三者都可以进行数据合并和拼接,但具体连接方式不同:
1、merge
2、join
3、concat

一、merge
默认是根据列标题进行合并
1、在一个字段上的连接
import numpy as np from pandas import Series, DataFrame dframe1 = DataFrame({'key':['X','Z','Y','Z','X','X'],'value_df1': np.arange(6)}) dframe1 >> key value_df1 0 X 0 1 Z 1 2 Y 2 3 Z 3 4 X 4 5 X 5 dframe2 = DataFrame({'key':['Q','Y','Z'],'value_df2':[1,2,3]}) dframe2 >> key value_df2 0 Q 1 1 Y 2 2 Z 3
1)内连接(交集)
# 默认选取两个数据共有的字段进行连接 # 默认是内连接(即交集) pd.merge(dframe1,dframe2) # 功能同上 pd.merge(dframe1,dframe2, on='key', how='inner') # on='key'指定合并的字段;how='inner'指定连接方式为内连接 >>
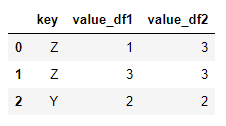
选取‘key’列数据取交集后,另外两列的数据组合连接成一行:
比如上数据,df1中Z有两行数据(1, 3),df2中Z有一行数据(3),最后将(1-3, 3-3)连接生成2行数据,得到以上的数据结果。
因为df1和df2中Y都只有一行,所以最终连接后也只有一行数据。
2)外连接(全连接、并集)
# on='key'可以省略,但最好不要省略 # how='outer'指定外连接 pd.merge(dframe1,dframe2,on='key',how='outer') >>
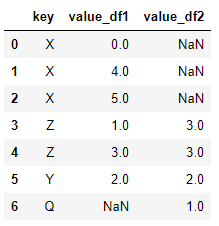
可以看到,df2中没有的df1中有的X,在df2的数据中自动填充了空值NaN。df1中也相同。
3)左连接
# 对左边on='×'列的数据进行链接,右边没有的,用NaN进行填充 pd.merge(dframe1,dframe2,on='key',how='left') >>
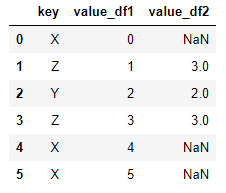
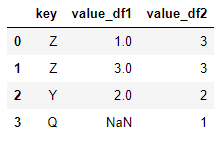
可以看出,key只有左边数据的数据,在右边数据没有的,就用空值填充。
4)右连接
# 与左连接相反。以右边数据为基准,左边没有的用空值填充 pd.merge(dframe1,dframe2,on='key',how='right') >>
2、在多个字段上的连接
# 定义两个DataFrame数据 df_left = DataFrame({'key1': ['SF', 'SF', 'LA'], 'key2': ['one', 'two', 'one'], 'left_data': [10,20,30]}) df_left >> key1 key2 left_data 0 SF one 10 1 SF two 20 2 LA one 30 df_right = DataFrame({'key1': ['SF', 'SF', 'LA', 'LA'], 'key2': ['one', 'one', 'one', 'two'], 'right_data': [40,50,60,70]}) df_right >> key1 key2 right_data 0 SF one 40 1 SF one 50 2 LA one 60 3 LA two 70
1)内连接
# 指定同时在多个字段上连接 pd.merge(df_left, df_right, on=['key1', 'key2'])

2)外连接
# 指定how='outer' pd.merge(df_left, df_right, on=['key1', 'key2'],how='outer')

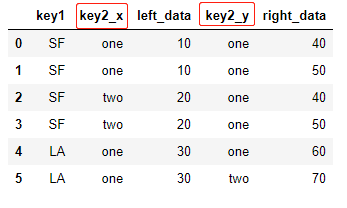
3)若两列中有多个相同名称字段,且只在一个字段上了连接
# 只对key1连接,key2会自动重命名 pd.merge(df_left,df_right,on='key1') >>
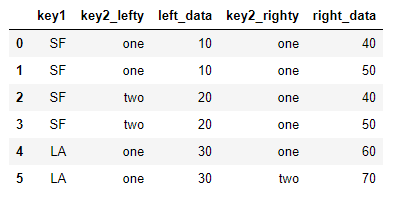
# 当然也可以给key2字段分别加后缀 pd.merge(df_left,df_right, on='key1',suffixes=('_lefty','_righty')) >>
3)左连接
# 指定how='left' pd.merge(df_left, df_right, on=['key1', 'key2'],how='left') >>

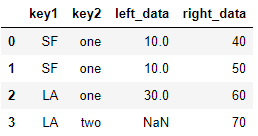
4)右连接
# 指定how='right' pd.merge(df_left, df_right, on=['key1', 'key2'],how='right') >>
3、merge在index上的应用
# 定义两个数据:
# 一个数据是'key'列数据是X, Y, Z
# 一个是索引数据为X, Y, Z
df_left = DataFrame({'key': ['X','Y','Z','X','Y'], 'data': range(5)}) df_left >> key data 0 X 0 1 Y 1 2 Z 2 3 X 3 4 Y 4 df_right = DataFrame({'group_data': [10, 20]}, index=['X', 'Y']) # 定义数据的索引为X, Y df_right >> group_data
X 10
Y 20
1)left_on, right_on
# 两边可以分别选择不一样字段的数据进行连接 # 通过left_on指定左边字段,right_on指定右边字段 pd.merge(df_left,df_left,left_on='key',right_on='key') >>

2)left_on, right_index
# 指定左边数据的'key'列,并且将左边数据的索引用于右边。
# 默认是内连接 pd.merge(df_left,df_right,left_on='key',right_index=True) >>
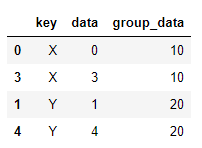
# 外连接 pd.merge(df_left,df_right,left_on='key',right_index=True, how='outer') >>
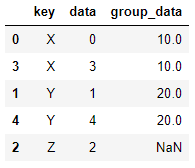
左连接、右连接类似
pd.merge(df_left,df_right,left_on='key',right_index=True, how='left') # 左连接 pd.merge(df_left,df_right,left_on='key',right_index=True, how='right') # 右连接 >>
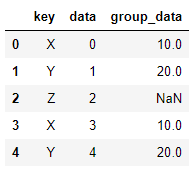

4、merge在多层嵌套index的情况
# 建立多层索引数据,左边数据两个字段数据,对应右边数据多层索引
df_left_hr = DataFrame({'key1': ['SF','SF','SF','LA','LA'], 'key2': [10, 20, 30, 20, 30], 'data_set': np.arange(5.)}) df_left_hr >> key1 key2 data_set 0 SF 10 0.0 1 SF 20 1.0 2 SF 30 2.0 3 LA 20 3.0 4 LA 30 4.0 df_right_hr = DataFrame(np.arange(10).reshape((5, 2)), index=[['LA','LA','SF','SF','SF'], [20, 10, 10, 10, 20]], columns=['col_1', 'col_2']) df_right_hr >> col_1 col_2 LA 20 0 1 10 2 3 SF 10 4 5 10 6 7 20 8 9
# 通过key1, key2连接,并且使用左边数据的索引 pd.merge(df_left_hr,df_right_hr,left_on=['key1','key2'],right_index=True)
>>

二、join
join默认是在索引上进行合并
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']},
index = ['K0', 'K1', 'K2', 'K3'])
left
>>
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2
K3 A3 B3
right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3', 'C4'],
'D': ['D0', 'D1', 'D2', 'D3', 'D4']},
index = ['K0', 'K1', 'K2', 'K3', 'K4'])
right
>>
C D
K0 C0 D0
K1 C1 D1
K2 C2 D2
K3 C3 D3
K4 C4 D4
1、内连接
# 默认内连接
left.join(right) # 注意,只能用df1.join(df2)的格式 >>

2、外连接
left.join(right, how='outer') >>

3、左右连接分别指定how='left', how='right'即可

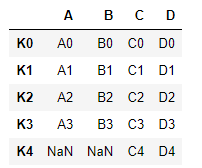
4、多个字段连接
df_left = DataFrame({'key1': ['SF', 'SF', 'LA'],
'key2': ['one', 'two', 'one'],
'left_data': [10,20,30]},
index=['a', 'b', 'c'])
df_left
>>
key1 key2 left_data
a SF one 10
b SF two 20
c LA one 30
df_right = DataFrame({'key1': ['SF', 'SF', 'LA', 'Lb'],
'key2': ['one', 'one', 'one', 'two'],
'right_data': [40,50,60,70]},
index=['k', 'j', 'y', 'x'])
df_right
>>
key1 key2 right_data
k SF one 40
j SF one 50
y LA one 60
x Lb two 70
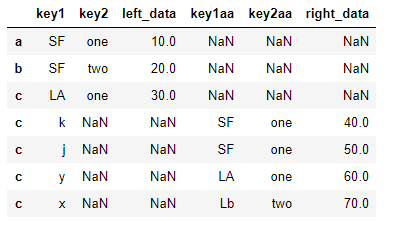
1)连接单列,有其他相同字段,加后缀
df_left.join(df_right, on='key1',how='outer', rsuffix='aa') # 相同列加aa后缀 >>
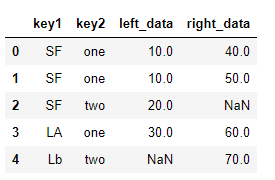
2)多列连接
pd.merge(df_left, df_right, on=['key1', 'key2'],how='outer') >>
三、concat
1、纵向拼接
将数据沿指定轴方向拼接,默认是纵向拼接,效果与df1.append(df2)一样
前提:列数量和字段名必须相等
df1 = pd.DataFrame({'key1': ['SF','SF','SF','LA','LA'],
'key2': [10, 20, 30, 20, 30],
'data_set': np.arange(5.)})
df1
>>
key1 key2 data_set
0 SF 10 0.0
1 SF 20 1.0
2 SF 30 2.0
3 LA 20 3.0
4 LA 30 4.0
df2 = pd.DataFrame({'key1': ['FS','SF','FS','LA','LA'],
'key2': [10, 20, 30, 20, 30],
'data_set': np.arange(5.)})
df2
>>
key1 key2 data_set
0 FS 10 0.0
1 SF 20 1.0
2 FS 30 2.0
3 LA 20 3.0
4 LA 30 4.0
# 纵向拼接,以下两个代码效果一样 pd.concat([df1, df2]) # 目前发现纵向拼接时候:join='inner','outer'效果一样 df1.append(df2) # 不过append不能用于横向拼接 >>


2、横向拼接
# 定义两个索引数据 df4 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}, index=[0, 1, 2, 3]) df4 >> A B C D 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 df5 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'], 'D': ['D2', 'D3', 'D6', 'D7'], 'F': ['F2', 'F3', 'F6', 'F7']}, index=[2, 3, 6, 7]) df5 >> B D F 2 B2 D2 F2 3 B3 D3 F3 6 B6 D6 F6 7 B7 D7 F7
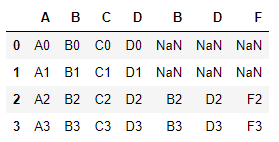
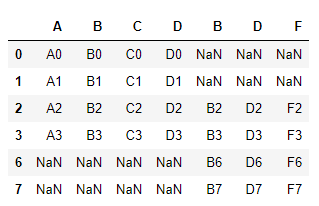
1)、横向,默认是外连接
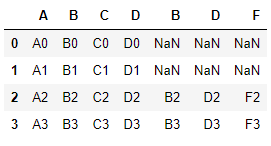
pd.concat([df4, df5], axis=1)
>>
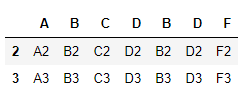
2)、内连接
# 指定join='inner' pd.concat([df4, df5], axis=1, join='inner') >>
3)、指定左边序列索引当索引
# 通过join_axes,指定df4索引的索引为索引,类似于左连接 pd.concat([df4, df5], axis=1, join_axes=[df4.index]) >>
4)、指定右边序列索引当索引
# 通过join_axes,指定df5索引的索引为索引,类似于右连接 pd.concat([df4, df5], axis=1, join_axes=[df5.index]) >>