = "select c.cardName,c.cardType.cardTypeName,c.createDate from Card as c where c.cardType.cardTypeId=1";
Query query = son.createQuery(hql);
List<Object[]> obj = query.list();
for (Object[] o : obj) {
System.out.println(o[0] + " " + o[1] + " " + o[2]);
}
}
// 多个属性查询 面向对象方式
public static void orientedObject() {
String hql = "select new Card(c.cardName,c.createDate) from Card as c";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName() + " " + c.getCreateDate());
}
}
// 函数查询
public static void function() {
String hql = "select count(*),max(c.createDate) from Card as c";
Query query = son.createQuery(hql);
List<Object[]> oo = query.list();
for (Object[] o : oo) {
System.out.println("总记录数:" + o[0] + " 最新日期为:" + o[1]);
}
}
// 排序
public static void orderBy() {
String hql = "from Card as c order by c.createDate desc";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName() + " " + c.getCreateDate());
}
}
// 分组
public static void groupBy() {
String hql = "from Card as c group by c.cardType.cardTypeId";
Query query = son.createQuery(hql);
List<Card> cards = query.list();
for (Card c : cards) {
System.out.println(c.getCardName() + " " + c.getCreateDate());
}
}
// 单个对象查询 呵呵,奇怪吧,对象可以查询出来
public static void simpleObject() {
String hql = "select c.cardType from Card as c";
Query query = son.createQuery(hql);
query.setMaxResults(1);// 必须在查询之前指定,使其返回单个对象
CardType cardType1 = (CardType) query.uniqueResult();
System.out.println(cardType1.getCardTypeName() + " "
+ cardType1.getCreateDate());
}
// 按照命令行参数 格式为: :参数名
public static void parameter() {
String hql = "select c.cardType from Card as c where c.cardType.cardTypeId=:id";
Query query = son.createQuery(hql);
query.setParameter("id", 1);
query.setMaxResults(1);// 必须在查询之前指定,使其返回单个对象
CardType cardType = (CardType) query.uniqueResult();
System.out.println(cardType.getCardTypeName() + " "
+ cardType.getCreateDate());
}
// 按照参数位置 从0开始
public static void parameterPosition() {
String hql = "select c.cardType from Card as c where c.cardType.cardTypeId=?";
Query query = son.createQuery(hql);
query.setParameter(0, 1);
query.setMaxResults(1);// 必须在查询之前指定,使其返回单个对象
CardType cardType = (CardType) query.uniqueResult();
System.out.println(cardType.getCardTypeName() + " "
+ cardType.getCreateDate());
}
// 多个参数
public static void mulParameter() {
String hql = "from Card as c where c.cardType.cardTypeId in (3,2)";
Query query = son.createQuery(hql);
// query.setParameterList("id", new Object[]{1,2});
List<Card> cards = query.list();
for (Card o : cards) {
System.out.println(o.getCardName());
}
}
// inner join 查询结果为多个对象的集合
public static void innerJoin() {
String hql = "from Card as c inner join c.cardType";
Query query = son.createQuery(hql);
List<Object[]> cards = query.list();
for (Object[] o : cards) {
System.out.println(((Card) o[0]).getCardName() + " "
+ ((CardType) o[1]).getCreateDate());
}
}
// leftJoin 查询结果为多个对象的集合
public static void leftJoin() {
String hql = "from CardType as c left join c.cards";
Query query = son.createQuery(hql);
List<Object[]> cards = query.list();
for (Object[] o : cards) {
// 由于保存卡片时在多的一方card进行操作,使用了级联。但手动插入的cardType可能没有相应的卡片
if (o[1] != null) {// 当卡片不为空时
System.out.println(((CardType) o[0]).getCardTypeName() + " "
+ ((Card) o[1]).getCardName());
} else {
System.out.println(((CardType) o[0]).getCardTypeName()
+ " 没有相应的卡片");
}
}
}
// rightJoin 查询结果为多个对象的集合
public static void rightJoin() {
String hql = "from CardType as c right join c.cards";
Query query = son.createQuery(hql);
List<Object[]> cards = query.list();
// 插入时保证了每张卡片的类型,所以此处不用判断卡片类型是否为空
for (Object[] o : cards) {
System.out.println(((CardType) o[0]).getCardTypeName() + " "
+ ((Card) o[1]).getCardName());
}
}
// 使用子查询
public static void childSelect() {
String hql = "from CardType as c where (select count(*) from c.cards)>0";
Query query = son.createQuery(hql);
List<CardType> cards = query.list();
for (CardType c : cards) {
System.out.println(c.getCardTypeName() + " " + c.getCreateDate());
}
}
// 程序入口
public static void main(String[] args) {
// 测试方法
Transaction tr = son.beginTransaction();
// update();
mulParameter();
tr.commit();
son.close();
fac.close();
}
}
2.2 Criteria查询
1. 创建一个Criteria 实例
org.hibernate.Criteria接口表示特定持久类的一个查询。Session是 Criteria实例的工厂。
Criteria crit = sess.createCriteria(Cat.class);
crit.setMaxResults(50);
List cats = crit.list();
2. 限制结果集内容
一个单独的查询条件是org.hibernate.criterion.Criterion 接口的一个实例。
org.hibernate.criterion.Restrictions类 定义了获得某些内置Criterion类型的工厂方法。
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "Fritz%") )
.add( Restrictions.between("weight", minWeight, maxWeight) )
.list();
约束可以按逻辑分组。
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "Fritz%") )
.add( Restrictions.or(
Restrictions.eq( "age", new Integer(0) ),
Restrictions.isNull("age")
) )
.list();
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.in( "name", new String[] { "Fritz", "Izi", "Pk" } ) )
.add( Restrictions.disjunction()
.add( Restrictions.isNull("age") )
.add( Restrictions.eq("age", new Integer(0) ) )
.add( Restrictions.eq("age", new Integer(1) ) )
.add( Restrictions.eq("age", new Integer(2) ) )
) )
.list();
Hibernate提供了相当多的内置criterion类型(Restrictions 子类), 但是尤其有用的是可以允许
你直接使用SQL。
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.sql("lower({alias}.name) like lower(?)", "Fritz%",
Hibernate.STRING) )
.list();
{alias}占位符应当被替换为被查询实体的列别名。
Property实例是获得一个条件的另外一种途径。你可以通过调用Property.forName() 创建一个
Property。
Property age = Property.forName("age");
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.disjunction()
.add( age.isNull() )
.add( age.eq( new Integer(0) ) )
.add( age.eq( new Integer(1) ) )
.add( age.eq( new Integer(2) ) )
) )
.add( Property.forName("name").in( new String[] { "Fritz", "Izi", "Pk" } ) )
.list();
3. 结果集排序
你可以使用org.hibernate.criterion.Order来为查询结果排序。
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "F%")
.addOrder( Order.asc("name") )
.addOrder( Order.desc("age") )
.setMaxResults(50)
.list();
List cats = sess.createCriteria(Cat.class)
.add( Property.forName("name").like("F%") )
.addOrder( Property.forName("name").asc() )
.addOrder( Property.forName("age").desc() )
.setMaxResults(50)
.list();
4. 关联
你可以使用createCriteria()非常容易的在互相关联的实体间建立 约束。
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "F%")
.createCriteria("kittens")
.add( Restrictions.like("name", "F%")
.list();
注意第二个 createCriteria()返回一个新的 Criteria实例,该实例引用kittens 集合中的元素。
接下来,替换形态在某些情况下也是很有用的。
List cats = sess.createCriteria(Cat.class)
.createAlias("kittens", "kt")
.createAlias("mate", "mt")
.add( Restrictions.eqProperty("kt.name", "mt.name") )
.list();
(createAlias()并不创建一个新的 Criteria实例。)
Cat实例所保存的之前两次查询所返回的kittens集合是 没有被条件预过滤的。如果你希望只获得
符合条件的kittens, 你必须使用returnMaps()。
List cats = sess.createCriteria(Cat.class)
.createCriteria("kittens", "kt")
.add( Restrictions.eq("name", "F%") )
.returnMaps()
.list();
Iterator iter = cats.iterator();
while ( iter.hasNext() ) {
Map map = (Map) iter.next();
Cat cat = (Cat) map.get(Criteria.ROOT_ALIAS);
Cat kitten = (Cat) map.get("kt");
}
5. 动态关联抓取
你可以使用setFetchMode()在运行时定义动态关联抓取的语义。
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "Fritz%") )
.setFetchMode("mate", FetchMode.EAGER)
.setFetchMode("kittens", FetchMode.EAGER)
.list();
这个查询可以通过外连接抓取mate和kittens。
6. 查询示例
org.hibernate.criterion.Example类允许你通过一个给定实例 构建一个条件查询。
Cat cat = new Cat();
cat.setSex('F');
cat.setColor(Color.BLACK);
List results = session.createCriteria(Cat.class)
.add( Example.create(cat) )
.list();
版本属性、标识符和关联被忽略。默认情况下值为null的属性将被排除。
可以自行调整Example使之更实用。
Example example = Example.create(cat)
.excludeZeroes() //exclude zero valued properties
.excludeProperty("color") //exclude the property named "color"
.ignoreCase() //perform case insensitive string comparisons
.enableLike(); //use like for string comparisons
List results = session.createCriteria(Cat.class)
.add(example)
.list();
甚至可以使用examples在关联对象上放置条件。
List results = session.createCriteria(Cat.class)
.add( Example.create(cat) )
.createCriteria("mate")
.add( Example.create( cat.getMate() ) )
.list();
7. 投影(Projections)、聚合(aggregation)和分组(grouping)
org.hibernate.criterion.Projections是 Projection 的实例工厂。我们通过调用
setProjection()应用投影到一个查询。
List results = session.createCriteria(Cat.class)
.setProjection( Projections.rowCount() )
.add( Restrictions.eq("color", Color.BLACK) )
.list();
List results = session.createCriteria(Cat.class)
.setProjection( Projections.projectionList()
.add( Projections.rowCount() )
.add( Projections.avg("weight") )
.add( Projections.max("weight") )
.add( Projections.groupProperty("color") )
)
.list();
在一个条件查询中没有必要显式的使用 "group by" 。某些投影类型就是被定义为 分组投影,他
们也出现在SQL的group by子句中。
可以选择把一个别名指派给一个投影,这样可以使投影值被约束或排序所引用。下面是两种不同的
实现方式:
List results = session.createCriteria(Cat.class)
.setProjection( Projections.alias( Projections.groupProperty("color"), "colr" ) )
.addOrder( Order.asc("colr") )
.list();
List results = session.createCriteria(Cat.class)
.setProjection( Projections.groupProperty("color").as("colr") )
.addOrder( Order.asc("colr") )
.list();
alias()和as()方法简便的将一个投影实例包装到另外一个 别名的Projection实例中。简而言之,
当你添加一个投影到一个投影列表中时 你可以为它指定一个别名:
List results = session.createCriteria(Cat.class)
.setProjection( Projections.projectionList()
.add( Projections.rowCount(), "catCountByColor" )
.add( Projections.avg("weight"), "avgWeight" )
.add( Projections.max("weight"), "maxWeight" )
.add( Projections.groupProperty("color"), "color" )
)
.addOrder( Order.desc("catCountByColor") )
.addOrder( Order.desc("avgWeight") )
.list();
List results = session.createCriteria(Domestic.class, "cat")
.createAlias("kittens", "kit")
.setProjection( Projections.projectionList()
.add( Projections.property("cat.name"), "catName" )
.add( Projections.property("kit.name"), "kitName" )
)
.addOrder( Order.asc("catName") )
.addOrder( Order.asc("kitName") )
.list();
也可以使用Property.forName()来表示投影:
List results = session.createCriteria(Cat.class)
.setProjection( Property.forName("name") )
.add( Property.forName("color").eq(Color.BLACK) )
.list();
List results = session.createCriteria(Cat.class)
.setProjection( Projections.projectionList()
.add( Projections.rowCount().as("catCountByColor") )
.add( Property.forName("weight").avg().as("avgWeight") )
.add( Property.forName("weight").max().as("maxWeight") )
.add( Property.forName("color").group().as("color" )
)
.addOrder( Order.desc("catCountByColor") )
.addOrder( Order.desc("avgWeight") )
.list();
8. 离线(detached)查询和子查询
DetachedCriteria类使你在一个session范围之外创建一个查询,并且可以使用任意的 Session来
执行它。
DetachedCriteria query = DetachedCriteria.forClass(Cat.class)
.add( Property.forName("sex").eq('F') );
//创建一个Session
Session session = .;
Transaction txn = session.beginTransaction();
List results = query.getExecutableCriteria(session).setMaxResults(100).list();
txn.commit();
session.close();
DetachedCriteria也可以用以表示子查询。条件实例包含子查询可以通过 Subqueries或者
Property获得。
DetachedCriteria avgWeight = DetachedCriteria.forClass(Cat.class)
.setProjection( Property.forName("weight").avg() );
session.createCriteria(Cat.class)
.add( Property.forName("weight).gt(avgWeight) )
.list();
DetachedCriteria weights = DetachedCriteria.forClass(Cat.class)
.setProjection( Property.forName("weight") );
session.createCriteria(Cat.class)
.add( Subqueries.geAll("weight", weights) )
.list();
相互关联的子查询也是有可能的:
DetachedCriteria avgWeightForSex = DetachedCriteria.forClass(Cat.class, "cat2")
.setProjection( Property.forName("weight").avg() )
.add( Property.forName("cat2.sex").eqProperty("cat.sex") );
session.createCriteria(Cat.class, "cat")
.add( Property.forName("weight).gt(avgWeightForSex) )
.list();
补充:
criteria.add(Expression.eq("status",new Integer(status)));
criteria.add(Expression.in("status", optParm.getQueryStatus()));
2.3 SQL查询
A.获取所有的Order对象,得到一个List集合
public void list(){
String sql = "select * from orders";
NativeQuery<Order> query = session.createNativeQuery(sql, Order.class);
List<Order> list = query.getResultList();
for(Order o : list){
System.out.println(o.getId() + "::" + o.getOrderId());
}
}
B.获取Order的分页数据,得到一个List集合
/**
* 虽然为原生的SQL查询,但是依然可以使用setFirstResult()和setMaxResults()方法。从而屏蔽了
* 底层数据库的差异性。
*/
@Test
public void pageList(){
String sql = "select * from orders";
//setFirstResult()从0开始
Query<Order> query = session.createNativeQuery(sql, Order.class).setFirstResult(1).setMaxResults(4);
List<Order> list = query.getResultList();
for(Order o : list){
System.out.println(o.getId());
}
}
C.多条件查询,返回List集合(第一种形式:索引占位符)
@Test
public void multiCretiera(){
String sql = "select * from orders where create_time between ? and ? and order_id like ?";
Query<Order> query = session.createNativeQuery(sql, Order.class);
String beginDateStr = "2016-07-26 00:00:00";
String endDateStr = "2016-07-28 23:59:59";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
Date beginDate = null;
Date endDate = null;
try {
beginDate = sdf.parse(beginDateStr);
endDate = sdf.parse(endDateStr);
} catch (ParseException e) {
e.printStackTrace();
}
//分页从0开始
query.setParameter(0, beginDate).setParameter(1, endDate).setParameter(2, "%D%").setFirstResult(0).setMaxResults(1);
List<Order> list = query.getResultList();
for(Order o : list){
System.out.println(o.getOrderId() + "::" + o.getCreateTime());
}
}
D.多条件查询,返回List集合(第二种形式:命名占位符)
@Test
public void multiCretiera1(){
String sql = "select * from orders where order_id like :orderId and create_time between :beginDate and :endDate";
Query<Order> query = session.createNativeQuery(sql, Order.class);
String beginDateStr = "2016-07-26 00:00:00";
String endDateStr = "2016-07-28 23:59:59";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
Date beginDate = null;
Date endDate = null;
try {
beginDate = sdf.parse(beginDateStr);
endDate = sdf.parse(endDateStr);
} catch (ParseException e) {
e.printStackTrace();
}
query.setParameter("orderId", "%D%").setParameter("beginDate", beginDate).setParameter("endDate", endDate);
List<Order> list = query.getResultList();
for(Order o : list){
System.out.println(o.getId() + "::" + o.getOrderId());
}
}
E.大于条件的查询,使用索引占位符
@Test
public void gt(){
String sql = "select * from orders where id > ?";
Query<Order> query = session.createNativeQuery(sql, Order.class).setParameter(0, 3);
List<Order> list = query.getResultList();
for(Order o : list){
System.out.println(o.getId() + "::" + o.getOrderId());
}
}
F.删除操作
@Test
public void delete(){
String sql = "delete from orders where id in (:idList)";
Transaction tx = session.beginTransaction();
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
Query<?> query = session.createNativeQuery(sql).setParameter("idList", list);
int i = query.executeUpdate();
System.out.println(i);
tx.commit();
session.close();
}
G.获取某一列的值
@Test
public void singleValue(){
String sql = "select order_id from orders";
Query<String> query = session.createNativeQuery(sql);
List<String> list = query.getResultList();
for(String str : list){
System.out.println(str);
}
}
H.获取关联对象的结果集
@Test
public void getCustomer(){
String sql = "select c.* from orders o join customer c on o.customer_id = c.id where c.id = 8";
Query<Customer> query = session.createNativeQuery(sql, Customer.class);
List<Customer> list = query.getResultList();
for(Customer o : list){
System.out.println(o.getId() + ";;");
}
}
I.多列数据的查询
@Test
public void getObjectArray(){
String sql = "select c.name, c.phone_number, o.order_id, o.create_time from orders o join customer c on o.customer_id = c.id";
Query<Object[]> query = session.createNativeQuery(sql);
List<Object[]> list = query.getResultList();
for(Object[] o : list){
System.out.println(o[0] + ";;" + o[1] + ";;" + o[2]);
}
}
J.函数查询
@Test
public void functionQuery(){
String sql = "select max(id), count(*) from orders";
Query<Object[]> query = session.createNativeQuery(sql);
Object[] obj = query.getSingleResult();
System.out.println(obj[0] + "::" + obj[1]);
}
K.排序
@Test
public void descQuery(){
String sql = "select * from orders order by id desc";
Query<Order> query = session.createNativeQuery(sql, Order.class);
List<Order> list = query.getResultList();
for(Order o : list){
System.out.println(o.getId() + "::" + o.getOrderId());
}
}
L.右连接
@Test
public void rightJoin(){
String sql = "select c.* from orders o right join customer c on o.customer_id = c.id";
Query<Customer> query = session.createNativeQuery(sql, Customer.class);
List<Customer> list = query.getResultList();
for(Customer c : list){
System.out.println(c.getId());
}
}
三、 持久化对象
transient(瞬时态):尚未与Session关联对象,失去引用的话,就会被JVM回收。一般就是直接New创建的对象。
persistent(持久态):已经与当前session产生关联,并且相关联的session没有关闭,并且事务尚未提交。
detached(脱管态):存在持久化OID,但没有与当前session关联,脱管状态改变hibernate不能检测到。

Session session = HibernateUtils.openSession();
// 开启事务
Transaction transaction = session.beginTransaction();
Book book = new Book(); // 瞬时态(没有OID,未与Session关联)
book.setName("hibernate精通");
book.setPrice(56d);
session.save(book);// 持久态(具有OID,与Session关联)
// 提交事务,关闭Session
transaction.commit();
session.close();
System.out.println(book.getId()); // 脱管态(具有 OID,与Session断开关联)
四、hibernate一级缓存
 hibernate向一级缓存放入数据时,同时保存快照数据,当修改一级缓存的时候,在flush操作时,对比缓存和快照,如果不一致,自动更新。
hibernate向一级缓存放入数据时,同时保存快照数据,当修改一级缓存的时候,在flush操作时,对比缓存和快照,如果不一致,自动更新。
一级缓存的管理:
4.1.flush 修改一级缓存数据,针对内存操作,需要在session执行flush操作时,将缓存变化同步在数据库,而只有在缓存数据与快照区不一致的时候,才会生成update语句。
@Test
public void fun7() {
// 通过工具类获取session值
Session session = HibernateUtils.getSession();
// 启动事务操作
session.beginTransaction();
// session.setFlushMode(FlushMode.MANUAL);
// 通过ID从数据库中获取值,此时会产生快照
Book book1 = (Book) session.get(Book.class, 1);
// 修改属性值
book1.setName("struts璇﹁В");
// 手动flush,刷新缓存到数据库,此时只是生成SQL语句,但是数据库中并没有发生变化,只有commit后,数据库才会发生相应的变化。
session.flush();
// 手动提交事务
session.getTransaction().commit();
// 关闭session的资源
session.close();
}
4.2.clear 清处所有对象的一级缓存,对对象所做的修改,全部都没有了,跟当初的快照一样。
public void fun7() {
// 通过工具类获取session值
Session session = HibernateUtils.getSession();
// 启动事务操作
session.beginTransaction();
// session.setFlushMode(FlushMode.MANUAL);
// 通过ID从数据库中获取值,此时会产生快照
Book book1 = (Book) session.get(Book.class, 1);
// 修改属性值
book1.setName("struts璇﹁В");
//清除一级缓存操作,此时当作事务提交的时候,数据库中并没有发生任何的变化
session.clear();
// 手动提交事务
session.getTransaction().commit();
// 关闭session的资源
session.close();
}
4.3.evict 清除一级缓存指定对象
@Test
public void fun5() {
Session session = HibernateUtils.getSession();
session.beginTransaction();
//当执行一次操作后,会把对象放置到Session缓存中
Book book1 = (Book) session.get(Book.class, 1);
Book book2 = (Book) session.get(Book.class, 2);
session.evict(book2); // 从缓存中清楚book2对象所做的修改
// 当再次执行操作时,book2还会发出SQL语句操作
Book book11 = (Book) session.get(Book.class, 1);
Book book22 = (Book) session.get(Book.class, 2);
// 手动提交事务
session.getTransaction().commit();
// 关闭资源
session.close();
}
4.4.refresh 重新查询数据库,更新快照和一级缓存
@Test
public void fun6() {
Session session = HibernateUtils.getSession();
session.beginTransaction();
// 从数据库中查询book,并放置到Session缓存中一份
Book book1 = (Book) session.get(Book.class, 1);
//修改缓存对象的值
book1.setName("spring璇﹁В");
//又进行了一次查询操作,此时把快照中的数据与数据库一致
session.refresh(book1);
System.out.println(book1);
// 4.鎻愪氦
session.getTransaction().commit();
// 5.閲婃斁璧勬簮
session.close();
}
4.5.Session手动控制缓存
在hibernate中也为 我们提供了手动控制缓存的机制,具体如下
Always:每次查询时,session都会flush;
Auto:有些查询时,session会默认flush,例如commit。session.flush;
Commit:在事务提交的时候;
Manual:只有手动调用sessionflush才会刷出;
public void fun7() {
// 通过工具类获取session值
Session session = HibernateUtils.getSession();
// 启动事务操作
session.beginTransaction();
session.setFlushMode(FlushMode.MANUAL);
// 通过ID从数据库中获取值,此时会产生快照
Book book1 = (Book) session.get(Book.class, 1);
// 修改属性值
book1.setName("struts璇﹁В");
//因为上面开启了,手动提交缓存,所以只有手动提交,才能同步到数据库操作
session.flush();
// 手动提交事务
session.getTransaction().commit();
// 关闭session的资源
session.close();
}
五、hibernate二级缓存
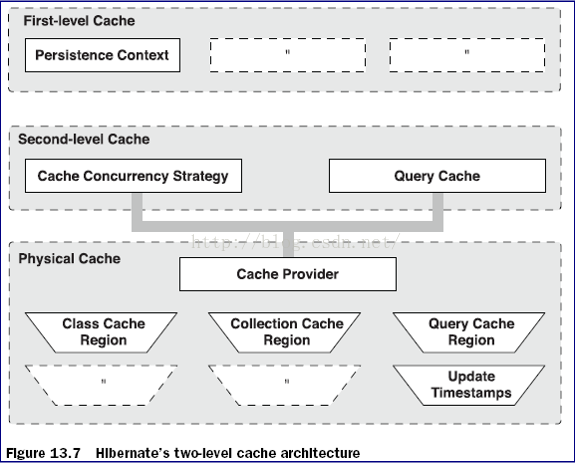
* 二级缓存也分为了两种
内置缓存:Hibernate自带的,不可卸载,通常在Hibernate的初始化阶段,Hibernate会把映射元数据和预定义的SQL语句放置到SessionFactory的缓存中。该内置缓存是只读的。
外置缓存:通常说的二级缓存也就是外置缓存,在默认情况下SessionFactory不会启用这个缓存插件,外置缓存中的数据是数据库数据的复制,外置缓存的物理介质可以是内存或者硬盘。
* 并发访问策略
|
transactional (事务型) |
仅在受管理的环境中适用 提供Repeatable Read事务隔离级别 适用经常被读,很少修改的数据 可以防止脏读和不可重复读的并发问题 缓存支持事务,发生异常的时候,缓存也能够回滚 |
|
read-write (读写型) |
提供Read Committed事务隔离级别 在非集群的环境中适用 适用经常被读,很少修改的数据 可以防止脏读 更新缓存的时候会锁定缓存中的数据 |
|
nonstrict-read-write (非严格读写型) |
适用极少被修改,偶尔允许脏读的数据(两个事务同时修改数据的情况很少见) 不保证缓存和数据库中数据的一致性 为缓存数据设置很短的过期时间,从而尽量避免脏读 不锁定缓存中的数据 |
|
read-only (只读型) |
适用从来不会被修改的数据(如参考数据) 在此模式下,如果对数据进行更新操作,会有异常 事务隔离级别低,并发性能高 在集群环境中也能完美运作 |
分析:通过上述表格分析如下:适合放入二级缓存中数据,很少被修改,不是很重要的数据,允许出现偶尔的并发问题,不适合放入二级缓存中的数据,经常被修改,财务数据,绝对不允许出现并发问题,与其他应用数据共享的数据。
* 二级缓存的配置
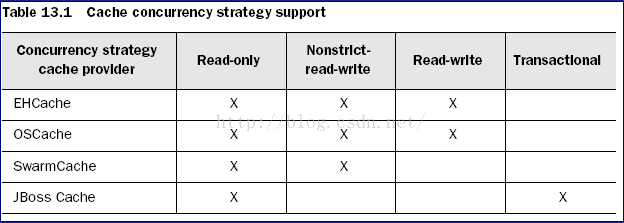
1.hibernate支持的缓存插件
•EHCache: 可作为进程范围内的缓存,存放数据的物理介质可以是内存或硬盘,对Hibernate的查询缓存提供了支持
•OpenSymphony`:可作为进程范围内的缓存,存放数据的物理介质可以是内存或硬盘,提供了丰富的缓存数据过期策略,对Hibernate的查询缓存提供了支持
•SwarmCache:可作为集群范围内的缓存,但不支持Hibernate的查询缓存
•JBossCache:可作为集群范围内的缓存,支持Hibernate的查询缓存
四种缓存插件支持的并发范围策略如下图
2.二级缓存使用
2.1 拷贝jar包 如要第三方的jar包ehcache-1.5.0.jar,并且依赖于依赖backport-util-concurrent 和 commons-logging
2.2 在hibernate.cfg.xml中开启二级缓存<propertyname="hibernate.cache.use_second_level_cache">true</property>
2.3 配置二级缓存技术提供商<propertyname="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
2.4 配置缓存数据对象并发策略
在hbm文件中配置:
<class name="cn.itcast.domain.Customer" table="customers" catalog="hibernate3day4" >
<!-- 类级别缓存 -->
<cache usage="read-write"/>
<set name="orders" cascade="all-delete-orphan" inverse="true" >
<!-- 关联集合级别缓存 -->
<cache usage="read-write"/>
</set>
</class>
在cgf文件中配置:
<!-- 类级别缓存 -->
<class-cache usage="read-write" class="cn.itcast.domain.Customer"/>
<class-cache usage="read-write" class="cn.itcast.domain.Order"/>
<!-- 集合缓存 -->
<collection-cache usage="read-write" collection="cn.itcast.domain.Customer.orders"/>
2.5 添加二级缓存配置文件
在src中配置ehcache.xml,将ehcache.jar包中的ehcache-failsafe.xml 改名 ehcache.xml 放入 src
ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<diskStore path="java.io.tmpdir"/> 配置二级缓存硬盘临时目录位置
<defaultCache
maxElementsInMemory="10000" // 内存中最大对象数量 ,超过数量,数据会被缓存到硬盘
eternal="false"
timeToIdleSeconds="120" // 是否缓存为永久性 false 不永久
timeToLiveSeconds="120" // 存活时间,对象不管是否使用,到了时间回收
overflowToDisk="true" // 是否可以缓存到硬盘
maxElementsOnDisk="10000000" // 硬盘缓存最大对象数量
// 当jvm结束时是否持久化对象 true false 默认是false
diskExpiryThreadIntervalSeconds="120" // 指定专门用于清除过期对象的监听线程的轮询时间
memoryStoreEvictionPolicy="LRU"
/>
</ehcache>
2.6 测试
@Test
public void fun1() {
Session s1 = HibernateUtils.getSession();
s1.beginTransaction();
Customer c1 = (Customer) s1.get(Customer.class, 1); // 从数据库中加载数据
System.out.println(c1.getName());//此时才会发出SQL语句
s1.getTransaction().commit();
s1.close(); // 关闭session级别的一级缓存
Session s2 = HibernateUtils.getSession();
s2.beginTransaction();
Customer c2 = (Customer) s2.get(Customer.class, 1); // 因为有了二级缓存的存在,直接从二级缓存中取出即可
System.out.println(c2.getName());
Customer c3 = (Customer) s2.get(Customer.class, 1); //从二级缓存中取出
System.out.println(c3.getName());
s2.getTransaction().commit();
s2.close();
}