一、mysql架构
mysql是一个单进程多线程架构的数据库。
二、存储引擎
InnoDB:
- 支持事务
- 行锁
- 读操作无锁
- 4种隔离级别,默认为repeatable
- 自适应hash索引
- 每张表的存储都是按主键的顺序记性存放
- 支持全文索引(InnoDB1.2.x - mysql5.6)
- 支持MVCC(多版本并发控制)实现高并发
MyISAM:
- 不支持事务
- 表锁
- 支持全文索引
三、InnoDB体系架构
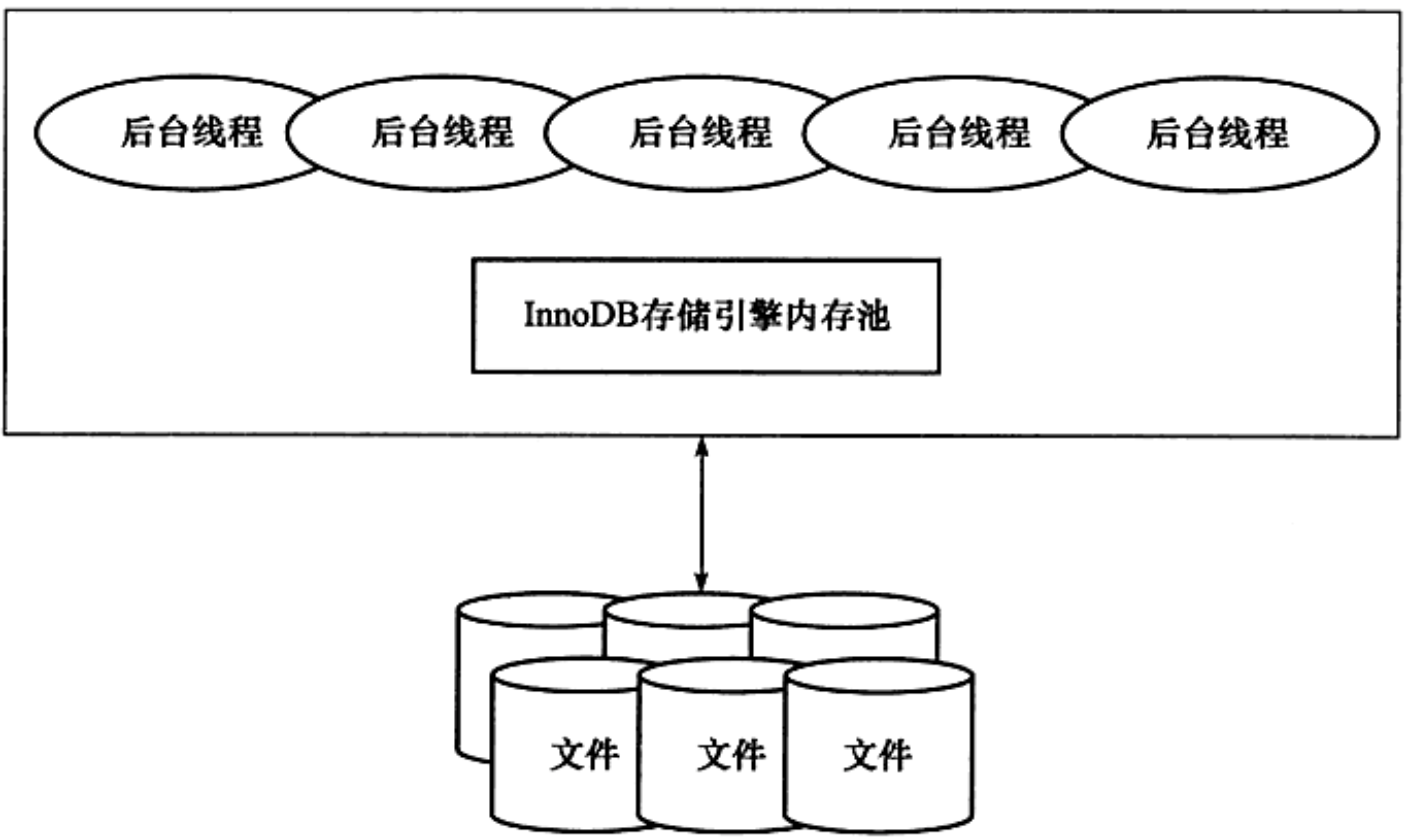
1、后台线程
- Master Thread
- 负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性
- IO Thread
- 负责IO请求的回调处理
- Purge Thread
- 回收已经使用并分配的undo页(事务提交后,其所使用的undolog不再需要)
2、内存池
- 缓冲池(一块内存区域)
- InnoDB基于磁盘存储,将记录按照页的方式进行管理(由于基于磁盘,速度较慢,所以需要引入缓冲池提高性能)
- 读取页:先从缓冲池获取,缓冲池没有,才会从磁盘获取
- 修改页:先写重做日志缓冲,再修改缓冲池中的页,然后以一定的频率刷新到磁盘(Checkpoint机制),在还没有刷新到磁盘之前,该页被称为脏页
- innodb_buffer_pool_size设置大小
- 存放对象:索引页、数据页、自适应hash索引和lock信息
- 缓冲池可以配置多个(innodb_buffer_pool_instances),每个页根据hash值平均分配到不同的缓冲池实例中,用于减少数据库内部资源竞争
- LRU List
- 将最新的页放在队列前端,最近最少使用的放在尾端,当缓冲池不够用时,将尾端的页删除出缓冲池(如果此页是脏页,会先刷新到磁盘)。innodb采用的是midpoint技术进行LRU,具体参看《MySQL技术内幕 InnoDB存储引擎》
- Flush List
- 脏页列表
- 重做日志redolog缓冲
- 为了防止脏页在刷新到磁盘时宕机,必须先redolog,再修改页;
- 数据库发生宕机时,通过redolog完成数据的恢复(ACID-D持久性)
- 默认大小8M,通过innodb_log_buffer_size
- 将redolog缓冲刷新到redolog文件中的时机
- master会将redolog缓冲每隔1s刷新到redolog文件中
- 每个事物提交
- redolog缓冲池剩余空间小于1/2
- Checkpoint
- 缓冲池不够用时,将脏页刷新到磁盘
- 数据库宕机时,只需要重做Checkpoint之后的日志,缩短数据库的恢复时间
- redolog不可用时,将脏页刷新到磁盘
四、InnoDB逻辑存储结构
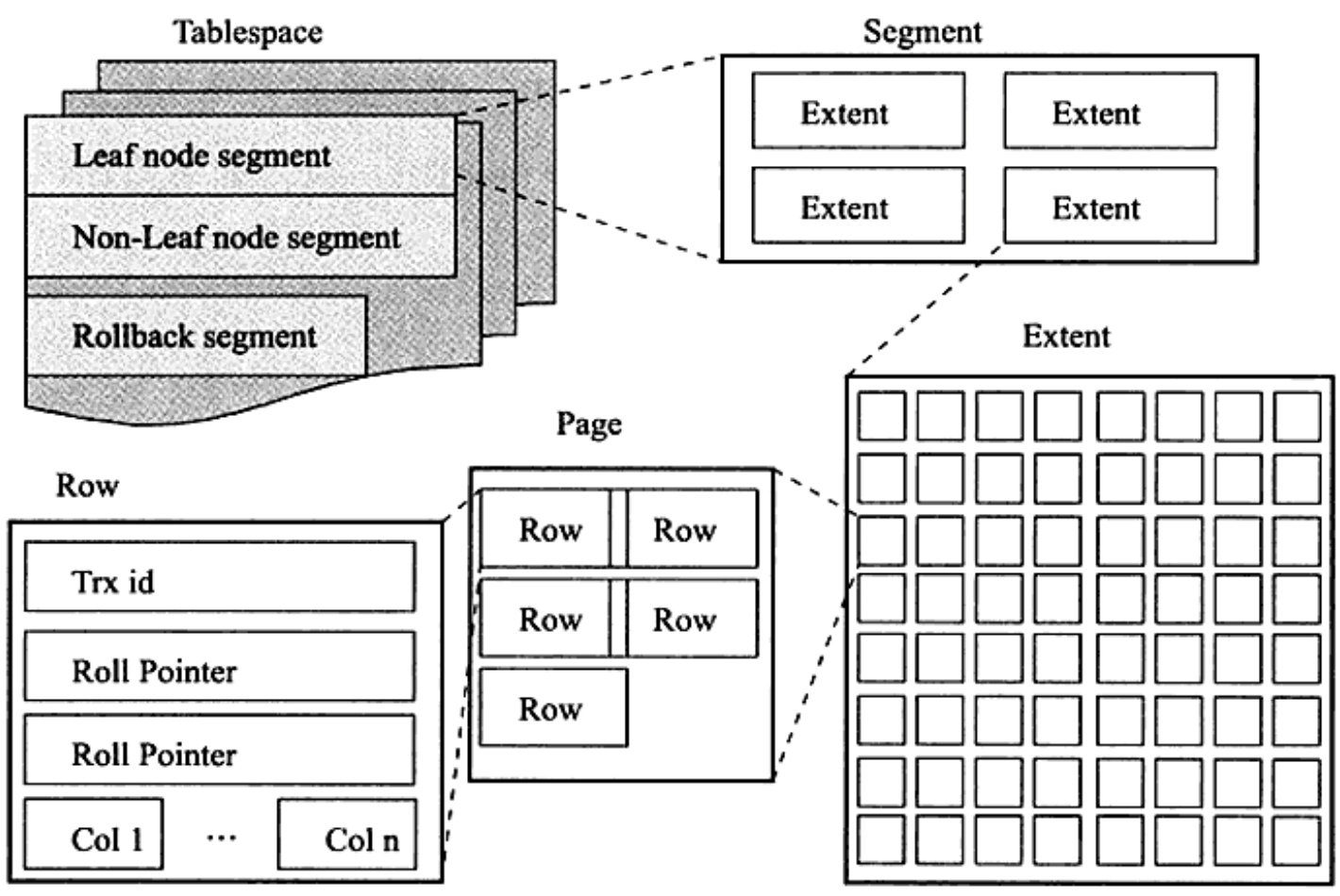
1、表空间
- 默认情况下,只有一个表空间ibdata1,所有数据存放在这个空间内
- 如果启用了innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内
- 每个表空间只存放数据、索引和InsertBuffer Bitmap页,其他数据还在ibdata1中
2、Segment段(InnoDB引擎自己控制)
- 数据段:B+ tree的叶子节点
- 索引段:B+ tree的非叶子节点
- 回滚段
3、Extent区
- 每个区的大小为1M,页大小为16KB,即一个区一共有64个连续的页(区的大小不可调节,页可以)
4、Page页
- InnoDB磁盘管理的最小单位
- 默认每个页大小为16KB,可以通过innodb_page_size来设置(4/8/16K)
- 每个页最多存放7992行数据
5、Row行
五、索引
1、hash索引
- 定位数据只需要一次查找,O(1)
- 自适应hash索引:InnoDB会监控对表上各个索引页的查询,如果观察到建立hash索引可以带来速度提升,则建立hash索引(即InnoDB会自动的根据访问频率和模式来自动的为某些热点页建立hash索引)
- 默认是开启的
- 只可用于等值查询,不可用于范围查询
2、B+树索引
- 树的高度一般为2~4层,需要2~4次查询(100w和1000w行数据,如果B+ tree都是3层,那么查询效率是一样的)
- B+树索引能查到的是数据行所在的页
- 包含聚集索引和辅助索引
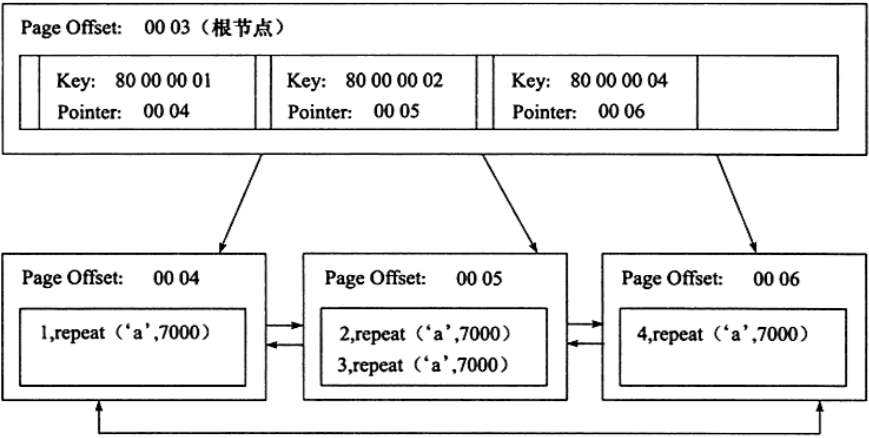
3、聚集索引
- 即主键索引
- 叶子节点存放的是行记录数据所在的页,而页中的每一行都是完整的行(叶子节点也被称为数据页)
- 针对范围查询也比较快
聚集索引图:
其中,根节点部分的Key:80000001代表主键为1;Pointer:0004代表指向数据页的页号(即第4页);
数据页节点的的PageOffset:0004代表第4页,其中存储的数据是完整的每一行。
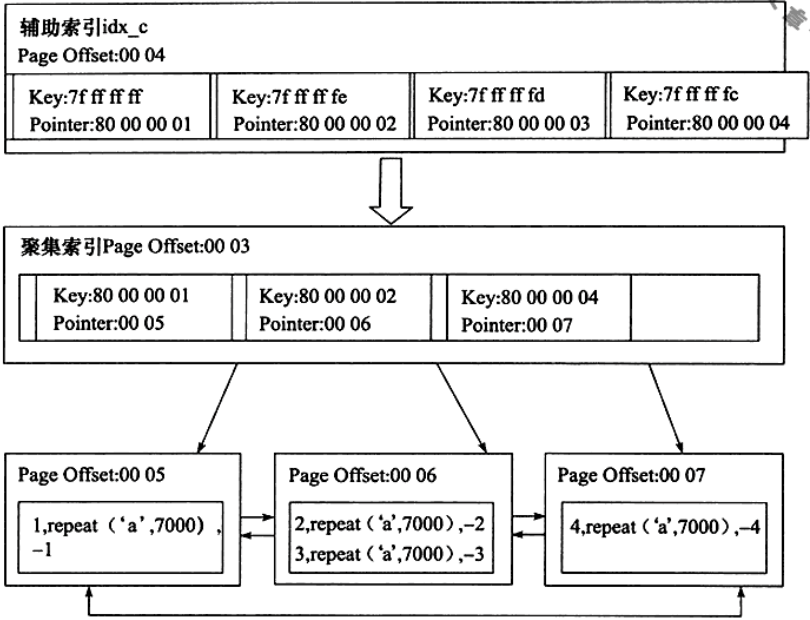
4、辅助索引
- 叶子节点存放的也是行记录数据所在的页,但还是页中存放的不是完整的行,而是仅仅是一对key-value和一个指针,该指针指向相应行数据的聚集索引的主键
- 假设辅助索引树高3层,聚集索引树为3层,那么根据辅助索引查找数据,需要先经过3次IO找到主键,再经过3次IO找到行做在的数据页
- 针对辅助索引的插入和更新操作:辅助索引页如果在缓冲池中,则插入;若不在,则点放到InsertBuffer对象中,之后在以一定的平率进行InsertBuffer和辅助索引页子节点的合并
辅助索引图:
其中,idx_c表示对第c列做了索引;idx_c中的Key:7fffffff代表c列的一个值,其实是-1;idx_c中的Pointer:80000001代表该行的主键是80000001,即1;下面的就是聚集索引部分。
5、联合索引(多列索引)
- 左边匹配原则(如果索引为(a,b),则where a=x可以用到索引,但是b=x用不到,如果是覆盖索引有可能会用到)
6、覆盖索引
- 从辅助索引中直接获取记录
- 对于统计操作,例如count(1),有可能联合索引,右边也会匹配(优化器自己会做),因为count(1)操作不需要获取整行的详细数据,所以不需要去聚集索引的叶子节点去获取数据,直接在辅助索引树中就完成了操作
- select username from xxx where username='lisi',如果username是辅助索引,那么整个查询在辅助索引树上就可以完成,因为辅助索引树上虽然没有保存完整的行,但是保存着<username,lisi>这个key-value对;如果select username, age from xxx where username='lisi',那么就要走聚集索引了
六、锁
1、latch
- 保证并发线程操作临界资源的正确性
- 自旋锁,自旋指定的次数后,若还没获取到锁,则进入等待状态,等待被唤醒
2、lock
- 事务锁,锁定的可能是表、页或行
- 释放点:事务commit或rollback
- 两种标准的行级锁
- 共享锁:S lock,事务T1获取了r行的S锁,事务T2也可以获取r行的S锁
- 排他锁:X lock,事务T1获取了r行的S锁,事务T2就不能获取r行的X锁;事务T1获取了r行的X锁,事务T2就不能获取r行的X/S锁
七、事务
1、隔离级别
- 读不提交
- 读并且提交
- 可避免脏读:一个事务读到另一个事务没有提交的数据,如果另一个事务发生回滚,第一个事务读到的数据就是垃圾数据
- 可重复读
- 会有幻读,InnoDB通过Next-Key Lock解决了
- 幻读:指两次执行同一条 select 语句会出现不同的结果,第二次读会增加一数据行,并没有说这两次执行是在同一个事务中。使用表锁即可避免。
- 可避免不可重复读:在同一个事务中两条一模一样的 select 语句的执行结果的比较。如果前后执行的结果一样,则是可重复读;如果前后的结果可以不一样,则是不可重复读。通常是发生了update。增加读取时的共享锁(禁止修改)即可避免。
- 默认的事务隔离级别
- 会有幻读,InnoDB通过Next-Key Lock解决了
- 序列化
这里有美团的一篇文章,非常好:http://tech.meituan.com/mysql-index.html
补充:摘自:https://tech.meituan.com/mysql-index.html
一、B+树结构:

二、从B+树查找数据流程

三、B+树性质
