import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
# 读取数据
data = pd.read_csv("./Taitanic data/data.csv")
# 注意:标签是Survived,没哟在最后一列
data
|
PassengerId |
Survived |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
| 0 |
1 |
0 |
3 |
Braund, Mr. Owen Harris |
male |
22.0 |
1 |
0 |
A/5 21171 |
7.2500 |
NaN |
S |
| 1 |
2 |
1 |
1 |
Cumings, Mrs. John Bradley (Florence Briggs Th... |
female |
38.0 |
1 |
0 |
PC 17599 |
71.2833 |
C85 |
C |
| 2 |
3 |
1 |
3 |
Heikkinen, Miss. Laina |
female |
26.0 |
0 |
0 |
STON/O2. 3101282 |
7.9250 |
NaN |
S |
| 3 |
4 |
1 |
1 |
Futrelle, Mrs. Jacques Heath (Lily May Peel) |
female |
35.0 |
1 |
0 |
113803 |
53.1000 |
C123 |
S |
| 4 |
5 |
0 |
3 |
Allen, Mr. William Henry |
male |
35.0 |
0 |
0 |
373450 |
8.0500 |
NaN |
S |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 886 |
887 |
0 |
2 |
Montvila, Rev. Juozas |
male |
27.0 |
0 |
0 |
211536 |
13.0000 |
NaN |
S |
| 887 |
888 |
1 |
1 |
Graham, Miss. Margaret Edith |
female |
19.0 |
0 |
0 |
112053 |
30.0000 |
B42 |
S |
| 888 |
889 |
0 |
3 |
Johnston, Miss. Catherine Helen "Carrie" |
female |
NaN |
1 |
2 |
W./C. 6607 |
23.4500 |
NaN |
S |
| 889 |
890 |
1 |
1 |
Behr, Mr. Karl Howell |
male |
26.0 |
0 |
0 |
111369 |
30.0000 |
C148 |
C |
| 890 |
891 |
0 |
3 |
Dooley, Mr. Patrick |
male |
32.0 |
0 |
0 |
370376 |
7.7500 |
NaN |
Q |
891 rows × 12 columns
# 查看数据信息
# 可以看到数据类型 和 每个字段非空值数据量
# 可以看到Age、Cabin字段有数据缺失,需要专门处理
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
data.head()
|
PassengerId |
Survived |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
| 0 |
1 |
0 |
3 |
Braund, Mr. Owen Harris |
male |
22.0 |
1 |
0 |
A/5 21171 |
7.2500 |
NaN |
S |
| 1 |
2 |
1 |
1 |
Cumings, Mrs. John Bradley (Florence Briggs Th... |
female |
38.0 |
1 |
0 |
PC 17599 |
71.2833 |
C85 |
C |
| 2 |
3 |
1 |
3 |
Heikkinen, Miss. Laina |
female |
26.0 |
0 |
0 |
STON/O2. 3101282 |
7.9250 |
NaN |
S |
| 3 |
4 |
1 |
1 |
Futrelle, Mrs. Jacques Heath (Lily May Peel) |
female |
35.0 |
1 |
0 |
113803 |
53.1000 |
C123 |
S |
| 4 |
5 |
0 |
3 |
Allen, Mr. William Henry |
male |
35.0 |
0 |
0 |
373450 |
8.0500 |
NaN |
S |
筛选特征
# 删除 Name,影响较小
# 删除 Cabin,缺失值较多
# Ticket在这里也没多大用处,也删掉
data.drop(['Name', 'Cabin', 'Ticket'], axis=1, inplace=True)
# 因为 Embarked 比其他数据多两行空值,所以删掉其为空值的两行
data = data[data['Embarked'].notna()]
data.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
Embarked |
| 0 |
1 |
0 |
3 |
male |
22.0 |
1 |
0 |
7.2500 |
S |
| 1 |
2 |
1 |
1 |
female |
38.0 |
1 |
0 |
71.2833 |
C |
| 2 |
3 |
1 |
3 |
female |
26.0 |
0 |
0 |
7.9250 |
S |
| 3 |
4 |
1 |
1 |
female |
35.0 |
1 |
0 |
53.1000 |
S |
| 4 |
5 |
0 |
3 |
male |
35.0 |
0 |
0 |
8.0500 |
S |
data['Embarked'].unique().tolist()
['S', 'C', 'Q']
# 将Sex、Embarked转换为数字类型
data['Sex'] = data['Sex'].map({'male': 0, 'female': 1})
data['Embarked'] = data['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
data.head()
D:UsersjaysonAnaconda3libsite-packagesipykernel_launcher.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
D:UsersjaysonAnaconda3libsite-packagesipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
This is separate from the ipykernel package so we can avoid doing imports until
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
Embarked |
| 0 |
1 |
0 |
3 |
0 |
22.0 |
1 |
0 |
7.2500 |
0 |
| 1 |
2 |
1 |
1 |
1 |
38.0 |
1 |
0 |
71.2833 |
1 |
| 2 |
3 |
1 |
3 |
1 |
26.0 |
0 |
0 |
7.9250 |
0 |
| 3 |
4 |
1 |
1 |
1 |
35.0 |
1 |
0 |
53.1000 |
0 |
| 4 |
5 |
0 |
3 |
0 |
35.0 |
0 |
0 |
8.0500 |
0 |
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 889 entries, 0 to 890
Data columns (total 9 columns):
PassengerId 889 non-null int64
Survived 889 non-null int64
Pclass 889 non-null int64
Sex 889 non-null int64
Age 712 non-null float64
SibSp 889 non-null int64
Parch 889 non-null int64
Fare 889 non-null float64
Embarked 889 non-null int64
dtypes: float64(2), int64(7)
memory usage: 69.5 KB
# 对年龄进行填充:中值或均值,此处使用中值 填充
data.loc[data['Age'].isna(), 'Age'] = data['Age'].median()
data
D:UsersjaysonAnaconda3libsite-packagespandascoreindexing.py:494: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
Embarked |
| 0 |
1 |
0 |
3 |
0 |
22.0 |
1 |
0 |
7.2500 |
0 |
| 1 |
2 |
1 |
1 |
1 |
38.0 |
1 |
0 |
71.2833 |
1 |
| 2 |
3 |
1 |
3 |
1 |
26.0 |
0 |
0 |
7.9250 |
0 |
| 3 |
4 |
1 |
1 |
1 |
35.0 |
1 |
0 |
53.1000 |
0 |
| 4 |
5 |
0 |
3 |
0 |
35.0 |
0 |
0 |
8.0500 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 886 |
887 |
0 |
2 |
0 |
27.0 |
0 |
0 |
13.0000 |
0 |
| 887 |
888 |
1 |
1 |
1 |
19.0 |
0 |
0 |
30.0000 |
0 |
| 888 |
889 |
0 |
3 |
1 |
28.0 |
1 |
2 |
23.4500 |
0 |
| 889 |
890 |
1 |
1 |
0 |
26.0 |
0 |
0 |
30.0000 |
1 |
| 890 |
891 |
0 |
3 |
0 |
32.0 |
0 |
0 |
7.7500 |
2 |
889 rows × 9 columns
# 分离特征数据和 标签数据
X = data.drop('Survived', axis=1)
y = data['Survived']
X
|
PassengerId |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
Embarked |
| 0 |
1 |
3 |
0 |
22.0 |
1 |
0 |
7.2500 |
0 |
| 1 |
2 |
1 |
1 |
38.0 |
1 |
0 |
71.2833 |
1 |
| 2 |
3 |
3 |
1 |
26.0 |
0 |
0 |
7.9250 |
0 |
| 3 |
4 |
1 |
1 |
35.0 |
1 |
0 |
53.1000 |
0 |
| 4 |
5 |
3 |
0 |
35.0 |
0 |
0 |
8.0500 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 886 |
887 |
2 |
0 |
27.0 |
0 |
0 |
13.0000 |
0 |
| 887 |
888 |
1 |
1 |
19.0 |
0 |
0 |
30.0000 |
0 |
| 888 |
889 |
3 |
1 |
28.0 |
1 |
2 |
23.4500 |
0 |
| 889 |
890 |
1 |
0 |
26.0 |
0 |
0 |
30.0000 |
1 |
| 890 |
891 |
3 |
0 |
32.0 |
0 |
0 |
7.7500 |
2 |
889 rows × 8 columns
拆分数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 因为数据是随机拆分的,所以为了后续选择数据方便,将索引重置一下
for i in [X_train, X_test, y_train, y_test]:
i.index = range(0, i.shape[0])
X_train
|
PassengerId |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
Embarked |
| 0 |
294 |
3 |
1 |
24.0 |
0 |
0 |
8.8500 |
0 |
| 1 |
157 |
3 |
1 |
16.0 |
0 |
0 |
7.7333 |
2 |
| 2 |
542 |
3 |
1 |
9.0 |
4 |
2 |
31.2750 |
0 |
| 3 |
742 |
1 |
0 |
36.0 |
1 |
0 |
78.8500 |
0 |
| 4 |
220 |
2 |
0 |
30.0 |
0 |
0 |
10.5000 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 706 |
410 |
3 |
1 |
28.0 |
3 |
1 |
25.4667 |
0 |
| 707 |
821 |
1 |
1 |
52.0 |
1 |
1 |
93.5000 |
0 |
| 708 |
562 |
3 |
0 |
40.0 |
0 |
0 |
7.8958 |
0 |
| 709 |
729 |
2 |
0 |
25.0 |
1 |
0 |
26.0000 |
0 |
| 710 |
120 |
3 |
1 |
2.0 |
4 |
2 |
31.2750 |
0 |
711 rows × 8 columns
先粗略训练一下查看效果
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=2)
clf = clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
score
0.7696629213483146
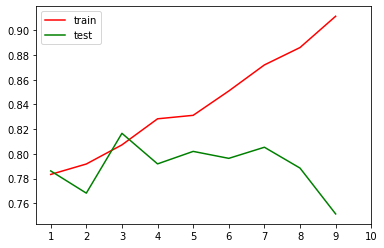
通过交叉验证,画学习曲线
from sklearn.model_selection import cross_val_score
model_scores = []
cross_vscors = []
for depth in range(1, 10):
clf = DecisionTreeClassifier(random_state=25
, max_depth=depth
# , criterion='entropy' # 通常认为entropy是当模型欠拟合时候使用
)
clf = clf.fit(X_train, y_train)
score_tr = clf.score(X_train, y_train)
cross_tr = cross_val_score(clf, X, y, cv=10).mean()
model_scores.append(score_tr)
cross_vscors.append(cross_tr)
plt.plot(range(1, 10), model_scores, color='red', label='train')
plt.plot(range(1, 10), cross_vscors, color='green', label='test')
plt.xticks(range(1, 11))
plt.legend(loc='upper left')
<matplotlib.legend.Legend at 0x24aec8a9608>
网格搜索查看参数
import numpy as np
# gini_thresholds = np.linspace(0, 0.5, 50) # 基尼系数常用取值范围
# entropy_threholds = np.linspace(0, 1, 50)
# 定义模型参数,用于传入GridSearchCV,且在实例化模型时候,不需要传入参数
parameters = {"splitter": ('best', 'random')
, "criterion": ("gini", "entropy")
, "min_samples_leaf": [*range(1, 50, 5)]
, "min_impurity_decrease": [*np.linspace(0, 0.5, 20)] # 不使用网格搜索,这个参数比较难使用
, "max_depth": [*range(1, 10)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train, y_train)
D:UsersjaysonAnaconda3libsite-packagessklearnmodel_selection\_search.py:814: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=DecisionTreeClassifier(class_weight=None,
criterion='gini', max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort=False, random_state=25,
splitter='best'),
iid='warn', n_...
0.23684210526315788,
0.2631578947368421,
0.2894736842105263,
0.3157894736842105,
0.3421052631578947,
0.3684210526315789,
0.39473684210526316,
0.42105263157894735,
0.4473684210526315,
0.47368421052631576, 0.5],
'min_samples_leaf': [1, 6, 11, 16, 21, 26, 31, 36, 41,
46],
'splitter': ('best', 'random')},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
# 最好的参数
GS.best_params_
{'criterion': 'gini',
'max_depth': 3,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'splitter': 'best'}
# 最高的得分
GS.best_score_
0.8171589310829818
# 网格搜索的缺点:输入进去的参数都会使用到,他不会自动舍弃某些参数,可能有时候舍弃某些参数的模型性能更好