背景
Javashop电商系统的商品索引是使用的elasticsearch,对于高可用的要求有两个重要的考量:
1、集群化
2、可扩容
3、冗灾
冗灾就要实现es的持久化,要考虑到es宕机的情况,当es因不可抗因素挂掉了,当我们再恢复了es的运行后,商品索引也要随之 一起恢复。
本文着重讨论elasticsearch的持久化部署方案,当然提供在方案也支持了集群及扩容。
思路
1、数据的存储
在k8s中的持久化部署不可避免的要用到持久卷,我们采用nfs方式的持久卷来存储es数据。
持久卷的详细介绍请见这里:
2、节点规划
默认启动5个节点,3主2数据。
根据es官方推荐每个节点的智能要分离,因此maseter节点不存储数据,只用来协调。
3、多节点的权限问题
es的数据目录默认只允许一个节点访问,但在k8s上采用了持久卷,所有节点的数据都存储在这个卷上,这会导致es的访问权限问题。
报错如下:
java.io.IOException: failed to obtain lock on /usr/share/elasticsearch/data/nodes/0",
当然可以通过更改es的配置max_local_storage_nodes来允许多个节点访问同一个数据目录,但es官方不推荐这样做。
所以我们的方案是更改每个节点的数据存储目录来解决
ps:指定es配置项path.data来实现
举例说明:
| 节点名 | 存储目录 |
| es-data-1 | /usr/share/elasticsearch/data/es-data-1 |
| es-data-2 | /usr/share/elasticsearch/data/es-data-2 |
部署过程
一、pv(持久卷的建立)
先要建立nfs服务器
对于持久卷的结构规划如下:
| 目录 | 内容 |
|---|---|
| /nfs/data/esmaster | es master节点的数据 |
| /nfs/data/esdata | es 数据节点的数据 |
关于索引的磁盘占用:
请根据业务的数据量情况来规划持久卷硬件的情况
根据我们实际测算1000个商品大约需要1MB/每节点
默认情况
在默认的规划中,我们使用使用k8s的master节点作为nfs服务器,为上述卷准备了10G的空间,请确保k8s master node 不少于10G的空闲磁盘。
请根据您的具体业务情况选择nfs服务器,如果条件允许最好是独立的nfs服务器。
根据如上规划建立nfs服务:
#master节点安装nfs yum -y install nfs-utils #创建nfs目录 mkdir -p /nfs/data/{mqdata,esmaster,esdata} #修改权限 chmod -R 777 /nfs/data/ #编辑export文件 vim /etc/exports 粘贴如下内容: /nfs/data/esmaster *(rw,no_root_squash,sync) /nfs/data/esdata *(rw,no_root_squash,sync) #配置生效 exportfs -r #查看生效 exportfs #启动rpcbind、nfs服务 systemctl restart rpcbind && systemctl enable rpcbind systemctl restart nfs && systemctl enable nfs #查看 RPC 服务的注册状况 rpcinfo -p localhost #showmount测试,这里的ip输入master节点的局域网ip showmount -e <your ip>
如果成功可以看到可被挂载的目录:
# showmount -e 172.17.14.73 Export list for 172.17.14.73: /nfs/data/esmaster * /nfs/data/mqdata *
接下来,要在每一个节点上安装nfs服务以便使k8s可以挂载nfs目录
#所有node节点安装客户端 yum -y install nfs-utils systemctl start nfs && systemctl enable nfs
这样就为k8s的持久卷做好了准备。
建立持久卷
有了nfs的准备,我就可以建立持久卷了:
我们分享了javashop内部使用的yaml仓库供大家参考:
https://gitee.com/enation/elasticsearch-on-k8s
在您的k8s maseter节点服务器上 clone我们准备好的yaml文件
git clone https://gitee.com/enation/elasticsearch-on-k8s.git
修改yaml目录中的pv.yaml
修改其中的server配置为nfs服务器的IP:
nfs:
server: 192.168.1.100 #这里请写nfs服务器的ip
在k8s master节点上执行下面的命令创建namespace:
kubectl create namespace ns-elasticsearch
通过下面的命令建立持久卷:
kubectl create -f pv.yaml
通过以下命令查看持久卷是否建立成功:
kubectl get pv
部署elasticsearch
执行下面的命令创建es集群
kubectl create -f elasticsearch.yaml
通过以上部署我们建立了一个ns-elasticsearch的namespace,并在其中创建了相应的pvc、角色账号,有状态副本集以及服务。
有状态副本集:
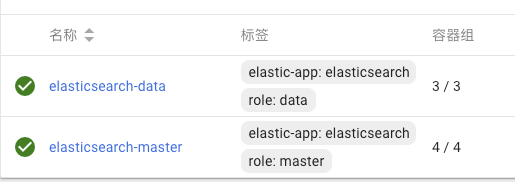
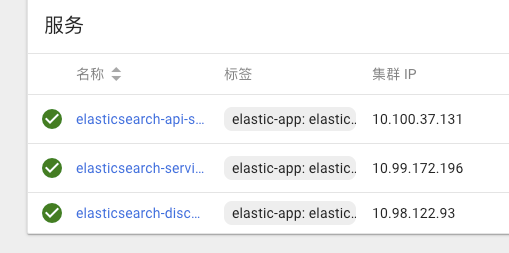
服务:
镜像
使用的是javashop自己基于es:6做的,加入了ik分词插件,其他没有变化。
服务
我们默认开启了对外nodeport端口,对应关系:
32000->9200
32100->9300
k8s内部可以通过下面的服务名称访问:
elasticsearch-api-service.ns-elasticsearch:9300
elasticsearch-service.ns-elasticsearch:9200
等待容器都启动成功后验证。
验证
1、生成索引
2、删除副本集:
kubectl delete -f elasticsearch.yaml
3、建立副本集
kubectl create -f elasticsearch.yaml
4、查看之前的索引是否恢复
关键技术点
1、集群发现:
- name: "discovery.zen.ping.unicast.hosts" value: "elasticsearch-discovery"
建立了elasticsearch-discovery服务
2、映射持久卷
映射到:/usr/share/elasticsearch/data/
3、自定义数据目录
- name: "path.data" value: "/usr/share/elasticsearch/data/$(MY_POD_NAME)"
其中MY_POD_NAME是读取的容器名称,通过有状态副本集保证唯一性的绑定:
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
欢迎关注Javashop技术分享公众号,观看更多的视频讲解:
