安装 hadoop 伪分布式 参看 http://blog.csdn.net/liuc0317/article/details/8613586
写这篇blog 是见解 http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html 的例子
接下来我们开始学习hadoop 为给我们提供的 wordcount 的例子。
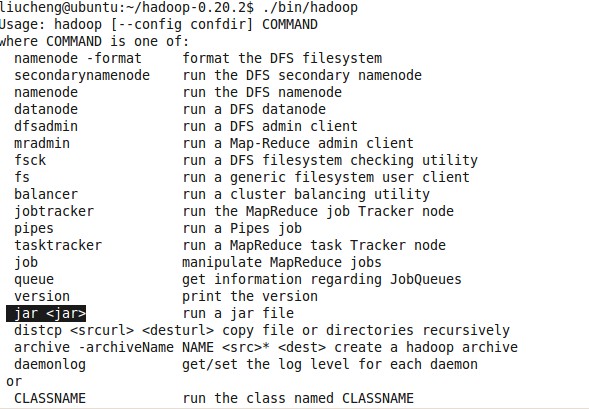
第一步:查看一下 hadoop给我们提供了哪些命令,和哪些例子。
进入hadoop 的目录下, cd hadoop 0.20.2
然后运行 ./bin/hadoop 见图h-jar.jpg
有一个 -jar 的命令
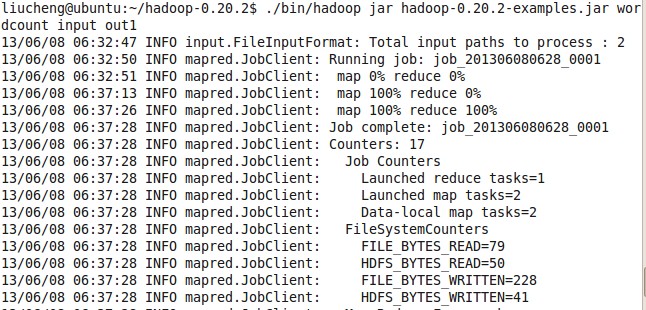
再接着运行 ./bin/hadoop jar hadoop-0.20.2-examples.jar 见图h-wordcount

第二步:我们按示例的要求提供一个输入的input 和一个输出的output
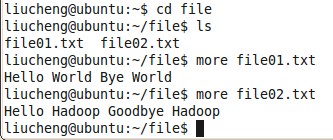
首先:在当前用户下创建一个file文件夹 mkdir file
进行 file 文件夹 创建两个文件 file01.txt 和file02.txt
cd file,touch file01.txt,touch file02.txt
可以使用gedit 可是 vi 给他们添上内容。 见图hfile.jpg
./bin/hadoop fs -mkdir input
第四步:把file文件夹下的两个文件上传到 新建的input文件夹下,并且显示input下的文件。
./bin/hadoop fs -put ~/file/file*.txt input
./bin/hadoop fs -ls input
见hinput.jpg

./bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output
解释一下这个命令 ./bin/hadoop jar 运行一个jar 的命令 示例为 hadoop-0.20.2-examples.jar 名字叫 wordcount 输入文件夹是input 输出是 output文件夹
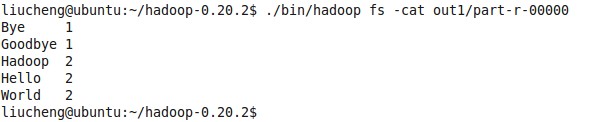
看一下运行的最后结果: