最近在写一下简单的爬虫,然后使用webClient.getPage的时候,一请求就直接挂掉,很长时间没有反应,让人很头疼,然后去掉js,返回的又是一些看不懂的:
获取列表页的文章列表:
https://blog.csdn.net/qq_38366063/article/list/1
正确的应该是:

这是获取列表页返回错误的:
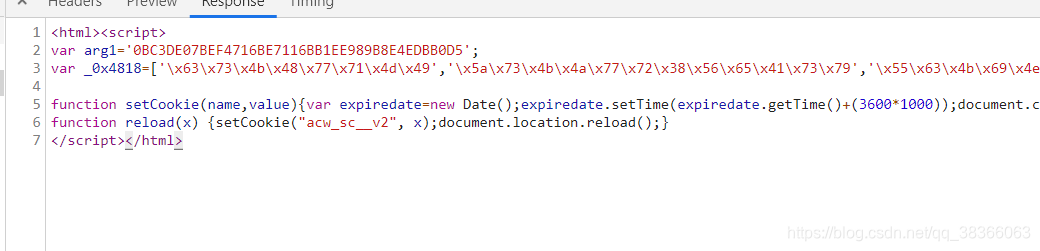
<html><script>
var arg1='0BC3DE07BEF4716BE7116BB1EE989B8E4EDBB0D5';
var _0x4818=['x63x73x4bx48x77x71x4dx49','x5ax73x4bx4ax77x72x38x56x65x41x73x79','x55x63x4bx69x4ex38x4fx2fx77x70x6cx77x4dx41x3dx3d','x4ax52x38x43x54x67x3dx3d','x59x73x4fx6ex62x53x45x51x77x37x6fx7ax77x71x5ax4bx65x73x4bx55x77x37x6bx77x58x38x4fx52x49x51x3dx3d','x77x37x6fx56x53x38x4fx53x77x6fx50x43x6cx33x6...
function reload(x) {setCookie("acw_sc__v2", x);document.location.reload();}
</script></html>
然后就很烦,然后想了想,要是直接get请求返回流将流转字符串转dom对象是不是就可以了,然后试了一下,真可以,美滋滋,解决了爬虫最关键问题:
public static InputStream doGet(String urlstr, Map<String, String> headers) throws IOException {
URL url = new URL(urlstr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 " +
"(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36");
conn.setRequestProperty("accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp," +
"image/apng,*/*;q=0" +
".8");
if (headers != null) {
Set<String> keys = headers.keySet();
for (String key : keys) {
conn.setRequestProperty(key, headers.get(key));
}
}
Random random = new Random();
String ip =
(random.nextInt(100) + 100) + "." + (random.nextInt(100) + 100) + "." + (random.nextInt(100) + 100) + "." + (random.nextInt(100) + 100);
conn.setRequestProperty("x-forwarded-for", ip);
InputStream inputStream = conn.getInputStream();
return inputStream;
}
返回的InputStream直接转String,然后直接Jsoup解析即可:
public static String inputStreamToString(InputStream is, String charset) throws IOException {
byte[] bytes = new byte[1024];
int byteLength = 0;
StringBuffer sb = new StringBuffer();
while ((byteLength = is.read(bytes)) != -1) {
sb.append(new String(bytes, 0, byteLength, charset));
}
return sb.toString();
}

还是有问题,有的页面可以直接流的方式直接写,有的不行,不知道什么原因=-=.
博客的详情页面就不行…
csdn有验证token,打开控制台,找到对应token,加上去就好了,token一般更新时间为半个小时…否则会被屏蔽…
,csdn爬取,加上token即可,自己通过webClient.getPage,就可以获取.,或者直接通过httpRequest,直接get请求也是可以的…记得传token即可.