本课主题
- NoSQL 数据库介绍
- HBase 基本操作
- HBase 集群架构与设计介紹
- HBase 与HDFS的关系
- HBase 数据拆分和紧缩
引言
介绍什么是 NoSQL,NoSQL 和 RDBMS 之间有什么区别,有什么埸景下需要用 NoSQL 数据库,NoSQL 数据的优点和缺点;谈谈 NoSQL 一些基本的背景之后,这章会重点深入谈讨 HBase 数据库,HBase 的原理,交换 Shell 的基本更删改查操作,HBase 集群体系的结构,还会谈谈 HBase 与 HDFS 之间的关系,它在读写数据时的流程,有了这些理论基础下,就可以对 HBase 的性能调优有更透彻的了解,最后会谈谈 HBase 的备份和复制 (HBase 进阶)。希望读者看完这篇文章后
- 了解 NoSQL 数据库与关系型数据库的区别;
- 了解 HBase 在功能, 设计和集群架构上的角色;
- 了解 HBase 中增删改查 API 并熟识其操作;
- 了解 HBase 与 HDFS, ZooKeeper 之间的关系;
- 了解 HBase 是如何对数据进行拆分和紧缩;
NoSQL 数据库介绍
NoSQL 数据库和关系型数据库的设计目的是为了解决不同的问题,NoSQL 数据模型相对简单,它适合应用灵活更强的 IT 系统,不需要预先定义表如构,而且 NoSQL 对数据库性能要求较高,对 PB 级别的数据进行快速的检索,不需要高度的数据一致性及廷迟性的埸景,可以快的跟据 Key-Value 的方式来查看数据。在市埸上有四种NoSQL数据库,分别是:
- 键值存储数据库:Key-Value 的鐽值对,通常用 Hash Table 来实现,这类数据库的查找速度快、简单,易部署,但数据无结构化,如果区部查找会很慢,和应用埸景是内容缓存,快速的检索数据,主要用于大量数据的高访问量负X,也适用于一些日志系统, e.g. Redis, Oracle BDB, Tokyo Cabinet;
- 列存储数据库:以列族 Column Family 式存储,将同一列数据存在一起,鐽的特点是指向了多少个列,这些列是由列族来实现的,它的好处是查找快速,扩展性非常好以便应用海量数据存储和处理,但功能相对局限,对设计要求很特定的要求,非常适合分布式文件系统 e.g. HBase、Cassandra, Accumulo, Riak;
- 文档存储数据库:Key-Value 对应的键值时,Value 为结构化数据,更了解 Value 的内容,数据结构不严格,表结构可变它不需要像关系型数据库一样要预先定义表结构,可以看作他是键值数据库的升级版,文档类型处理得力比较好,但查询能力不高,缺乏统一的查询语法。使用埸景是 Web 应用,,e.g. MongoDB, CouchDB, Couchbase Server ;
- 图形数据库:图结构,它可以提用图结构的算法,比如最佳路线寻址,N度关系查找,使用灵活的图形模型并且能扩展到不同的服务器上,但很多时候要对整个图作计算才能得出需要的信息,这种结构不太适合分布式的集群方案。应用埸景:推荐系统,社交网络和关于结构关系图谱, e.g. Neo4J, Infinite Graph;
NoSQL 与 RDBMS 的区别
[下图总结 NoSQL 和 RDBMS 的区别]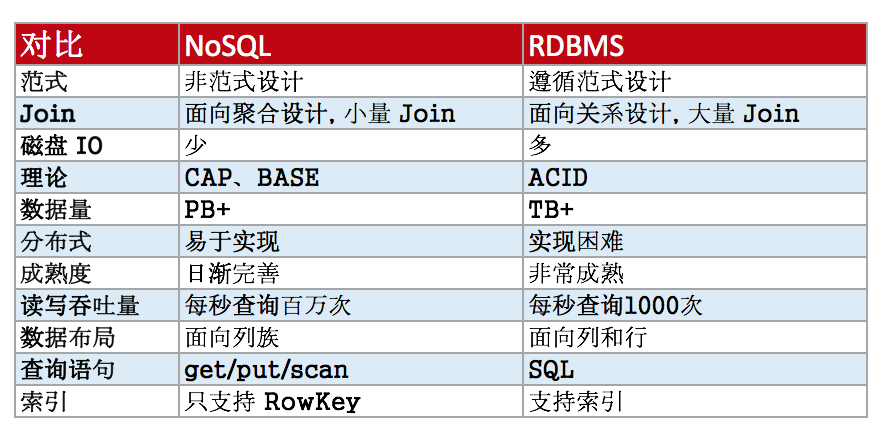
NoSQL 与 RDBMS 最大的分别是数据量和读写吞吐量的不同,数据布局和数据访问频率也不同,他们两个应用解决问题的本质也不一样,比如列存储数据库可以快速查找的原因是列族的设计可以在每一次查询中大量减少磁盘 IO 和数据量的访问。NoSQL 数据库很容易支持数据量达 PB 级别的数据,因为它的特性很容易支持分布式水平扩展;但 RDBMS 只能处理 TB+ 级别的数据,如果你的数据场景是要处理很多事务性数据 e.g. 更新和删除,那么还是优先选择关系型数据库 RBDMS,因为NoSQL数据库不太善于频繁的处理数据更新和删除,因为数据是分布在不同的节点上,还有数据是默认有三份副本,如果需要太量的更新操作,那么每台节点上的数据也有一并更新,这太太增加了解决方案的复杂性;NoSQL 遵从 CAP 和 BASE 理论,RDBMS 遵从 ACID 的理论。如果只有上千行和上百万行的数据,则用傅统数据库会比较适合
HBase 介紹
HBase 是以数据为中心,RDBMS 是以关系为数据,HBase 是 NoSQL 数据库中的列存储数据库,它有以下特点:强一致性读写,自动分片,HBase 通过 Region 分布在集群中,数据增加时,Region 会自动分割并重新分片。RegionServer 自动故障移取,HBase 支持 HDFS 之外的存储文件,HBase 通过 MapReduce 支持大并发处理,HBase 支持以 API 方式访问数据,HBase 以 Bloom Filters 和 Bloom Cache 对大量数据进行查询优化。HBase 适合场景是存在随机读写的埸景,每秒需要在 TB 级别数据上完成数以千计的操作,访问的操作的方式要简单、明确和直接,如果应用只是插入数据而且处理时需要读取全部数据。HBase 不支持二次索引、事务性数据、关联表的操作。HBase 的使用埸景:消息 (Message) 比如点赞,电商中的 SMS/ MMS,有随机读写的能力,局部数据进行 TopN 的查询、简单实体、图数据、指标。
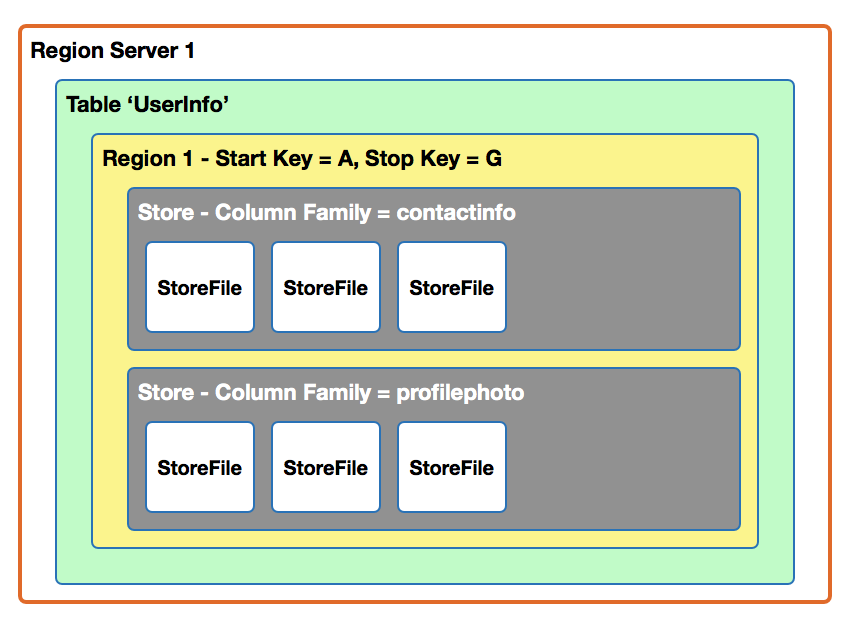
[下图是一张 HBase 的表,概括了列族、列名和行之间的关系]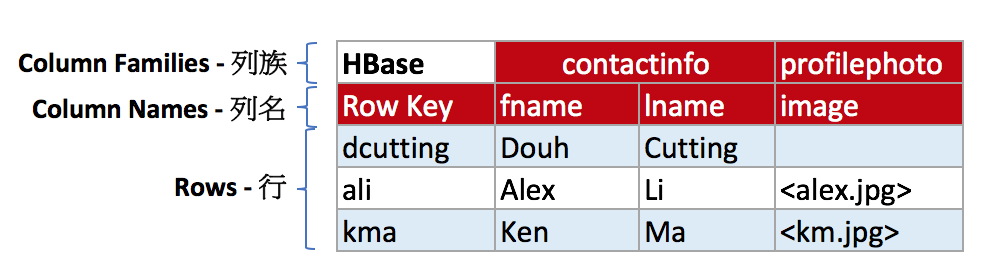
- HBase 在表中存储数据,而表数据最后存储在 HDFS 上,数据被分割成 HDFS 块 (Block) 存储在集群的多个节点上,以128G为一个 BlockSize;
- HBase 是由 Column Family (列族),Column (列) 和 Row Key (行) 组成的,列族是列的一个集合,列族可以有任意数量的列,e.g. contactinfo:fname, contactinfo:lname 它也可以单独对每个列族进行存储属性优化,比如对 profilephoto 进行压缩存储。
- HBase 每一行都有一个 RowKey 用于快速检索,来保证一行数据的完整性,每个 RowKey 就类似于 RDBMS 的主键,HBase 表是基于 RowKey 进行快速检索,行按照排序后进行存储,
- HBase 底层磁盘上是按照 Column Family 分开进行存储。这样的好处是相对于行存,占用空间会很小;
- HBase 中间的数据是存储在 Cell 中,而且 Cell 是有版本化的,可以自定义保留多少过版本,Cell 为空时不存储。
这只是一个概念模型,HBase 的物理模型在存储层面上是按照列族来存储,因此,它的设计是不建议存储太多的列在同一个列族中。
如何设计一个 HBase 的表
要设计一个 HBase 表,要考虑的有以下几个重点:RowKey 是唯一的索引键,应用程式依赖行来完成快速数据访问;RDBMS 与 HBase 的特性比较;RDBMS 与 HBase 的表设计,RowKey 的设计,列族的设计,确定数据的访问类型;RDBMS 与 HBase 的 Scham 设计:关系为中心,HBase 是以数据为中心,先确定数据的访问方式。
HBase 的 Region 是一张表,它类似于关系型数据库中 partition 的概念, Region 是通过 RegionSever 的一个守护进程来对外(客户端) 提供服务的, 表被折分为小的分区, Region 包含起始行到结束行所有的行信息,一个 RegionServer 可以有多个 Region。例如:User 表的其中一部份通过基于 RowKey 顺序的动作被拆分成三个不同的小 Region 然后随机分发在不同的 RegionServer 节点上来对外提供受务。
[下图是一张Hbase 的 User 表,描述了一张表是如何拆分成不同的 Region 然后分发给 RegionServer]
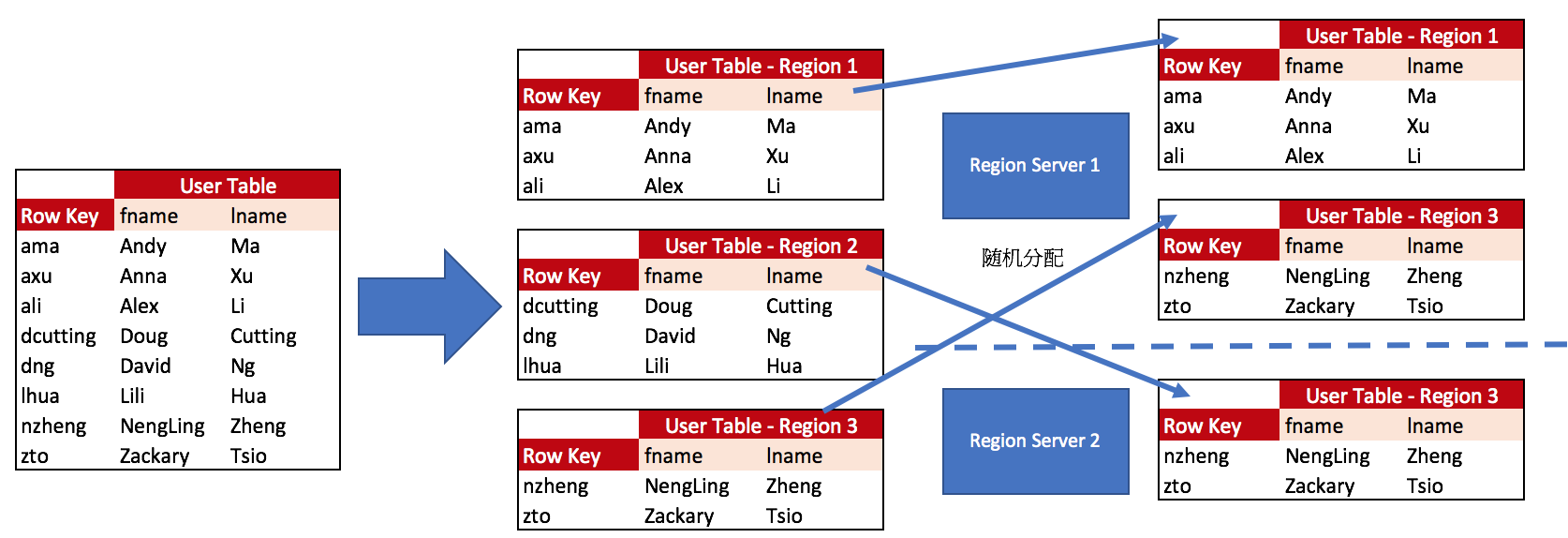
HBase 基本操作
HBase Shell 是发送命令给 HBase 的交换式 Shell,HBase 是用 JRuby 来方问,在 terminal 上输入 hbase shell 进入交换式界面。语法规则是如下:
command 'para1' 'para2'
command 'param1',{PARA2 => 'stringvalue', PARA3 => 'intvalue'}
常用的语句包括增、删、改、查分别以 put (先新增数据,发现 rowkey 相同则修改数据)、delete、get 或 scan. 以下是 put/ get/ scan/ delete 的模版语句。
HBase 存在两个自定义两个 namespace,分别是 hbase 和 default namespace。默认 hbase 是包含HBase 内部的 system namespace,如果没有显式定义 namespace 便会自动归类为 default namespace。
create_namespace 'namespaceName'
drop_namespace 'namespaceName'
alter 'namespaceName' ,{METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}


create_namespace 'entertainment' create 'entertainment:movie', {NAME => 'desc'}
- 在 HBase Shell 中执行 help 来查看帮助文档 e.g. hbase> help
helphbase(main):040:0> help HBase Shell, version 1.2.0-cdh5.9.0, rUnknown, Fri Oct 21 01:20:14 PDT 2016 Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command. Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group. COMMAND GROUPS: Group name: general Commands: status, table_help, version, whoami Group name: ddl Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters Group name: namespace Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables Group name: dml Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve Group name: tools Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_mob, compact_rs, flush, major_compact, major_compact_mob, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, trace, unassign, wal_roll, zk_dump Group name: replication Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs Group name: snapshots Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot Group name: configuration Commands: update_all_config, update_config Group name: quotas Commands: list_quotas, set_quota Group name: security Commands: grant, list_security_capabilities, revoke, user_permission Group name: procedures Commands: abort_procedure, list_procedures Group name: visibility labels Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility SHELL USAGE: Quote all names in HBase Shell such as table and column names. Commas delimit command parameters. Type <RETURN> after entering a command to run it. Dictionaries of configuration used in the creation and alteration of tables are Ruby Hashes. They look like this: {'key1' => 'value1', 'key2' => 'value2', ...} and are opened and closed with curley-braces. Key/values are delimited by the '=>' character combination. Usually keys are predefined constants such as NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type 'Object.constants' to see a (messy) list of all constants in the environment. If you are using binary keys or values and need to enter them in the shell, use double-quote'd hexadecimal representation. For example: hbase> get 't1', "keyx03x3fxcd" hbase> get 't1', "key�03�23�11" hbase> put 't1', "testxefxff", 'f1:', "x01x33x40" The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added. For more on the HBase Shell, see http://hbase.apache.org/book.html hbase(main):041:0>
- 在 HBase Shell 中查看状态和当前版本是用 status, version, e.g. hbase> status; hbase> version
status 和 versionhbase(main):036:0> status 1 active master, 0 backup masters, 3 servers, 0 dead, 1.3333 average load hbase(main):037:0> version 1.2.0-cdh5.9.0, rUnknown, Fri Oct 21 01:20:14 PDT 2016
- 在 HBase Shell 查看表是用 list,e.g. hbase> list
- 在 HBase Shell 创建表是用 create,假设有一张 movie 表,它以 row1 作为 rowKey, ColumnFamily 和 Column 分别是 desc 和 title,现在新增一条数值为 HomeAlone 的数据 e.g. hbase> create 'tablename', {NAME => 'ColumnFamilyName', VERSIONS => 5}
create 'movie'create 'movie', {NAME => 'desc'} create 'movie', {NAME => 'desc', VERSIONS => 2} create 'movie', {NAME => 'desc'}, {NAME => 'media'} create 'movie','desc','media'
- 在 HBase Shell 新增和更新数据是用 put,先新增数据,默认会插入当前服务器时间作为时间戳,发现 rowkey 相同便修改数据,把 movie 的数据更改为 HomeAlone 2,并插入时间戳 e.g. hbase> put 'tablename', 'rowkey', 'colfam:col', 'value' [,timestamp]
put 'movie'put 'movie', 'row1', 'desc:title', 'Goblin' put 'movie', 'row2', 'desc:title', 'Descendants Of The Sun' put 'movie', 'row3', 'desc:title', 'Doctors' put 'movie', 'row4', 'desc:title', 'W Special'
- 在 HBase Shell 删除数据是用 drop 但前提是要先 disbale 表,disbale 表禁用表的置可维护的状态来防止客户端的访问,允许执行各种维护命令,e.g. hbase> disable 'tablename' ; drop 'tablename'
disable and drop 'movie'hbase(main):017:0> disable 'movie' 0 row(s) in 2.2980 seconds hbase(main):018:0> drop 'movie' 0 row(s) in 1.2590 seconds
- 在 HBase Shell 查看表结构定义信息,包含所有表的列族名、属性名和属性值是用 describe, e.g. hbase> describe 'tablename'

describe 'movie'hbase(main):007:0> describe 'movie' Table movie is ENABLED movie COLUMN FAMILIES DESCRIPTION {NAME => 'desc', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BL OCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} 1 row(s) in 0.0950 seconds - 在 HBase Shell 修改表结构是用 alter, 调整表的 meta,比如可以增删改列族信息,也可以在线 Schama 调整功能,需要把以下参数调整为 true
e.g. hbase> alter 'table', ATTRIBUTE => 'new attribute value'hbase.online.schema.update.enable property = true
alter 'movie'alter 'movie', NAME => 'media', METHOD => 'delete' alter 'movie', NAME => 'desc', VERSIONS => 5 alter_async 'movie', NAME => 'desc', VERSIONS => 5 alter_status
- 在 HBase Shell 查询单条数据是用 get 可以进行单行数据根据行键检索,检索一行数据时,最近的版本时间戳最大的版本会被返回,e.g. hbase> get 'movie', 'row1'
get 'movie', 'row1'hbase(main):022:0> get 'movie', 'row1' COLUMN CELL desc:title timestamp=1502806209403, value=Goblin 1 row(s) in 0.0110 seconds get 'movie', 'row2' get 'movie', 'row2', {COLUMN => 'desc:title'} get 'movie', 'row2', {COLUMN => 'desc:title', VERSIONS => 2} get 'movie', 'row2', {COLUMN => ['desc']} - 在 HBase Shell 查询整块数据是用 scan,e.g. hbase> scan 'movie'
scan 'movie'scan 'movie' scan 'movie', {LIMIT => 3} scan 'movie', {STARTROW => 'row1', STOPROW => 'row3'} scan 'movie', {COLUMN => ['desc:title','media:type']}
- 在 HBase Shell 检查表是否被停用或启动是用 is_disabled 或者 is_enabled, e.g. hbase> is_disabled 'table'; is_enabled 'table'
is_disabled 'movie' or is_enabled 'movie'hbase(main):025:0> is_disabled 'movie' false 0 row(s) in 0.0170 seconds hbase(main):026:0> is_enabled 'movie' true 0 row(s) in 0.0130 seconds
- 在 HBase Shell 删除Cell中的数据是用 delete, e.g. hbase> delete 'tablename', 'rowkey', 'colfam:col', [,timestamp]
delete 'movie'delete 'movie', 'row2', 'desc:title', 1502806209427
- 在 HBase Shell 删除表的所有行的数据是用 truncate, 表的列族不爱影响 e.g. hbase> truncate 'movie'
- 在 HBase Shell 删除行的所有数据是用 deleteall, e.g. hbase> deleteall 'movie', 'row1'
deleteall 'movie', 'row1'hbase(main):032:0> deleteall 'movie', 'row1' 0 row(s) in 0.0300 seconds
- 在 HBase Shell 计算表的总行数是用 count, e.g. hbase> count 'movie'
count 'movie'hbase(main):031:0> count 'movie' 4 row(s) in 0.0380 seconds => 4
HBase 集群体系结构
RegionServer 是安装在 Hadoop 的 DataNode 节点上,每个 WorkerNode 都有一个 RegionServer 的进程,分配的变化都是由 HBase Master 来管理啦,HBase Master 是监控集群中所有 RegionServer 实例,它是所有元数据修改的接口界面。HBase Master 是协调众多的 Region Sever 的守护进程,确定每一个 Region Sever 管理那些 Region 的数据,新增、删除、更新数据都由产生分配变化,因此需要 HBase Master 来统一管理。HBase 集群可以配置多个 Master 来提供高可用,集群受控于一个Master,ZooKeeper 服务处理 Master 之间的协调动作。 ZooKeeper 运行在集群的 Master 节点上,启动后所有节点会连接到 ZooKeeper, 以竞争的形式运行,第一个连接到 ZooKeeper 的会获得控制权,如果主节点的 Master 乏败后,剩下的 Master 会竞争控制权
HBase 有两大类的表,一类是 UserSpace,这是通过 HBase Shell 和 HBase API 创建的表,记录了真正用户创建的表,e.g. Moive, UserInfo;另外一种是 Catalog 表,它只有 HBase 系统访问的表,它的用途是记录元数据的特定表,跟踪并记录 Region 和 Region Sever 的位置,hbase:meta 是一张 HBase 的表,但不可以通过 HBaseShell 的 list 命令查找,HBase Master 通过 ZooKeeper 能够快从 hbase:meta 定位并查找元数据表的位置。
假设现在用户以 HBase Shell 创建了一张 UserInfo 的表, HBase 会通过以下几个步骤来查找 HBase 的数据:
[下图是HBase 如何经过 hbase:meta 表来查找数据]
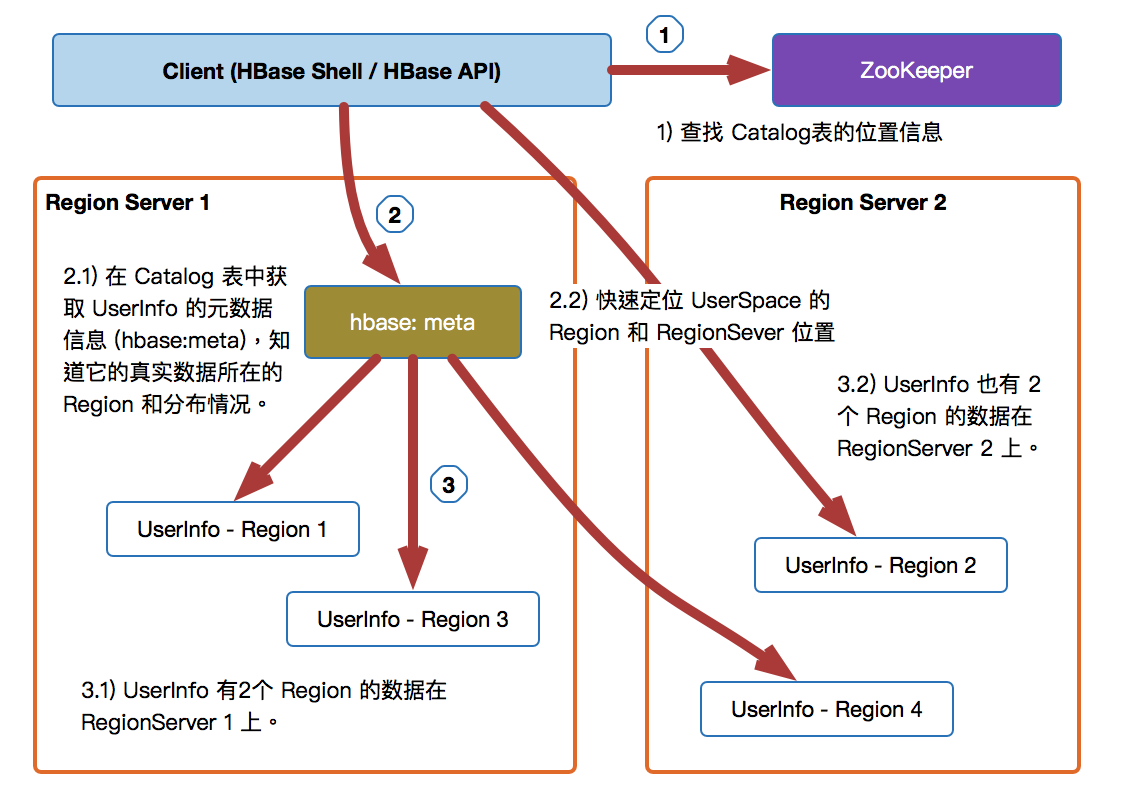
- 第一步:客户端会首先连接 ZooKeeper 来查询 hbase:meta 表元数据的位置;
- 第二步:查询 hbase:meta 表的元数据内容,来指定所有 Region 和它们的位置 (一张 UserInfo 表的数据会被拆分成不同的 Region,但 hbase:meta 不会被拆分到不同的节点上,希望hbase:meta 是可以集中式管理以便快速找到 meta 表的信息和检索。)
- 第三步:然后查询包含 UserInfo 表数据的 Region 所在的 Region Sever,这样就可以获取到数据内容并返回给客户端,前两步的查询会在客户端进行缓存,以便快速查找数据。
HBase 与 HDFS 的关系
HBase 的 RegionServer 将数据写入 HDFS 的本地磁盘上,这样就可以使用 HDFS 存储所有表的数据,而且 Region 是以文件的形式存储在 HDFS 之上,它继承了 HDFS 的特性其中包括 NameNode 避免了单点故障提供了高可用性,DataNode 上存储了三个数据副本保障了数据的持久性和确保如果节点出现故障也可以保护数据的可用性,可以通过添加 DataNode 来提高数据存储的线性扩展能力,在 HDFS 的任意位置都可以写读Region 的数据,允计 RegionServer 运行在集群的任何位置上。
[下图是 DataNode 与 RegionServer 在 WorkerNode 实现数据本地性的概念图 ]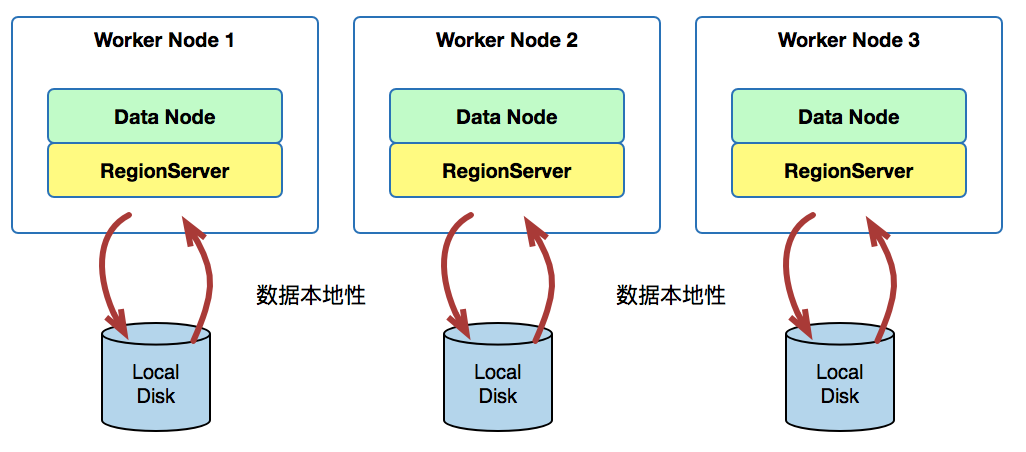
HBase 存储在 HDFS 是以 HFile 的特定文件格式,它构成表的实际存储文件,Region 的列是根据表中不同的列族被分开存储,每个表在 RegionServer 上是以 StoreFile 的形式存储,它在 HDFS 是不同的独立文件
HBase 数据拆分和紧缩
数据拆分
HBase 是如何进行数据拆分的? 当表在拆分的过程中,会创建额外的两个列 info:splitA 和 info:splitB,它代表两个 daughter region,这两个列的值会序列化 HRegionInfo 实列,Region 分割完毕后,这两行会自动删除。然后创建两个 daughter reference 文件,daughter 文件只包含 region 拆分的位置的键,在主紧缩中原始数据文件会被重新写成新 Region 目录下的单独文件,小的 reference 文件和原始 Region 则会被删除掉。
[下图是一个 Region (Start Key A 到 Start Key G) 拆分成两个Region: Region1 (Start Key A 到 Start Key C) 和 Region2 (Start Key C 到 Start Key G) 的过程]
什么时候会独发拆分?当有大量的新增数据到一个 Region 时,RegionServer 感知到数据量超过了预值,便会独发 Region 拆分,在拆分过程中要注意有以下几点:
- 此时的 Region 是不能对外提供服务的,快完成整个拆分的动作
- 复制和拷贝动动是不可进行的
- RegionServer 会更新 hbase:meta 元数据信息
- Region 拆分完毕
Region 大小可以基于每一张表设置,某些表的需要与默设置的 Region 大小不同时,通过 HTableDescriptior 和 setFileSize 事件设置,Region 的大小是容量可用性和分布性的基本单位,所以不建议太小的数据分布到过多的 Region 中,高 RegionCount 会影响性能,例如超过 3000 Count,但低 RegionCount 也会降低并行扩展能力,建议:每一个 RegionServer 包含 20~小几百个 Region。RegionServer 会自动移动 Region 来实现集群的负载均衡,负载均衡操作的时间是由 hbase.balancer.period 来设置的,默认是 300000 ms (5分钟)。
小紧缩与主紧缩
HBase 是如何进行紧缩的?紧缩的目的是把几个小的 StoreFile 合并为一个大的文件,来减少因为需要管理过多的小文件而导的资源开销,通常是3个小的 StoreFile 就会触发一次 Minor Compression,可以适当地控制 StoreFile 的数量。可以通过 hbase.hstore.compactionThreshold,数值较大会导致紧锁更少,但是每次紧锁耗的时间更长,在紧锁期间,Memstore 无法刷新磁盘,此时如果 memstore 的内存耗尽,客户端就会导致阻塞或者是超时。
[下图是多个 StoreFile 小文件经过小紧缩后合并成了三个小的 StoreFile]
主紧缩 (major compaction), 读取一个 Region 中所有 StoreFile 并且将其写到一个 StoreFile,之前标示删除的数据和旧版本的数据都会在物理层面上被清除掉,主紧缩默应是一周 (七天) 进行一次,可以通过参数 hbase.hregion.majorcompaction 配置主紧缩的时间间隔 (单位是毫秒),当该参数设置为 0 时表示禁用主紧缩,因为主紧缩是非常耗资源的,所以建议是以交错的方法为每个 RegionServer 进行主紧缩,这样可以防止全部 RegionServer 在同一个时间内进行主紧缩。
[下图是三个 StoreFile 经过主紧缩后合并成了一个大的 StoreFile]
在生产环境下主紧缩的最佳实践:
- 因为主紧缩是一个非常耗资源的操作,所以建议在负载比较低的时候运行;
- 通过参数 hbase.hregion.majorcompaction 调大主紧缩的间隔时间 (单位是毫秒),同时使用脚本来执行主紧缩操作,如果脚本失败,需将这个参数的值设置为 0,当然这种设置同时会出现主紧缩永不发生的风险;
- 通过参数 hbase.hregion.majorcompaction.jitter 来确保不让所有 RegionServer 上的主紧缩操作同时进行,默应是 0.5 (50%),每一个 RegionServer 的 hbase.hregion.majorcompaction 参数的值乘以一个随机的分数 (这个随机分数取值区间不超过 jitter) 和hbase.hregion.majorcompaction 参数的值加或减这个值来确定下一次主紧缩的运行时间。
例子:通过 hbase.hregion.majorcompaction x hbase.hregion.majorcompaction.jitter 两个参数的结合来防止各个 RegionServer 上的主紧缩操作在同一个时间点上发生,假设主紧缩每7天进行一次,然后乘以 jitter 这个随机分数 e.g. 0.5。7 天 x (0~0.5) = 0 ~ 3.5 天。然后把 7天加或者减这个值 e.g. (7天-3.5) ~ (7天+3.5) = 3.5天 ~ 10.5 天,便会计算出下一次主紧缩发生的时间。在这个例子中,每个 3.5 天到 10.5 天便会触发一次主紧缩行为。
RegionServer 最终目的是要实现数据本地化,才能够快速查找数据,HDFS 客户端默认拷贝三份数据副本,其中第一份副本写到本地节点上,第二和第三份则写在不同机器的节点上 (RegionServer);Region 的拆分会导致 RegionServer 需要读取非本地的 StoreFile,此时,HDFS 将会自动通过网络拉取数据,但通过网络读写数据相对地比本地读写数据的效率要低,要提升效率,必须尽可能采用数据本地性,这也是为什么 HBase 要不定时地进行主紧缩和刷新把数据聚合在本地磁盘上来实现数据本地化,提升查询效率。
总结
NoSQL 数据库与关系型数据库有著本质的设计与功能差别,两者之间的使用的埸景和需求都不一样。关系型数据库善于处理结构化数据和频繁地对数据进行更新和删除的操作,设计模型是以关系为中心的,有一系列的功能包含提供索引,很容易实现二次排序,数据分片、可以实现大量的关联操作,针对事务性数据有良好的支持,不过比较难实现分布式扩展和只能支持 TB+ 以上的数据量。NoSQL 数据库是以数据为中心,没有过多对表结构的规范,比如不需要在创建表之前先定义整个表结构,只需要定义列族和行信息即可,NoSQL 数据库很容易实现分布式扩展且能支持 PB+ 以上的数据量,因为分布式和灵活的表设计,NoSQL 的应用埸景是适合快速随机读写数据,但它是不支持事务性数据,e.g. CUID (增删改查),所以NoSQL 数据库与关系型数据库是不能完全替代的,只是为不同的需求提出不同的解决方案。
HBase 的架构也是 Master-Slave 结构,HBase Master 负责协调各个节点的工作,在每个工作节点上都布署了一个 RegionServer,负责对外提供服务。HBase 的表是以 Region 概念来拆分,一张表可以拆分为不同的 Region 然后分发到不同的 RegionServer 上,每个表在创建时只需要定义列族,HBase 是以列族形式分开存储在 HDFS 上。
HBase 有拆分和紧缩机制,当数据量达到一个预值上限时,便会触发拆分操作,每个 Region 上有很多小的 StoreFile,当 StoreFile 达到一定数量,也会触发一次小紧缩,紧缩的目的是把几个小的 StoreFile 合并为一个大的文件,来减少因为需要管理过多的小文件而导的资源开销,每一段时间过后,也需要进行主紧缩,主紧缩会读取一个 Region 中所有 StoreFile 并且将其写到一个 StoreFile,因为 RegionServer 最终目的是要实现数据本地化来提高数据的检索速度,所以要透过紧缩的操作来达到这个效果。