参考:
官网:
https://kudu.apache.org/docs/index.html
原理:
https://blog.csdn.net/nosqlnotes/article/details/79496002
emr:
https://help.aliyun.com/document_detail/141545.html?spm=5176.11065259.1996646101.searchclickresult.27c24992KolFqY&aly_as=pGRW1f3f
大叔:
https://www.cnblogs.com/barneywill/p/10296475.html GG加深
1/ 部署
大叔:
https://www.cnblogs.com/barneywill/p/10296475.html
yum安装kudu master和kudu server
2/ 原理:
在介绍Kudu是什么之前,还是先简单的说一下现存系统针对结构化数据存储与查询的一些痛点问题,结构化数据的存储,通常包含如下两种方式:
静态数据通常以Parquet/Carbon/Avro形式直接存放在HDFS中,对于分析场景,这种存储通常是更加适合的。但无论以哪种方式存在于HDFS中,都难以支持单条记录级别的更新,随机读取也并不高效。
可变数据的存储通常选择HBase或者Cassandra,因为它们能够支持记录级别的高效随机读写。但这种存储却并不适合离线分析场景,因为它们在大批量数据获取时的性能较差(针对HBase而言,有两方面的主要原因:一是HFile本身的结构定义,它是按行组织数据的,这种格式针对大多数的分析场景,都会带来较大的IO消耗,因为可能会读取很多不必要的数据,相对而言Parquet格式针对分析场景就做了很多优化。 二是由于HBase本身的LSM-Tree架构决定的,HBase的读取路径中,不仅要考虑内存中的数据,同时要考虑HDFS中的一个或多个HFile,较之于直接从HDFS中读取文件而言,这种读取路径是过长的)。
可以看出,如上两种存储方式,都存在明显的优缺点:
直接存放于HDFS中,适合离线分析,却不利于记录级别的随机读写。
直接将数据存放于HBase/Cassandra中,适合记录级别的随机读写,对离线分析却不友好。
可以看出,如上两种存储方式,都存在明显的优缺点:
直接存放于HDFS中,适合离线分析,却不利于记录级别的随机读写。
直接将数据存放于HBase/Cassandra中,适合记录级别的随机读写,对离线分析却不友好。
但在很多实际业务场景中,两种场景时常是并存的。我们的通常做法有如下几种:
-数据存放于HBase中,对于分析任务,基于Spark/Hive On HBase进行,性能较差。
-对于分析性能要求较高的,可以将数据在HDFS/Hive中多冗余存放一份,或者,将HBase中的数据定期的导出成Parquet/Carbon格式的数据。 明显这种方案对业务应用提出了较高的要求,而且容易导致在线数据与离线数据之间的一致性问题。
Kudu的设计,就是试图在OLAP与OLTP之间,寻求一个最佳的结合点,从而在一个系统的一份数据中,既能支持OLTP型实时读写能力又能支持OLAP型分析。另外一个初衷,在Cloudera发布的《Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data》一文中有提及,Kudu作为一个新的分布式存储系统期望有效提升CPU的使用率,而低CPU使用率恰是HBase/Cassandra等系统的最大问题.
补充:
大数据存储:
静态数据:以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是数据无法进行随机的读写。
动态数据:以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。这类存储的局限性是批量读取吞吐量远不如 HDFS,不适用于批量数据分析的场景。
HDFS,使用列式存储格式Apache Parquet,Apache ORC,适合离线分析,不支持单条记录级别的update操作,随机读写性能差。这个就不多说了,用过HDFS的同学应该都知道这个特点.
HBase,可以进行高效随机读写,却并不适用于基于SQL的数据分析方向,大批量数据获取时的性能较差。
但在真实的场景中,边界可能没有那么清晰,面对既需要随机读写,又需要批量分析的大数据场景.
kudu它不及HDFS批处理快,也不及HBase随机读写能力强,但是反过来它比HBase批处理快(适用于OLAP的分析场景),而且比HDFS随机读写能力强(适用于实时写入或者更新的场景)
Kudu的架构:
Kudu也采用了Master-Slave形式的中心节点架构,
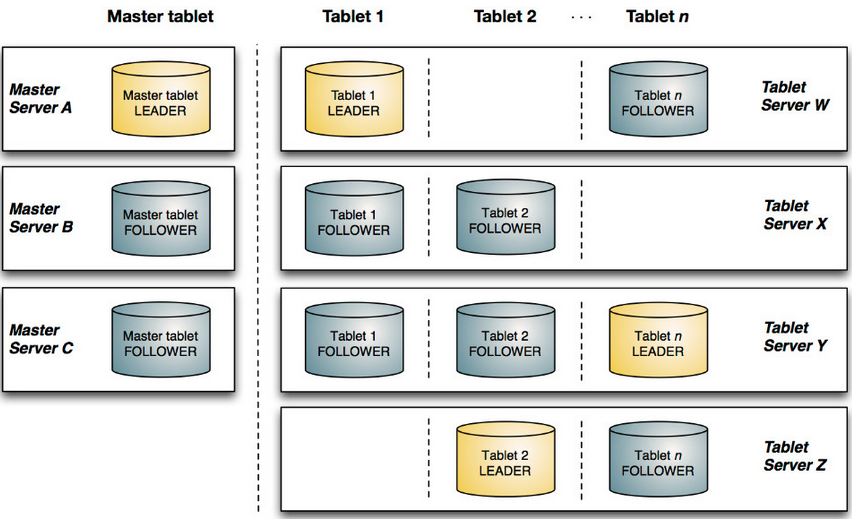
管理节点被称作Kudu Master,Master Server负责管理元数据,这些元数据包括Tablet Server的服务器的信息以及Tablet的信息,Master Server通过Raft协议提供高可用性.
1.用来存放一些表的Schema信息,且负责处理建表等请求。
2.跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
3.存放Tablet到Tablet Server的部署信息。
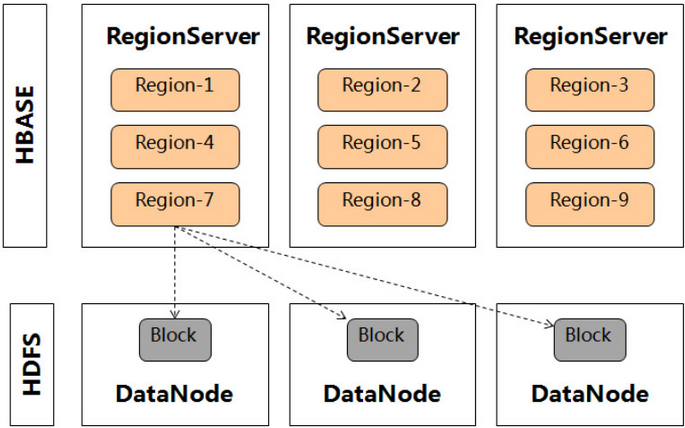
数据节点被称作Tablet Server(可对比理解HBase中的RegionServer角色)。
一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Range Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
一个Tablet可以被部署到了多个Tablet Server中。在HBase最初的架构中,一个Region只能被部署在一个RegionServer中,它的数据多副本交由HDFS来保障。从1.0版本开始,HBase有了Region Replica(HBASE-10070)特性,该特性允许将一个Region部署在多个RegionServer中来提升读取的可用性,但多Region副本之间的数据却不是实时同步的。
kudu的多副本机制
hbase的多副本机制
概念
Table
A table is where your data is stored in Kudu. A table has a schema and a totally ordered primary key. A table is split into segments called tablets.
Table(类似于hive或hbase的table),有schema和primary key,可以划分为多个Tablet;
Tablet
A tablet is a contiguous segment of a table, similar to a partition in other data storage engines or relational databases. A given tablet is replicated on multiple tablet servers, and at any given point in time, one of these replicas is considered the leader tablet. Any replica can service reads, and writes require consensus among the set of tablet servers serving the tablet.
Tablet(类似于hive中的partition或hbase中的region),tablet是多副本的,存放在多个tablet server上,多个副本中有一个是leader tablet;所有的副本都可以读,但是写操作只有leader可以,写操作利用一致性算法(Raft);
Tablet Server
A tablet server stores and serves tablets to clients. For a given tablet, one tablet server acts as a leader, and the others act as follower replicas of that tablet. Only leaders service write requests, while leaders or followers each service read requests. Leaders are elected using Raft Consensus Algorithm. One tablet server can serve multiple tablets, and one tablet can be served by multiple tablet servers.
tablet server(类似于hbase中的region server),存放tablet并且响应client请求;一个tablet server存放多个tablet;
Catalog Table
The catalog table is the central location for metadata of Kudu. It stores information about tables and tablets. The catalog table may not be read or written directly. Instead, it is accessible only via metadata operations exposed in the client API.
The catalog table stores two categories of metadata: Tables & Tablets
catalog table存放kudu的metadata(类似于hive和hbase中的metadata),catalog table包含两类metadata:Tables和Tablets
Master
The master keeps track of all the tablets, tablet servers, the Catalog Table, and other metadata related to the cluster. At a given point in time, there can only be one acting master (the leader). If the current leader disappears, a new master is elected using Raft Consensus Algorithm.
The master also coordinates metadata operations for clients. For example, when creating a new table, the client internally sends the request to the master. The master writes the metadata for the new table into the catalog table, and coordinates the process of creating tablets on the tablet servers.
All the master’s data is stored in a tablet, which can be replicated to all the other candidate masters.
Tablet servers heartbeat to the master at a set interval (the default is once per second).
master(类似于hdfs和hbase的master),负责管理所有的tablet、tablet server、catalog table以及其他元数据。同一时间集群中只有一个acting master(leader master),如果leader master挂了,一个新的master会通过Raft算法选举出来。
所有的master数据都存放在一个tablet中,这个tablet会被复制到所有的candidate master上;
tablet server会定期向master发送心跳。
Raft Consensus Algorithm
Kudu uses the Raft consensus algorithm as a means to guarantee fault-tolerance and consistency, both for regular tablets and for master data. Through Raft, multiple replicas of a tablet elect a leader, which is responsible for accepting and replicating writes to follower replicas. Once a write is persisted in a majority of replicas it is acknowledged to the client. A given group of N replicas (usually 3 or 5) is able to accept writes with at most (N - 1)/2 faulty replicas.
kudu通过Raft一致性算法(类似于zookeeper中的Paxos算法)来保证tablet和master数据的容错性和一致性。详见:https://raft.github.io/
Logical Replication
Kudu replicates operations, not on-disk data. This is referred to as logical replication, as opposed to physical replication.
kudu使用的是逻辑副本的概念。
Impala集成
Impala集成Kudu不需要做特别的配置,可以在Impala配置文件中设置kudu_master_hosts= [master1][:port],[master2][:port],[master3][:port];或者在SQL中通过TBLPROPERTIES语句指定kudu.master_addresses来指定Kudu集群。下面示例展示的是在SQL语句中添加kudu.master_addresses来指定Kudu的地址
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES(
'kudu.master_addresses' = 'master1:7051,master2:7051,master3:7051');
常用命令
kudu -h
检查集群健康
kudu cluster ksck <master_addresses> #查看集群基本信息
kudu的副本数量是在表上设置,可以通过这个命令查看:
kudu cluster ksck 10.52.5.227

一般默认是3,副本数量只能在创建表时指定,创建后不能修改,并且副本数量必须为奇数。
By default, Kudu tables created through Impala use a tablet replication factor of 3. To specify the replication factor for a Kudu table, add a TBLPROPERTIES clause to the CREATE TABLE statement as shown below where n is the replication factor you want to use:
TBLPROPERTIES ('kudu.num_tablet_replicas' = 'n')
A replication factor must be an odd number.
Changing the kudu.num_tablet_replicas table property using ALTER TABLE currently has no effect.
注:由于最小化安装(1个master,2个Tablet Servers),又由于kudu的副本数只能为奇数,所以我们的副本只能指定为1.
#查看集群中的master
kudu master list $masterip
查看master状态或flag
kudu master status localhost
kudu master get_flags localhost
tserver:
#查看集群中的tserver
kudu tserver list $masterip
查看tserver状态或flag
kudu tserver status localhost
kudu tserver get_flags localhost
检查集群Metrics
kudu-tserver --dump_metrics_json
kudu-master --dump_metrics_json
获取tables
kudu table list <master_addresses>
Dump出cfile文件内容
kudu fs dump cfile <block_id>
Dump出kudu文件系统的tree
kudu fs dump tree [-fs_wal_dir=<dir>] [-fs_data_dirs=<dirs>]
kudu使用方法
(1)可通过Java client、C++ client、Python client操作kudu表,但要构建client并编写应用程序;
(2)可通过kudu-spark包集成kudu与spark,并编写spark应用程序来操作kudu表;
(3)可通过impala的shell对kudu表进行交互式的操作,因为impala2.8及以上的版本已经集成了对kudu的操作。下面主要讲述基于impala的使用方法。
https://blog.csdn.net/cdxxx5708/article/details/79074489
常用的是java代码里通过jdbc连impala使用kudu,或用impala-shell
impala-shell进入交互式命令行:
可创建外部表,内部表,分区等
java操作kudu:
https://www.cnblogs.com/starzy/p/10573508.html
实际建表例子:
CREATE TABLE `data_order` (
`id` bigint,
`create_time` bigint,
`user_id` bigint,
`start_name` string,
`start_lng` double,
`start_lat` double,
`end_name` string,
`end_lng` double,
`end_lat` double,
`duration` double,
`distance` bigint,
`basic_fare` double,
`dst_fare` double,
`dut_fare` double,
`dut_price` double,
`dst_price` double,
`price` double,
`reward` double,
`driver_id` bigint,
`plate_num` string,
`take_time` bigint,
`wait_time` bigint,
`pickup_time` bigint,
`arrive_time` bigint,
`finish_time` bigint,
`cancel_role` int,
`cancel_time` bigint,
`cancel_type` int,
`status` int,
`fraud` tinyint,
`driver_serv_type` int,
`serv_type` int,
`abnormal` tinyint,
`zone_hash` string,
`updated_at` string,
`city_id` bigint,
`pax_num` int,
`tip` double,
`trip_id` bigint,
`wait_carpool` tinyint,
`estimate_duration` bigint,
`estimate_distance` bigint,
`estimate_price` double,
`pay_mode` int,
PRIMARY KEY (`id`,create_time)
)
PARTITION BY HASH (id) PARTITIONS 2,
RANGE (create_time)
(
PARTITION 1580774400 <= VALUES < 1580860800,
PARTITION 1580860800 <= VALUES < 1580947200,
PARTITION 1580947200 <= VALUES < 1581033600
) STORED AS KUDU
TBLPROPERTIES(
'kudu.master_addresses' = '10.52.5.227:7051,10.52.5.228:7051,10.52.5.229:7051',
'kudu.num_tablet_replicas' = '1')
;
新方案:
最后采用开源的采集插件,通过kudu的api建表,再在impala-shell做impala表的映射:
CREATE EXTERNAL TABLE oride_data.data_order
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = '10.52.5.227:7051',
'kudu.table_name' = 'impala::oride_data.data_order' #映射
);
转自:https://www.cnblogs.com/hongfeng2019/p/12132855.html