1.分布式流处理的基本模型
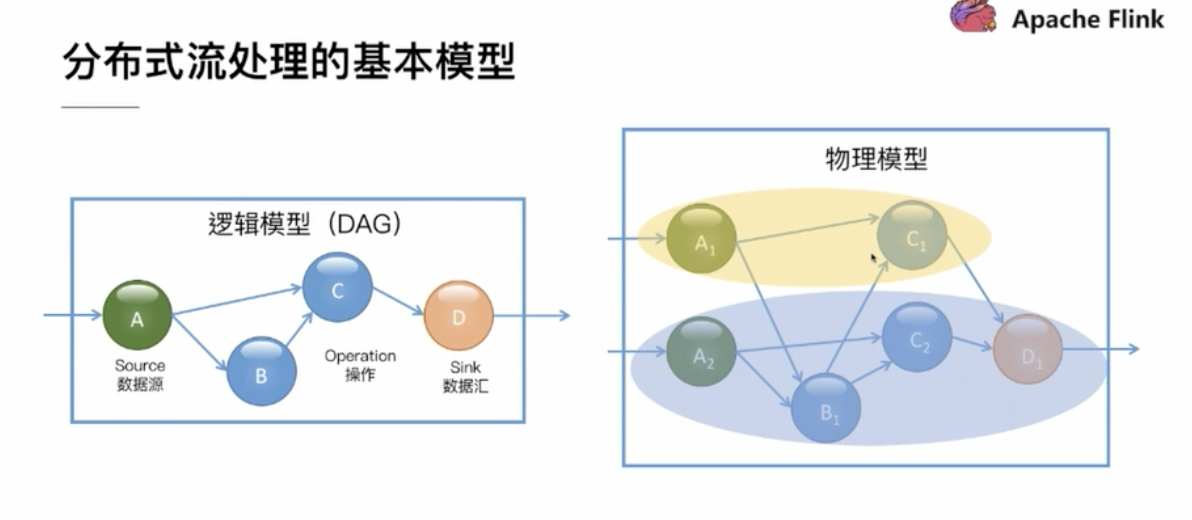
逻辑模型:
一个source 一个operation 一个sink
物理模型:
多个source对应多个operation一个sink
不同节点直接的数据传输需要接触到网络
2.流的基本操作
单条流的操作:
map
两条流的操作:
connect:connectedstream,把两条不同数据类型的流合并到一条流中
comap:把这条流又返回给单条流
拆分流的操作:
split:splitstream
datastream的基本转换:

keyedstream的理解:
会把不同类别的数据发送到不同的节点上执行
key数>>并发度
datastream:
物理分组:
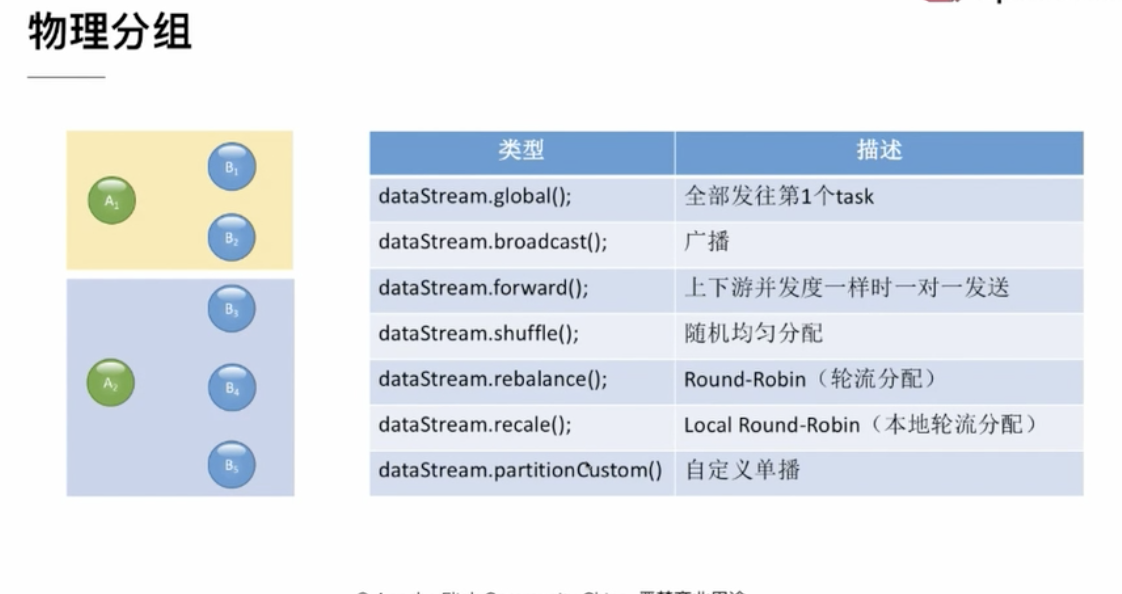
globa:把所有的数据流都放入到第一个task中
broadcast:广播,会把某个节点上的数据流广播到所有的节点上去
forward:上下游并发度一样时一对一发送,如果上下游的并发度不同会在构建执行图的时候报错,
如果上下游并发度一致会自动启用forward
shuffle:随机分配,从当前实例中随机挑选几个放入到下一个实例中
rebalance:类似shuffle,是为了负载均衡随机分配
recale:本地轮流分配,只会看到自己本机的实例,轮流进行分流
partitioncusotm:自定义数据单播,可以自己定义从本机中选择一条数据流发送到下游,但是下游只能是一个实例
类型系统:
flink序列化是强类型的,这是为了提升序列化和反序化的速率
基本类型:javaj的基本类型,还有void,string,date,bigdecimal,biginteger
复合类型:tuple,和scala case class,row,pojo
tuple有数据条数上限,不支持null
row支持null,没有数据条数上限
辅助、集合类型:option,either,list,map等
其他类型:
自定义typeinfomation或kryo处理,一般不推荐使用,最好不要使用泛型,因为有类型擦出
fold:可以允许前后的值不一致
reduce:需要提供一个一致的初始值
keyby如果遇到数据倾斜的解决方案:localgruopby
在keyby之后,在某个节点上会分配到了比较大的key,会在单节点上启动多个线程,类型于一个先聚合在分组
可以提前对key值进行打散,然后在进行统计
richfunction
每个函数都有自己的一个声明周期,open,close
在最后的时候在做一些清理的工作
流和多个动态维表的join:
首先需要自己控制数据流和动态维表的join,可以在key join的时候,尽量减少join的中间的结果
在join的算子中,根据key值手动的去多个维表中拉取数据,然后关联