一、概念简介
二进制数:计算机底层都是通过二进制进行传输和存储的,用bit表示,简称b;
字 节:在信息系统中,我们通常将八个二进制数作为一个字节,字节是信息传输中最小单位,用byte表示,简称B,1byte=8bit;
字 符:类字形单位或符号,包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号;
字 符 集:顾名思义字符的集合,经过历史的演变,字符集经历了ASCII字符集、GB2312字符集、GBK字符集、Unicode字符集等等;
编 码:字符集是字符的集合,只维护着符号对应着字符的关系,需要通过编码转换成字节(二进制)进行传输、存储;每种字符集有相对应的编码方式;
二、字符集详解
1)ASCII字符集
这个大家应该都很熟悉,在纯英文的环境中,只需要128个字符就可以描述所有信息,即一个字节,其中8位二进制的最高位为0,空置不用。

2)GBK字符集
随着信息网络的发展,每个国家都有自己的字符集,用1个或多个字节表示一个字符。中文字符集也经历了GB2312 -> GBK -> GB18030,他们都兼容了ASCII字符集。
3)Unicode字符集
由于不同国家有自己的一套字符集,如果需要读取其他国家的文件,需要装载对应的环境,这极大增加了沟通的流畅性及成本。介于此,就有了统一的字符集Unicode,世界上所有的字符都汇集在unicode字符集中,每个字符都有独一无二的code与之对应。在简介时,也说到每个字符集都有自己的编码方式,对于ASCII字符集、GBK字符集他们的编码方式就是ASCII,GBK编码。但是对于unicode字符集有utf-8、utf-16、utf-32编码,后面我们会重点介绍utf-8编码。
三、编码详解
我们先来看下一段代码
package com.xuhui;
import java.io.UnsupportedEncodingException;
/**
* Created by xuhui on 2019/10/11
*/
public class EncodeOperation {
public static void main(String[] args) throws UnsupportedEncodingException {
String str1 = "a";
printEncode(str1);
String str2 = "国";
printEncode(str2);
}
public static void printEncode(String str) throws UnsupportedEncodingException {
System.out.println("str = " + str);
ASCII(str);
GBK(str);
UNICODE(str);
UTF8(str);
UTF16(str);
UTF32(str);
System.out.println("-------------------------------------------");
}
public static void ASCII(String str) throws UnsupportedEncodingException {
byte[] bytes = str.getBytes("ASCII");
printHex("ASCII", bytes);
}
public static void GBK(String str) throws UnsupportedEncodingException {
byte[] bytes = str.getBytes("GBK");
printHex("GBK", bytes);
}
public static void UNICODE(String str) throws UnsupportedEncodingException {
byte[] bytes = str.getBytes("UNICODE");
printHex("UNICODE", bytes);
}
public static void UTF8(String str) throws UnsupportedEncodingException {
byte[] bytes = str.getBytes("UTF8");
printHex("UTF8", bytes);
}
public static void UTF16(String str) throws UnsupportedEncodingException {
byte[] bytes = str.getBytes("UTF16");
printHex("UTF16", bytes);
}
public static void UTF32(String str) throws UnsupportedEncodingException {
byte[] bytes = str.getBytes("UTF32");
printHex("UTF32", bytes);
}
public static void printHex(String head, byte[] bytes) {
if (bytes.length <= 0) {
return;
}
StringBuilder sb = new StringBuilder();
for (byte b : bytes) {
sb.append(Integer.toHexString(b & 0xff));
}
System.out.println(head + " -> " + sb.toString());
}
}
输出结果
str = a
ASCII -> 61
GBK -> 61
UNICODE -> feff061
UTF8 -> 61
UTF16 -> feff061
UTF32 -> 00061
-------------------------------------------
str = 国
ASCII -> 3f
GBK -> b9fa
UNICODE -> feff56fd
UTF8 -> e59bbd
UTF16 -> feff56fd
UTF32 -> 0056fd
-------------------------------------------
很多人看完输出结果可能已经明白了一切。
1)常见的字符集都兼容ASCII字符集,也就是说,当为ASCII中的字符时,所有编码的最后一个字节与ASCII编码的字节一致;
2)现在大家都知道了unicode可以表示所有的字符,那么直接用UNICODE编码大家都不用争了,也不会出现乱码问题,但是UNICODE编码是固定4个字节,我们也看到了当输入字符为'a'时,也是4个字节。那么当存储纯英文字符串时,所需的空间是ASCII的四倍,这肯定是不能接受的。于是就有了UTF-8,UTF-16,UTF-32编码;
3)UTF-8编码为可变长编码格式,一个字符用1~4个字节存储;UTF-16编码用2~4个字节;UTF-32用4个字节;
4)字符的存储还存在字节序问题,大端:高字节在前,低字节在后;小端:低字节在前,高字节在后;这里就不详细阐述了,之后会单独介绍字节序。eg:如果字符的编码格式为0xabcd,若存储结果为ab cd则成为大端存储,若存储结果为cd ab则为小端存储;
四、UTF-8编码详解
我们以最为常用的UTF-8编码演示中文字符存储:'国'如何变成0xe59bbd字节存储。
1)unicode与utf-8的关系
utf-8编码是unicode字符集的其中一种编码格式。每个字符在unicode字符集中都对应中唯一的一个数字,用4个字节(8位16进制)表示。由于utf-8编码的字节是可变的,对于英文字符1个字节存储,中文一般由3个字节存储;但如何区分,哪几个字节属于这个字符。于是就有了以下的规则:
对于单字节的符号,字节的第一位置0,后面7位为这个符号的Unicode码。因此,对于英语字母,UTF-8编码和ASCII码是相同的。
对于n个字节的字符(n>1),第一个字节的前n位都置为1,第n+1位置为0,后面字节的前两位一律置为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
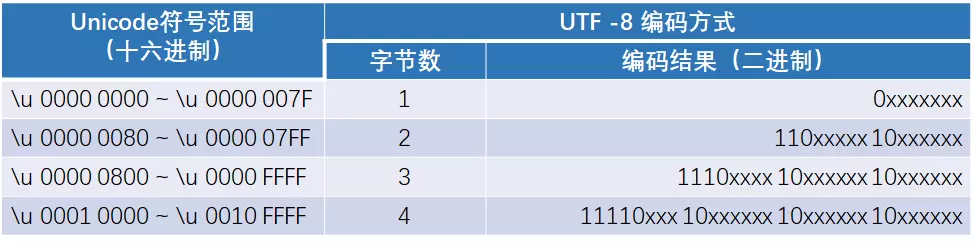
2)演变
字符 国
unicode符号 u56fd
二进制 0101011011111101
UTF-8编码 11100101 10011011 10111101
转换成16进制 e5 9b bd