本课主题
- Master HA 解析
- Master HA 解析源码分享
[引言部份:你希望读者看完这篇博客后有那些启发、学到什么样的知识点]
更新中......
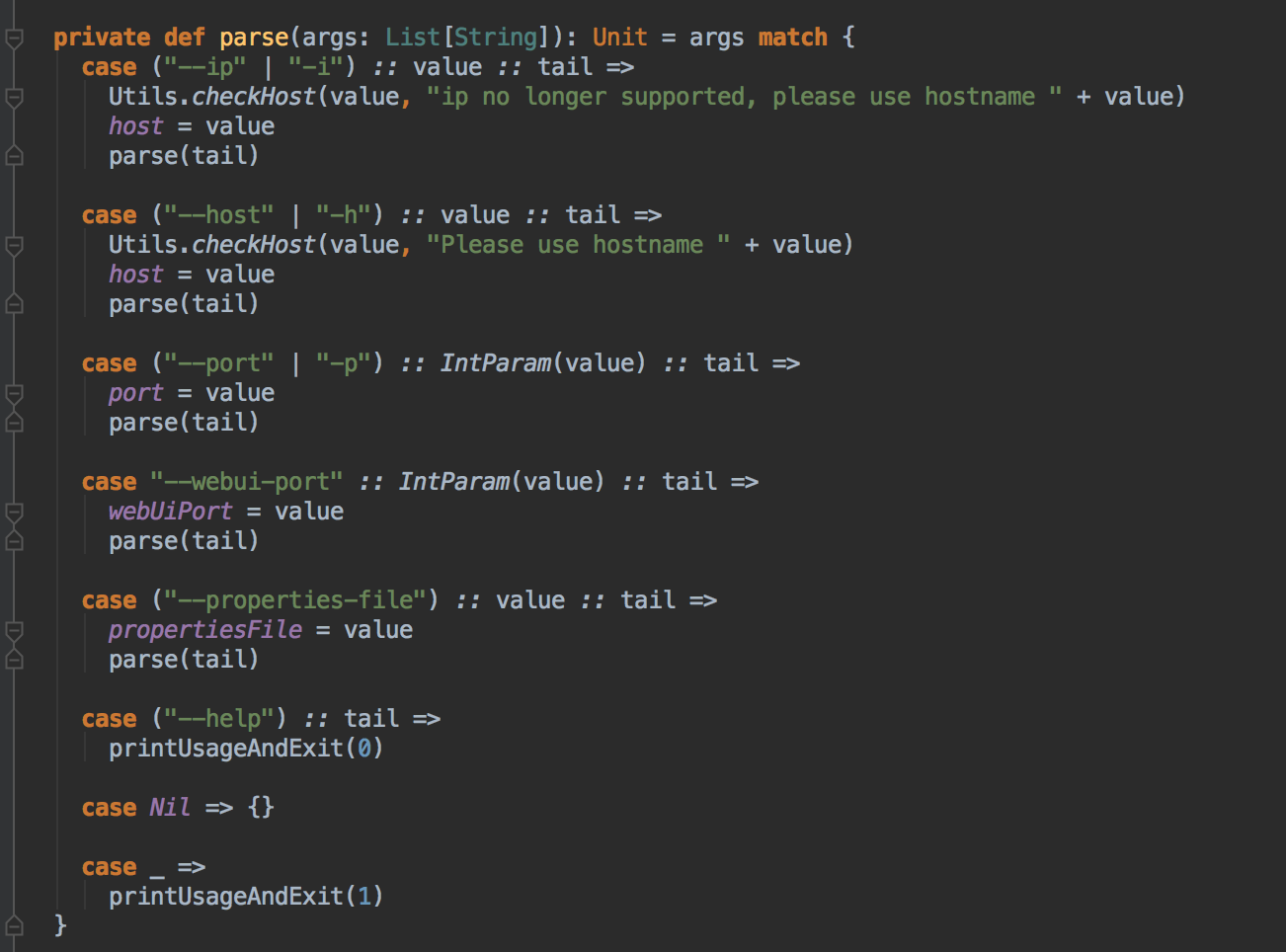
Master HA 解析
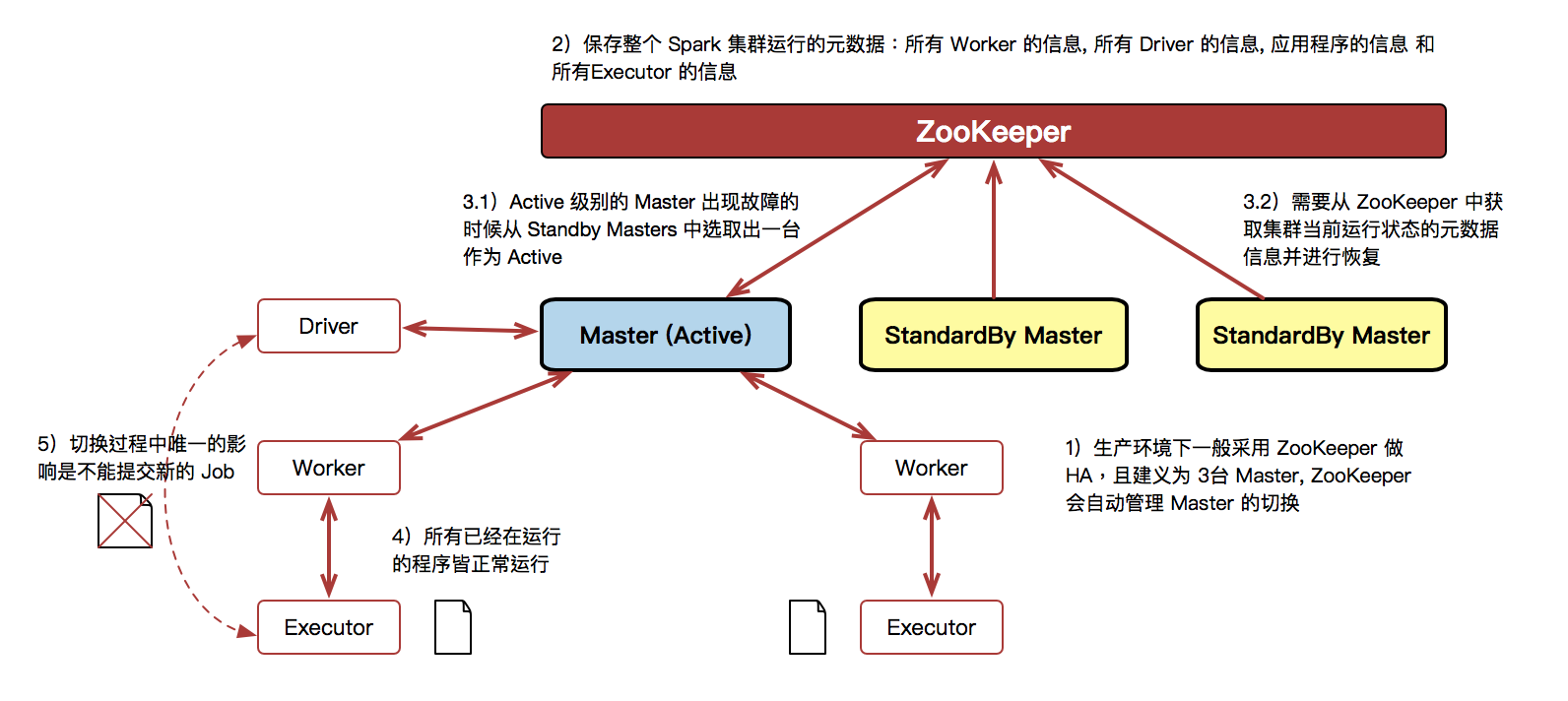
- 生产环境下一般采用 ZooKeeper 做 HA,且建义为 3台 Master, ZooKeeper 会自动管理 Master 的切换
- 采用 ZooKeeper 做 HA 的时候,ZooKeeper 会负责保存整个 Spark 集群运行的元数据:所有 Worker 的信息, 所有 Driver 的信息, 应用程序的信息 和 所有Executor 的信息
- ZooKeeper 遇到当前Active 级别的Master 出现故障的时候从Standby Masters 中选取出一台作为Active , 但是要注意,被选举后到成为真正的Active Master 之间需要从ZooKeeper 中获取集群当前运行状态的元数据信息并进行恢复;
- 在 Master 切换的过程中,所有已经在运行的程序皆正常运行!因为 Spark Application 在运行前就已经通过 Cluster Manager 获得了计算资源 所以在运行时 Job 本身的调度和处理和 Master 是没有任何关系的!
- 在Master 的切换过程中唯一的影响是不能提交新的Job: 一方面不能提交新的应用程序给集群,因为只有Active Master 才能接受新的程序的提交请求;另外一方面,已经运行的程序也不能够因为Action 操作触发新的Job 的提交请求。
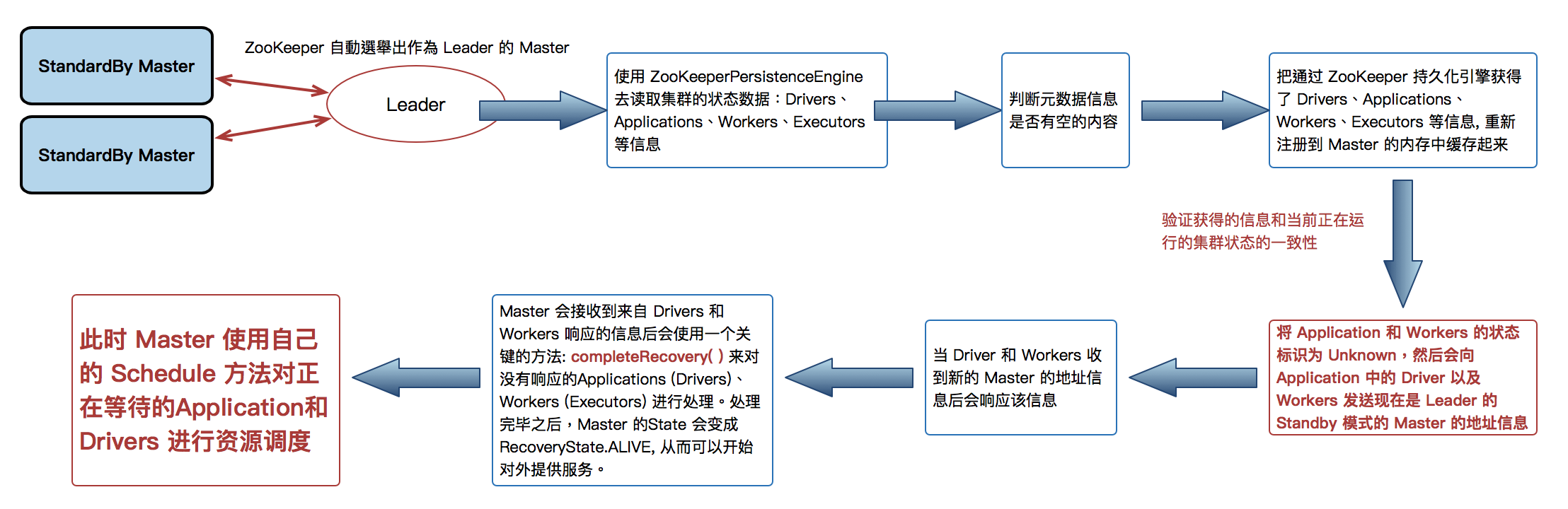
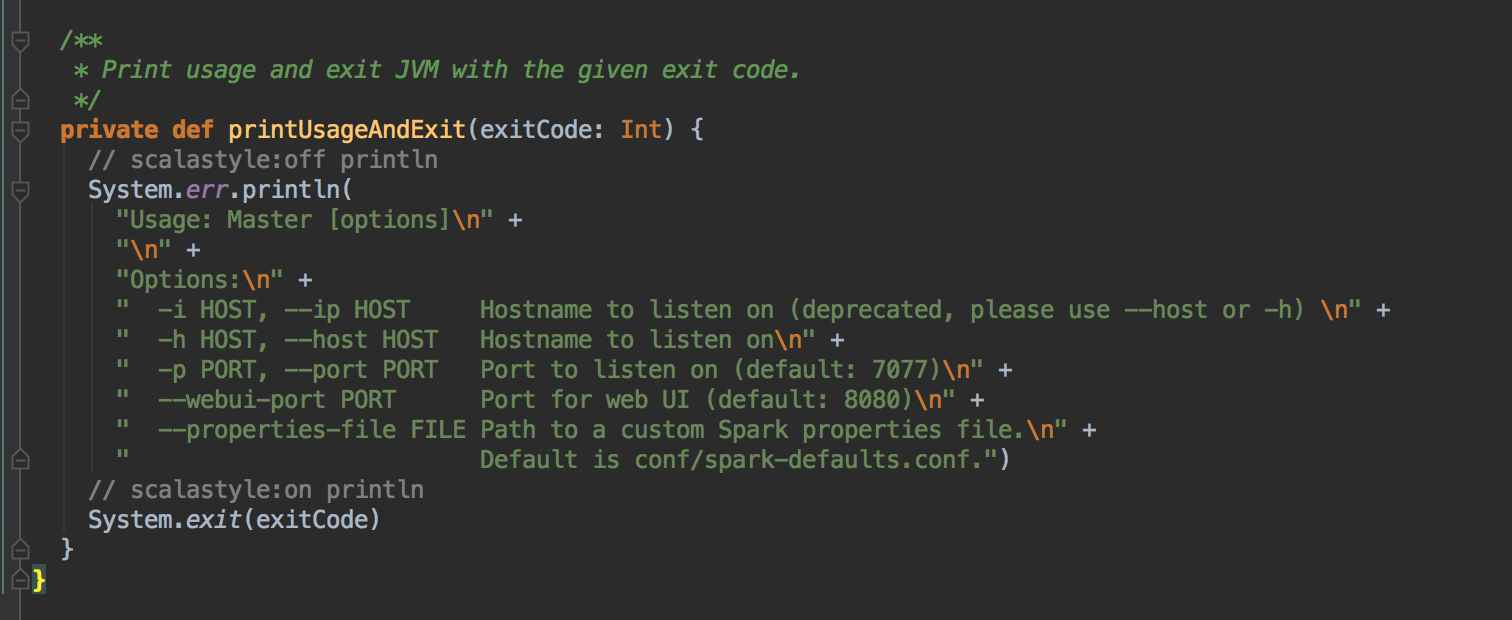
Spark Master HA on ZooKeeper 切換流程圖
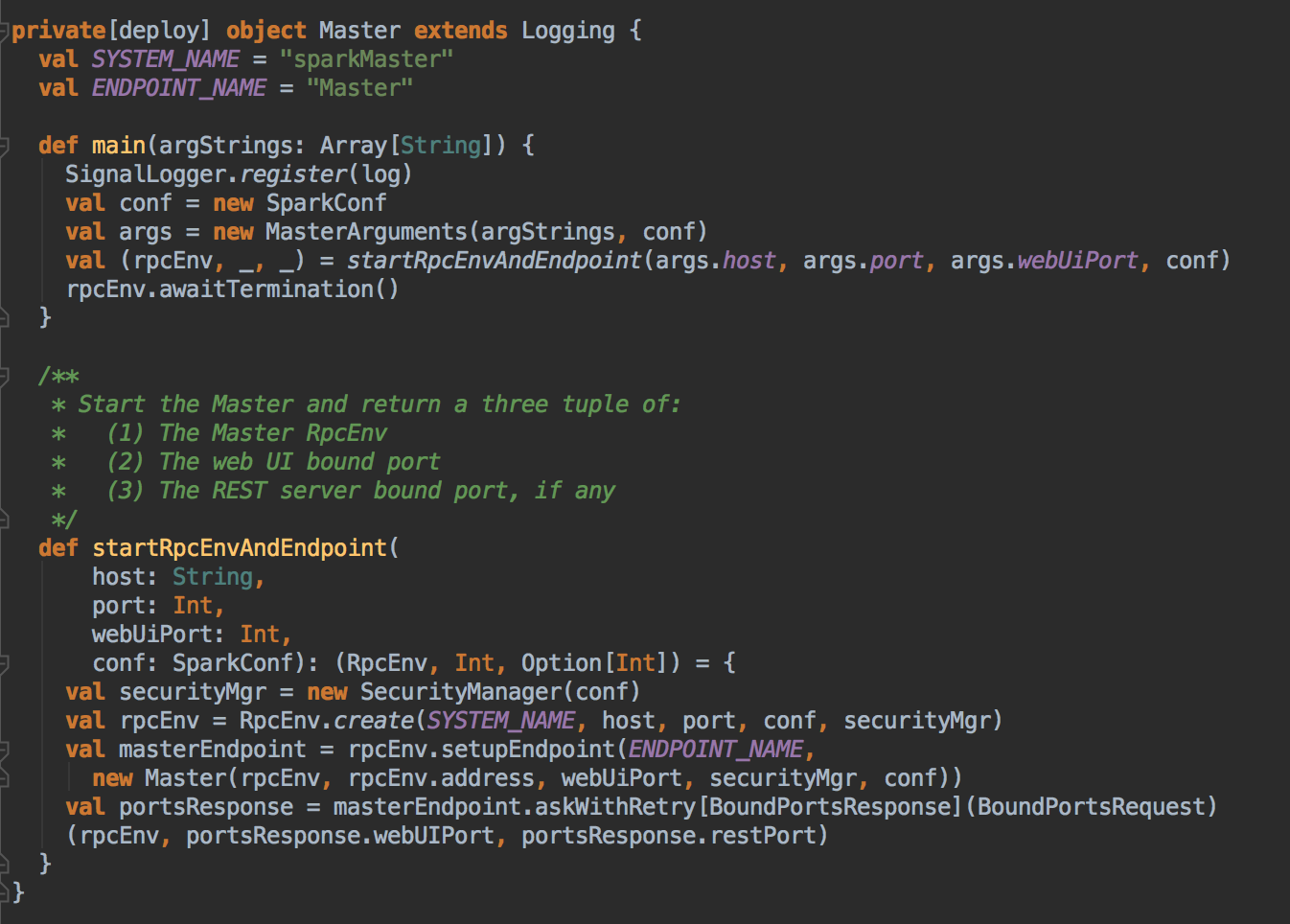
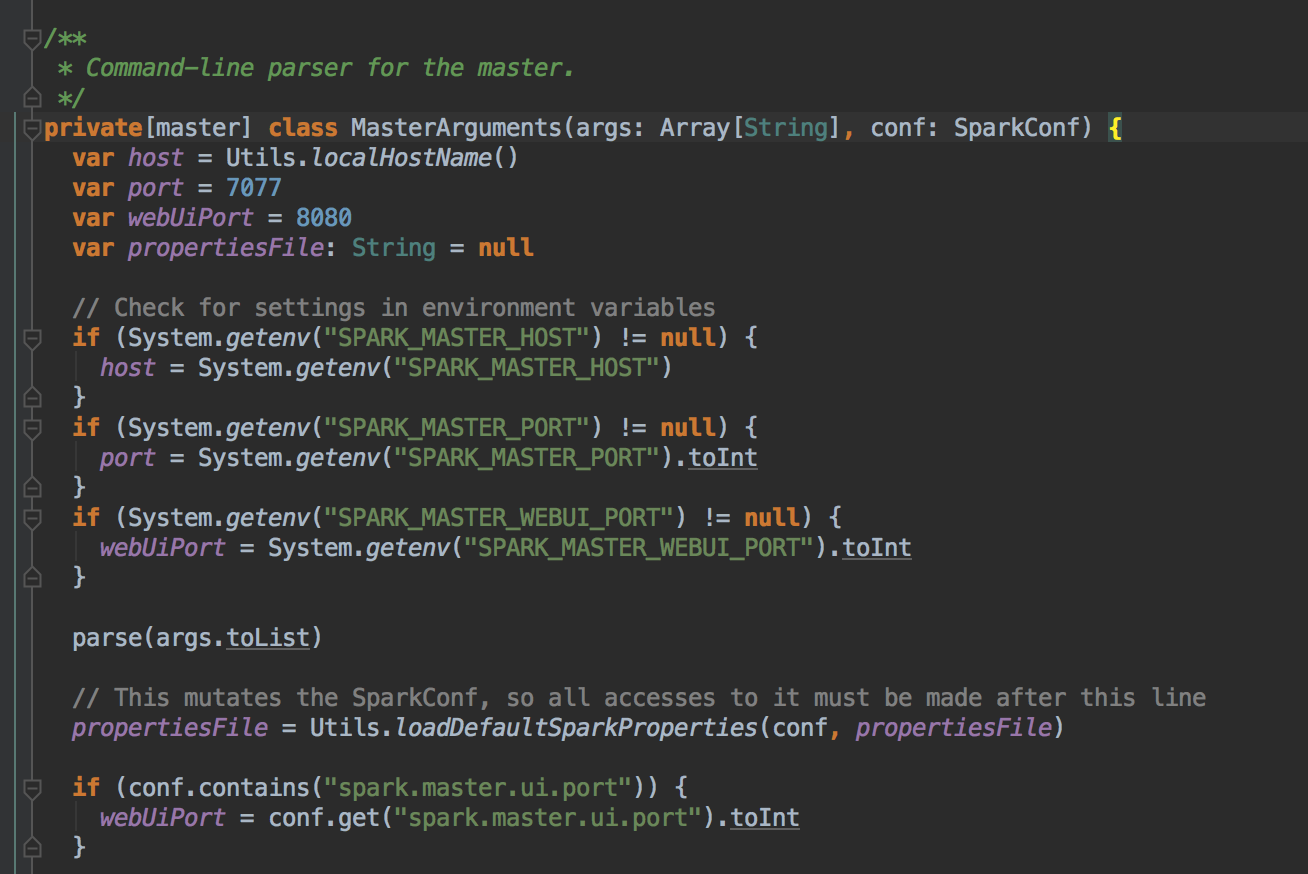
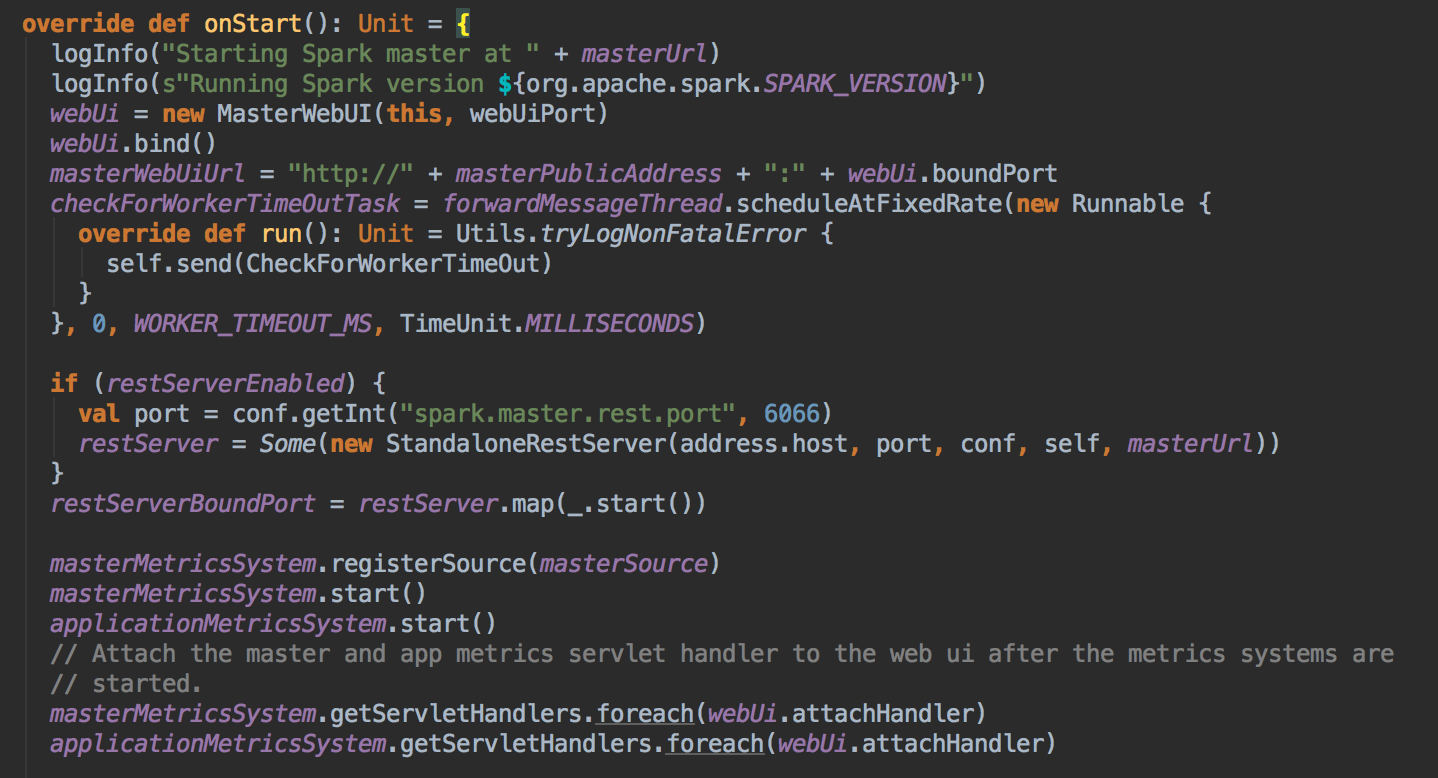
Master HA 的四大方式
- Master HA 的四大方式:分別是 ZOOKEEPER,FILESYSTEM, CUSTOM, NONE;
- 需要说明的是:
- ZOOKEEPER 是自動管理 Master;
- FILESYSTEM 的方式在 Master 出现突障后需要手动启动机器,机器启动后会立即成为 Active 级别的 Master 来对外提供服务(接受应用程序提交的请求、接受新的 Job 运行的请求)
- CUSTOM 的方式允许用户自定义 Master HA 的实现,这对于高级用户特别有用;
- NONE,这是默应情况,当我们下载安装了 Spark 集群中就是采用这种方式,该方式不会持久化集群的数据, Driver, Application, Worker and Executor. Master 启动起立即管理集群;
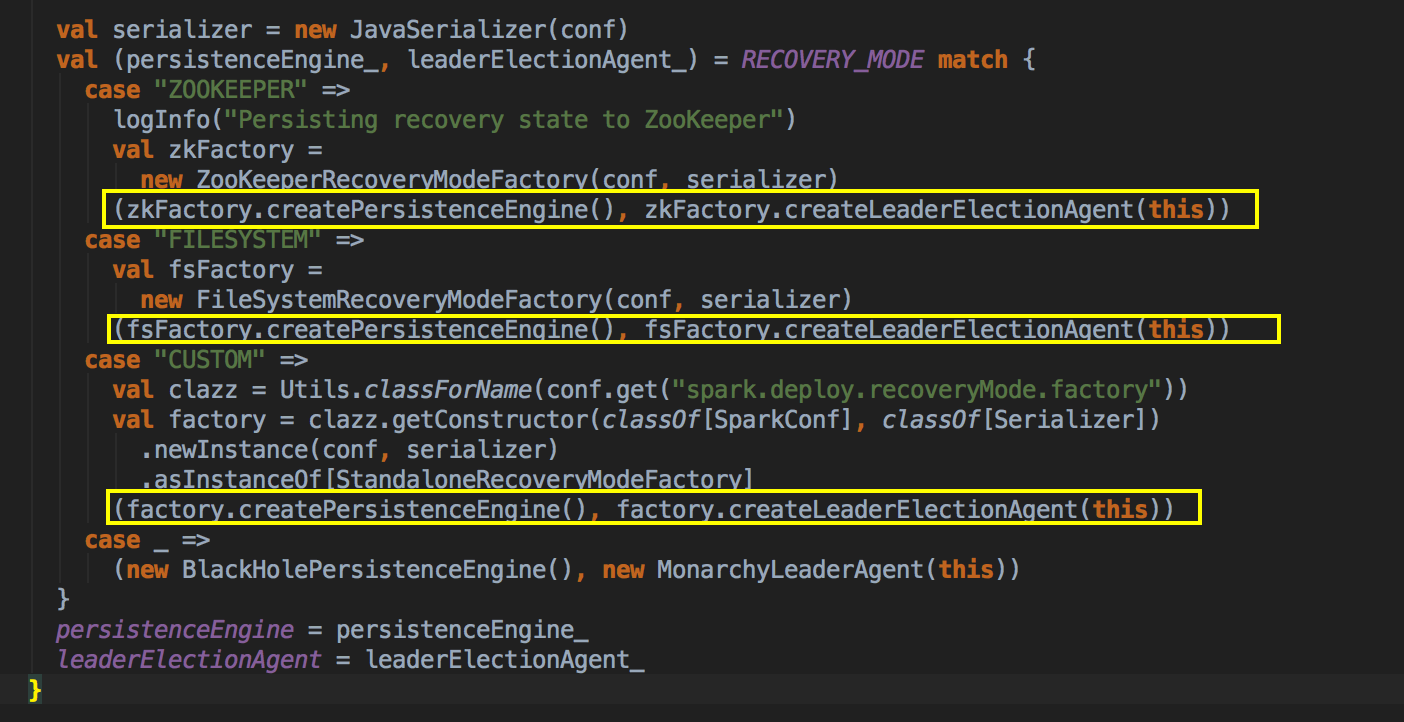
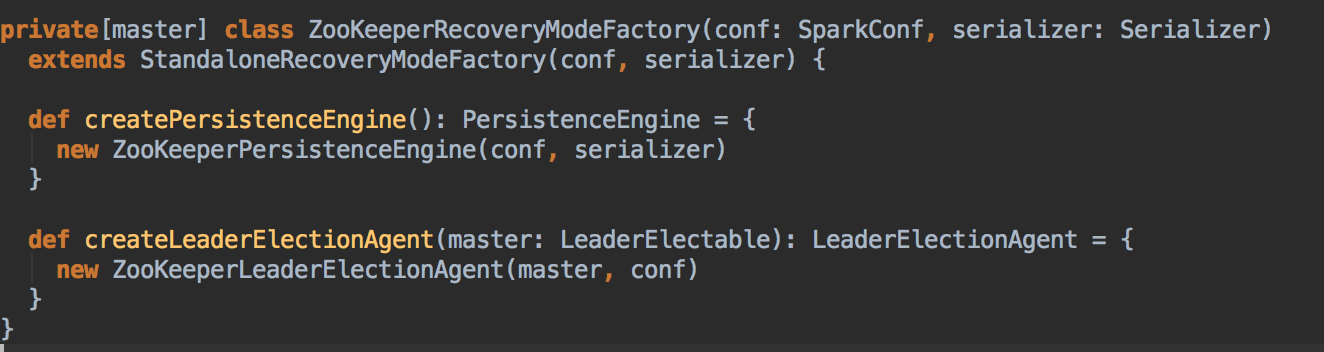
- Persistence Engine 中有一个至关重要的方法 persists 来实现数据持久化

readPersistedData 来获取恢复集群中的元数据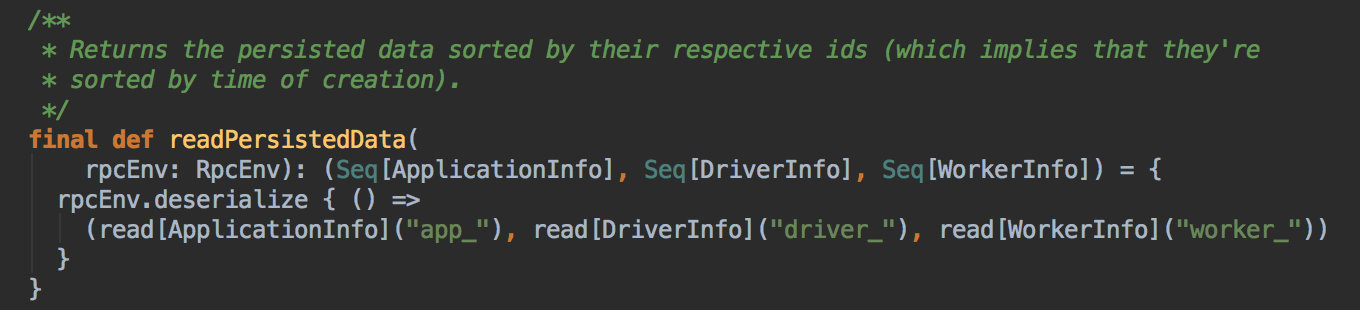
现在去看看它的createdLeaderElectionAgent的方法

- FILESYSTEM 和 NONE 的方式均是采用 MonarchyLeaderAgent 的方式来完成 Leader的选举的,其实际实现是直接把传入的 Master 作为 Leader
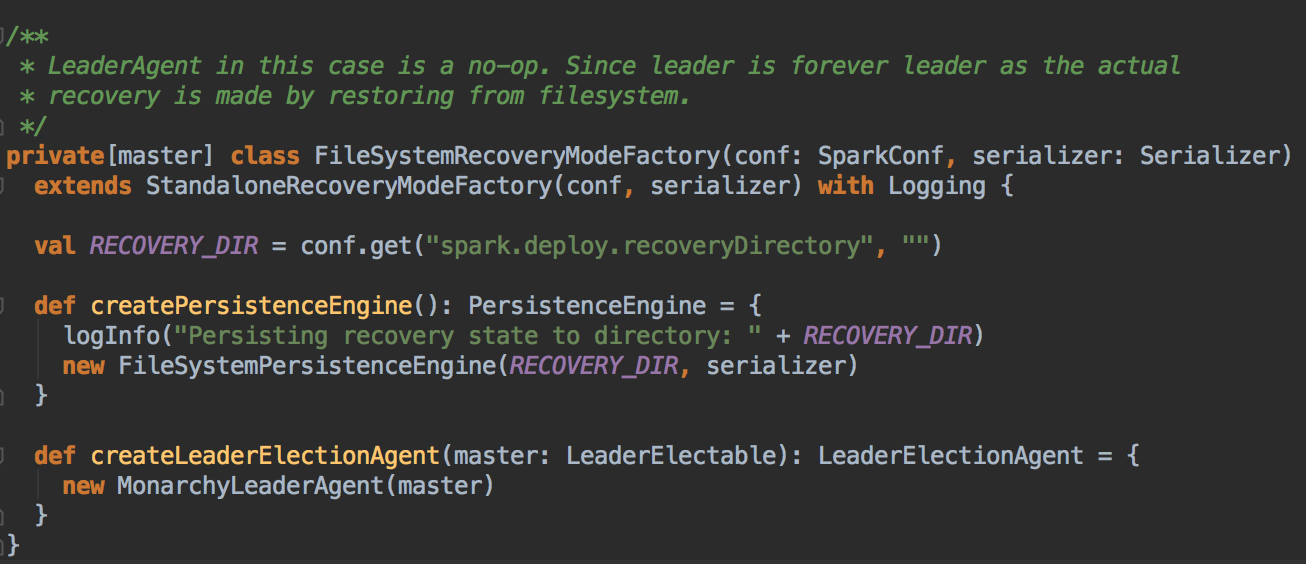
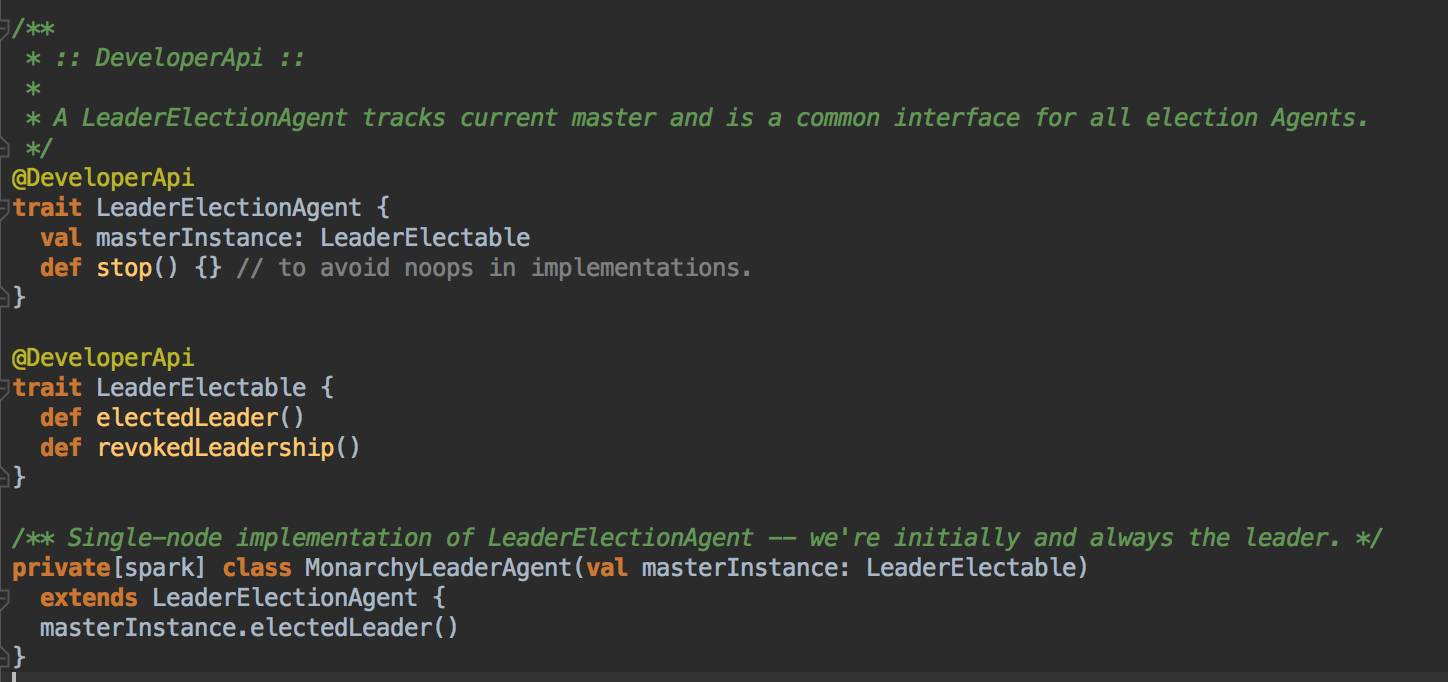
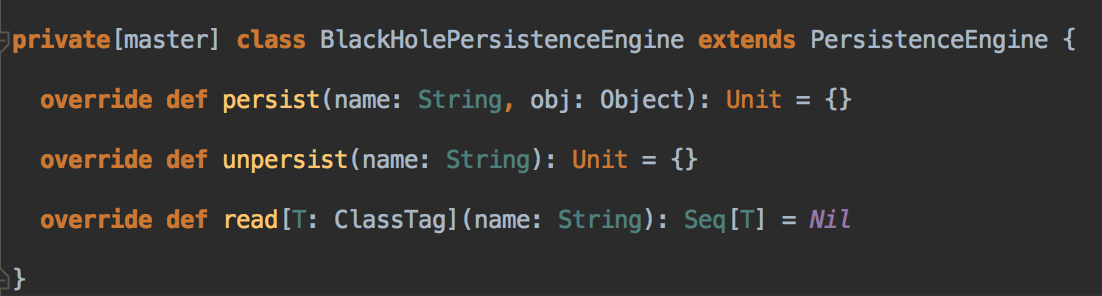
- NONE 的方式根本不需要持久化引擎,它为什么要搞一个BlackHoleEngine
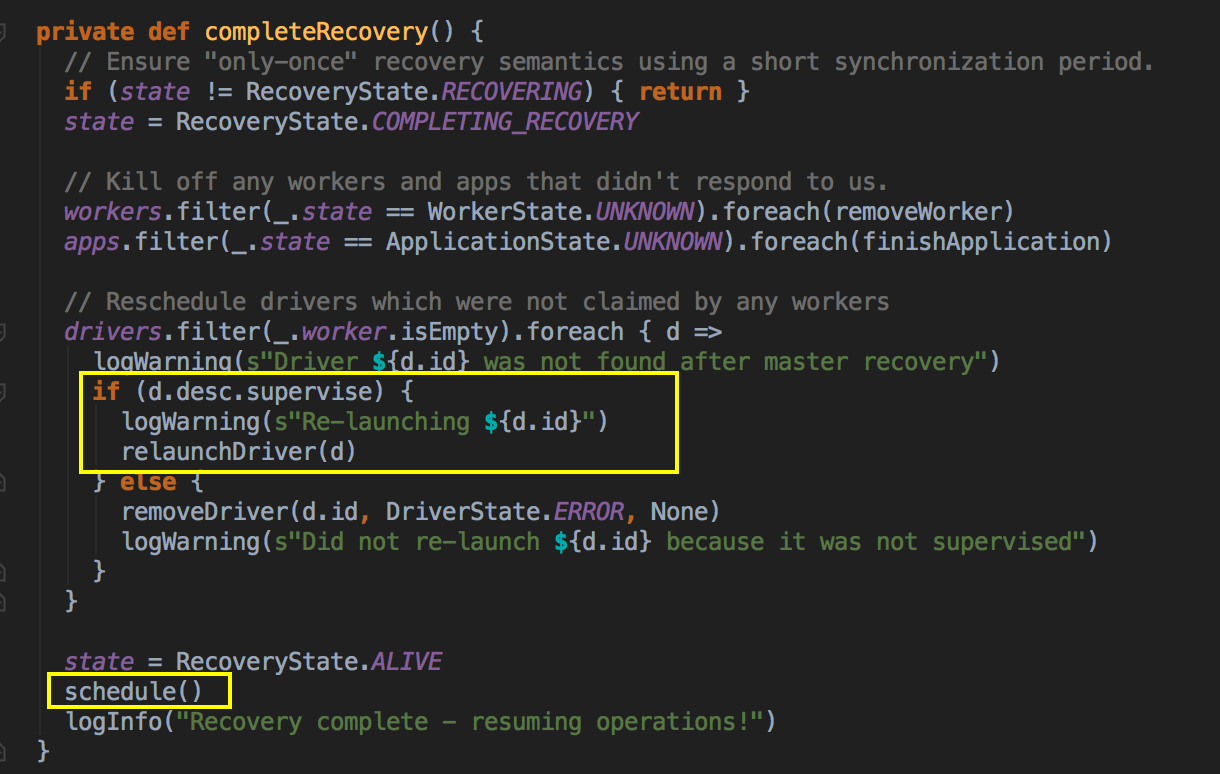
- 对一些WorkerState状态为UNKNOWN 的话(Worker不响应),就把它删除掉,如果你是以集群方式运行的话,driver 失败话可以重新启动一下,最后把状态变回ALIVE,这里注意要加入--supervise这一个参数。
[总结部份]
更新中......
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第29课:Master HA彻底解密
Spark源码图片取自于 Spark 1.6.0版本