Redis中使用跳表作为有序集合键(zset)的底层实现之一。当有序集合元素较多时,或有序集合中元素为较长字符串时,都会使用跳表作为底层结构。
Redis在两个地方用到了跳表,一种是有序集合键中,另一种是集群节点中做内部数据结构。
跳表
下面的结构是就是跳表:
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。
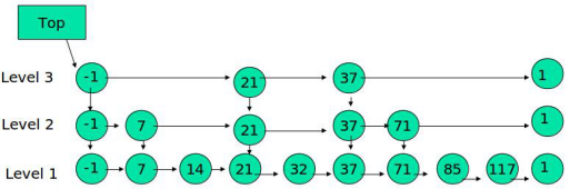
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素 越接近顶层的链表,含有的节点则越少 (一般是做为索引层)
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含4个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。一个指向上面一层的元素,一个指向同一链表中的上一个元素
package com.high_structure;
import java.util.Random;
public class MySkipList<K extends Comparable<K>, V> {
// 该类应该的有的属性 size head节点
private int size;
private Node<K, V> head;
// 因为我们会通过随机数概率的方式去生成是否生成索引层
private final Random random = new Random();
//
private final double DEFAULT_PROBABILITY = 0.5;
public MySkipList() {
super();
this.size = 0;
this.head = new Node<K, V>(null, null, 0);
}
// 提供几个基本方法 方便后期去操作链表 1 判断是否为空 2水平插入到某个元素的后面 3 垂直插入(上下关联)
public boolean isEmpty() {
return size == 0;
}
/**
* 吧b插入到a的后面<br>
* a->c->d <br>
* b
*
* @param a
* @param b
*/
public void horizontalLink(Node<K, V> a, Node<K, V> b) {
b.setPre(a);
b.setNext(a.getNext());
if (a.getNext() != null) // 建立从右到左的链接关系
{
// 在这里a.getnext == b。getnext的
a.getNext().setPre(b);
}
a.setNext(b);
}
/**
* 吧b插入到a下面
*
* @param a
* @param b
*/
public void vertLink(Node<K, V> a, Node<K, V> b) {
a.setDown(b);
b.setUp(a);
}
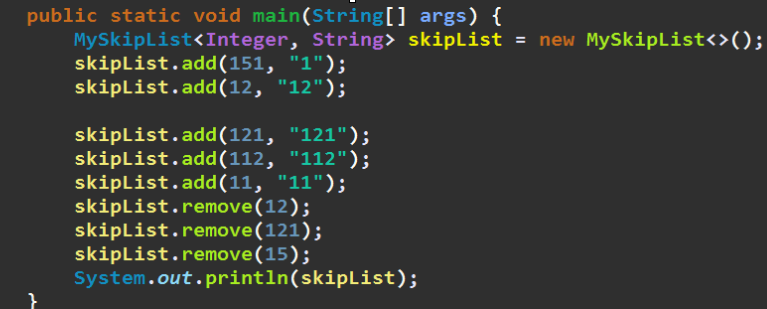
public static void main(String[] args) {
MySkipList<Integer, String> skipList = new MySkipList<>();
skipList.add(151, "1");
skipList.add(12, "12");
skipList.add(121, "121");
skipList.add(112, "112");
skipList.add(11, "11");
skipList.remove(12);
skipList.remove(121);
skipList.remove(15);
System.out.println(skipList);
}
/**
* 判断key1是否小于key2
*
* @param key1
* @param key2
* @return
*/
public boolean lessthanOrEquals(K key1, K key2) {
return key1.compareTo(key2) <= 0;
}
public Node<K, V> get(K key) {
// 省略key的判断
Node<K, V> node = searchNode(key);
if (node.getKey().equals(key)) {
return node;
}
return null;
}
/**
* 通过指定的key查找元素
*
* @param key
* @return
*/
public Node<K, V> searchNode(K key) {
// 该node表示最后返回的节点
Node<K, V> node = head;
// 该节点表示遍历会用到的节点
Node<K, V> next = null;
Node<K, V> down = null;
// 先在从head开始查找
while (true) {
next = node.getNext();
// 先遍历第一层节点
while (next != null && lessthanOrEquals(next.getKey(), key))
// 如果不为空 并且遍历的节点<=当前节点
{
node = next;
next = next.getNext();
}
if (node.getKey() != null && node.getKey().compareTo(key) == 0) {
break;
}
// 如果不相等 进入下一层级
down = node.getDown();
if (down == null) // 最后一层
{
break;
} else {
node = down;
}
}
return node;
}
/**
* 添加元素 如果 key存在 就修改该node的value 如果不存在 就添加到他应该的位置
*
* @param node
*/
public void add(K key, V val) {
// 省略判断key是否合法
Node<K, V> node = searchNode(key);
K searchKey = node.getKey();
if (searchKey != null && searchKey.compareTo(key) == 0) {
node.setValue(val);
return;
}
// 如果不相等 那么我们就把我们的节点插入到该节点的后面
Node<K, V> newNode = new Node<K, V>(key, val, node.getLevel());
horizontalLink(node, newNode);
// 通过随机函数的的方式看是否需要生成索引层 【如果查找的数和我们 的head在同一层在同一级就需要生成 】
int headLevel = head.getLevel();
int currentLevel = node.getLevel();
while (isNeedBuildLevel()) {
if (currentLevel >= headLevel) { // 需要创建的心的索引层头结点
Node<K, V> newHead = new Node<K, V>(null, null, ++headLevel);
vertLink(newHead, head);
head = newHead;
}
// 结合跳表的图更好理解
// 如果当前节点(node)的up为空 我们就跳转到当前节点的head节点 然后 获取up
// 如果不为空直接获取up 然后在up后面添加当前节点作为索引层
while (node.getUp() == null) {
node = node.getPre();
}
node = node.getUp();
Node<K, V> newTemp = new Node<K, V>(key, val, node.getLevel());
horizontalLink(node, newTemp);
vertLink(newTemp, newNode);
//因为我们生成索引层是随机的 有可能在生成了一个索引层以后又会生成一个
//比如 现在有2层
// leav1 0--> 1
// ||
// leav0 0--> 1 假如又生成一个新的索引层 我们其实是需要记录上一次索引层的位置 也就是 tmp的值 我们把他保存在newNode 下次使用
newNode = newTemp;
currentLevel++;
}
size++;
}
/**
*
* 删除的核心思路 先找到该节点 然后走到最下面 从下面开始删除 (从上往下删除 )
*
* @param key
*/
public void remove(K key) {
// 省略判断key是否合法
Node<K, V> node = searchNode(key);
// 删除
if (node != null && node.getKey().equals(key)) {
while (node.getDown() != null) {
node = node.getDown();
}
Node<K, V> next = null;
Node<K, V> pre = null;
while (node != null) {
pre = node.getPre();
next = node.getNext();
if (pre != null) {
pre.setNext(next);
}
if (next != null) {
next.setPre(pre);
}
node = node.getUp();
}
// 对顶层链表进行调整,去除无效的顶层链表 某些时候可能存在某一行索引就一个单独的头结点 该头结点的next没有值
while (head.getNext() == null && head.getDown() != null) {
head = head.getDown();
head.setUp(null);
}
}
size--;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Node<K, V> node = head;
// 移动到最底层
while (node.getDown() != null)
node = node.getDown();
while (node.getPre() != null)
node = node.getPre();
// 第一个节点是头部节点,没有任何意义,所以需要移动到后一个节点
if (node.getNext() != null)
node = node.getNext();
// 遍历
while (node != null) {
sb.append(node.toString()).append("
");
node = node.getNext();
}
return sb.toString();
}
private boolean isNeedBuildLevel() {
return random.nextDouble() < DEFAULT_PROBABILITY;
}
// 节点类型 采用内部类的方式
static class Node<K, V> {
private K key;
private V value;
// 还需要一个值来保存该节点所在的层级
private int level;
public int getLevel() {
return level;
}
public void setLevel(int level) {
this.level = level;
}
private Node<K, V> up, down, next, pre;
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
public Node<K, V> getUp() {
return up;
}
public void setUp(Node<K, V> up) {
this.up = up;
}
public Node<K, V> getDown() {
return down;
}
public void setDown(Node<K, V> down) {
this.down = down;
}
public Node<K, V> getNext() {
return next;
}
public void setNext(Node<K, V> next) {
this.next = next;
}
public Node<K, V> getPre() {
return pre;
}
public void setPre(Node<K, V> pre) {
this.pre = pre;
}
public Node(K key, V value, int level) {
super();
this.key = key;
this.value = value;
this.level = level;
}
public Node() {
}
@Override
public String toString() {
return "Node [key=" + key + ", value=" + value + "]";
}
}
}
最后的测试结果如下