一、云计算的前世今生
1、物理机架构,应用部署和运行在物理机上
2、虚拟化架构,物理机上运行若干虚拟机,应用系统直接部署到虚拟机上
3、云计算架构,虚拟化提高了单台物理机的资源使用率
二、OpenStack 简介
1、什么是云计算:云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务)
2、云计算所包含的几个层次服务
SaaS( Software as a Service): 把在线软件作为一种服务。
PaaS( Platform as a Service): 把平台作为一种服务。
IaaS( Infrastructure as a Service):把硬件设备作为一种服务。
3、OpenStack:
1)是由Rackspace和NASA共同开发的云计算平台是一个开源的IaaS(基础设施及服务)云计算平台,让任何人都可以自行建立和提供云端运算服务
2)每半年发布一次
3)用Python语言编写
三、OpenStack社区与链接
如何参与openstack社区
1、社区 www.openstack.org, wiki.openstack.org
2、邮件列表
http://wiki.openstack.org/MailingLists#Development_List
http://wiki.openstack.org/MailingLists#General_List
http://wiki.openstack.org/MailingLists#Operators
3、IRC #openstack on Freenode
OpenStack Meeting http://wiki.openstack.org/Meetings
4、如何贡献代码 http://wiki.openstack.org/HowToContribute
5、源代码管理 http://wiki.openstack.org/GerritWorkflow
6、文档 http://docs.openstack.org
四、openstack架构及优势
1、openstack架构:
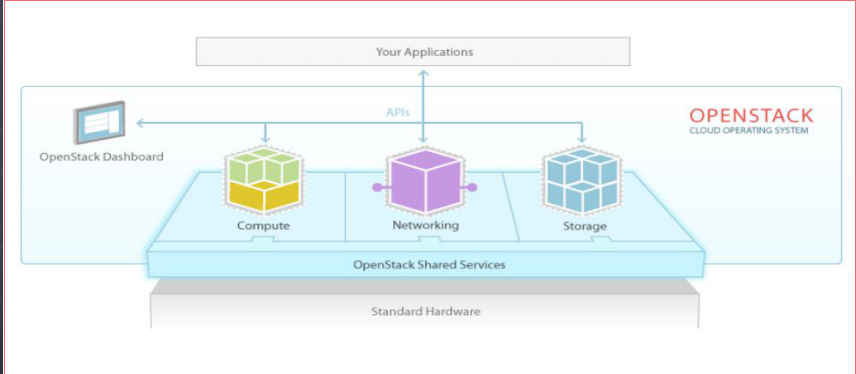
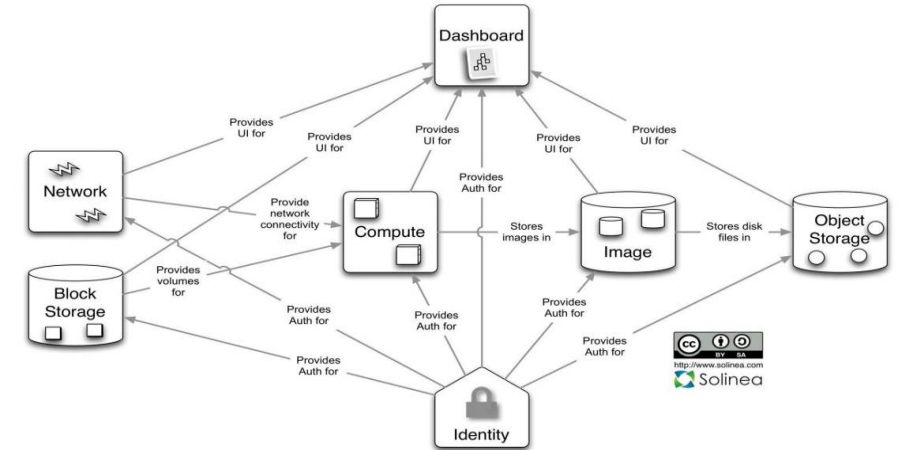

2、OpenStack优势:
OpenStack为私有云和公有云提供可扩展的弹性的云计算服务,这种服务云必须是简单部署并且扩展性强
1、模块松耦合
2、组件配置较为灵活
3、二次开发容易
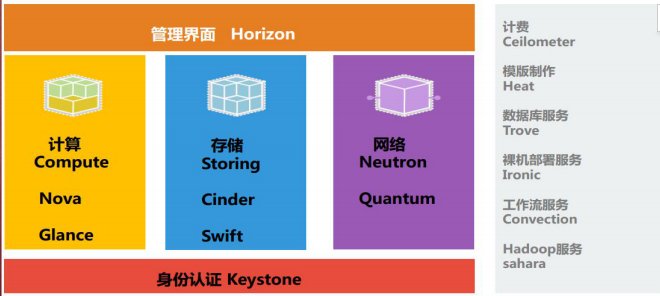
五、openstack构成组件
1、OpenStack共享服务组件:
数据库服务( Database Service ):MairaDB 及MongoDB
消息传输(Message Queues):RabbitMQ
缓存(cache): Memcached
时间(time sync):NTP
存储(storge provider):ceph、GFS、LVM、ISICI等
高可用及负载均衡:pacemaker、HAproxy、keepalive、lvs等
2、OpenStack核心组件:
身份服务( Identity Service ):Keystone
计算( Compute ): Nova
镜像服务( Image Service ): Glance
网络 & 地址管理( Network ): Neutron
对象存储( Object Storage ): Swift
块存储 (Block Storage) : Cinder
UI 界面 (Dashboard) : Horizon
测量 (Metering) : Ceilometer
部署编排 (Orchestration) : Heat
六、ntp时钟同步服务
1、为什么要有时间同步服务:
随着时间的误差,有些工作是无需进行时间精确即可以完成。但有些工作就必须精确时间从而可以完成目标任务。
因此时间的同步有了需求。目前所使用的就是 Network Time Protocol 协。即网络时间协议
2、ntp时钟同步服务:
1.NTP 工作请求
1)客户端将采用随机端口向 NTP 服务器 (UDP:123) 发出时间同步请求
2)NTP 服务器收到请求后会将发出调校时间
3)NTP 客户端接收到 NTP 服务器的消息后,以进行调整,从而完成时间同步
2.同步服务器时间方式有2个:一次性同步(手动同步)、通过服务自动同步。
1)一次性同步时间:ntpdate 时间服务器的域名或ip地址
Ip地址查看可以访问:http://www.ntp.org.cn/pool.php
ntpdate 120.25.108.11(选择阿里云的)
3.NTP 服务器实现
1)NTP 服务器安装
# yum install ntp -y
2)查看 NTP 配置文件是否存在
# ls -l /etc/ntp.conf
3)NTP 所涉及的程序
ntpd
ntpdate
tzdata-update
4)相关时间程序
date
hwclock
5)NTP 所涉及文件
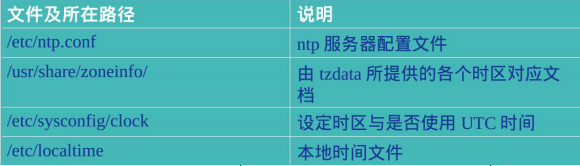
6)NTP 服务
NTP 服务属于 C/S 架构模式 , 在建立本地服务时最好与上层服务器进行时间同步来给本地提供时间同步服务
ntp.conf 说明
restrict 来管理 NTP 权限控制
用法 : restrict [ip] mask [netmask] parameter

server 进行设置上端同步 NTP
用法 : server [ip or hostname] [prefe]

让本地的ntpd与本地硬件时间同步
# vim /etc/ntp.conf :
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
# systemctl start ntpd
7)Linux 客户端同步
1) 手动同步
ntpdate 192.168.1.100
2) 实时同步
# vim /etc/ntp.conf
server 192.168.1.100(同步服务端ip的时间)
# systemctl start ntpd
8)查看上层 NTP 服务状态
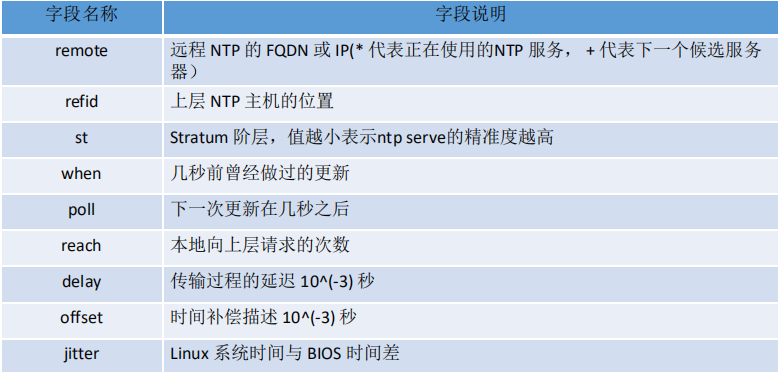
ntpq –p
七、Rabbitmq 消息队列
1、Rabbitmq 消息队列:
MQ 全称为 Message Queue, 消息队列( MQ )
是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
AMQP 即 Advanced Message Queuing Protocol:
高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布 / 订阅)、可靠性、安全。
2、Rabbitmq概念:
1.属于一个流行的开源消息队列系统。属于AMQP( 高级消息队列协议 ) 标准的一个 实现。是应用层协议的一个开放标准,为面向消息的中间件设计。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
2.消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
3.AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布 / 订阅)、可靠性、安全。
3、RabbitMQ特点:
§ 使用Erlang编写
§ 支持持久化
§ 支持HA
§ 提供C# , erlang,java,perl,python,ruby等的client开发端
4、RabbitMQ中的概念名词:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字, exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个
channel代表一个会话任务
5、RabbitMQ工作原理:
MQ 是消费 - 生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取或者订阅队列中的消息。 MQ 则是遵循了 AMQP协议的具体实现和产品。在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量

1)客户端连接到消息队列服务器,打开一个channel。
2)客户端声明一个exchange,并设置相关属性。
3)客户端声明一个queue,并设置相关属性。
4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
5)客户端投递消息到exchange。
6) exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里
6、Rabbitmq 的 metadata:
元数据可以持久化在 RAM 或 Disc. 从这个角度可以把 RabbitMQ 集群中的节
点分成两种 :RAM Node和 Disk Node.
RAM Node 只会将元数据存放在RAM
Disk node 会将元数据持久化到磁盘。
单节点系统就没有什么选择了 , 只允许 disk node, 否则由于没有数据冗余一旦重启就会丢掉所有的配置信息 . 但在集群环境中可以选择哪些节点是 RAM node. 在集群中声明 (declare) 创建 exchange queue binding, 这类操作要等到所有的
节点都完成创建才会返回 :
如果是内存节点就要修改内存数据 ,
如果是 disk node 就要等待写磁盘 , 节点过多这里的速度就会被大大的拖慢
只要有一个节点是 Disc Node 就能提供条件把集群元数据写到磁盘 ,RabbitMQ 的确也是这样要求的 : 集群中只要有一个 disk node 就可以 , 其它的都可以是 RAM node. 节点加入或退出集群一定至少要通知集群中的一个 disk node
八、Memcache 缓存系统
1、缓存系统:
在大型海量并发访问网站及openstack等集群中,对于关系型数据库,尤其是大型关系型数据库,如果对其进行每秒上万次的并发访问,并且每次访问都在
一个有上亿条记录的数据表中查询某条记录时,其效率会非常低,对数据库而言,这也是无法承受的。
缓冲系统的使用可以很好的解决大型并发数据访问所带来的效率低下和数据库压力等问题,缓存系统将经常使用的活跃数据存储在内存中避免了访问重复数据时,数据库查询所带来的频繁磁盘i/o和大型关系表查询时的时间开销,因此缓存系统几乎是大型网站的必备功能模块。
缓存系统可以认为是基于内存的数据库,相对于后端大型生产数据库而言基于内存的缓存数据库能够提供快速的数据访问操作,从而提高客户端的数据请求访问反馈,并降低后端数据库的访问压力。
2、Memcached概念:
Memcached 是一个开源的、高性能的分布式内存对象缓存系统。通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站访问速度,加速动态WEB应用、减轻数据库负载。
Memcached是一种内存缓存,把经常需要存取的对象或数据缓存在内存中,内存中,缓存的这些数据通过API的方式被存取,数据经过利用HASH之后被存放到位于内存上的HASH表内,HASH表中的数据以key-value的形式存放,由于Memcached没有实现访问认证及安全管理控制,因此在面向internet的系统架构中,Memcached服务器通常位于用户的安全区域。
当Memcached服务器节点的物理内存剩余空间不足,Memcached将使用最近最少使用算法(LRU,LastRecentlyUsed)对最近不活跃的数据进行清理,
从而整理出新的内存空间存放需要存储的数据。
Memcached在解决大规模集群数据缓存的诸多难题上有具有非常明显的优势并且还易于进行二次开发,因此越来越多的用户将其作为集群缓存系统,此 外,Memcached开放式的API,使得大多数的程序语言都能使用Memcached,如javac、C/C++C#,Perl、python、PHP、Ruby 各种流行的编程语言。
由于Memcached的诸多优势,其已经成为众多开源项目的首选集群缓存系统。如openstacksd的keystone身份认证项目。就会利用Memcached来缓存租的 Token等身份信息,从而在用户登陆验证时无需查询存储在MySQL后端数据库中的用户信息,这在数据库高负荷运行下的大型openstack集群中能够极大地提高用户的身份验证过程,在如web管理界面Horizon和对象存储Swift项目也都会利用Memcached来缓存数据以提高客户端的访问请求响应速率。
3、Memcached缓存流程:
1)检查客户端请求的数据是否在 Memcache中,如果存在,直接将请求的数据返回,不在对数据进行任何操作。
2)如果请求的数据不在 Memcache 中,就去数据库查询,把从数据库中获取的数据返回给客户端,同时把数据缓存一份 Memcache 中
3)每次更新数据库的同时更新 Memcache中的数据库。确保数据信息一致性。
4)当分配给 Memcache 内存空间用完后,会使用LRU(least Recently Used ,最近最少使用 ) 策略加到其失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据。
4、Memcached功能特点:
1)协议简单
2)基于 libevent 的事件处理
3)内置的内存管理方式
4)节点相互独立的分布式
5、使用Memcached应该考虑的因素:
1)Memcached服务单点故障
2)存储空间限制
3)存储单元限制
4)数据碎片
5)利旧算法局限性
6)数据访问安