Spark和Hadoop作业之间的区别
熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce Task,如下图所示:

而在Spark中,也有Job概念,但是这里的Job和Mapreduce中的Job不一样,它不是作业的最高级别的粒度,在它只上还有Application的概念。我们先来看看Spark文档是怎么定义Application,Task ,Job和Stage的:

一个Application和一个SparkContext相关联,每个Application中可以有一个或多个Job,可以并行或者串行运行 Job。Spark中的一个Action可以触发一个Job的运行。在Job里面又包含了多个Stage,Stage是以Shuffle进行划分的。在 Stage中又包含了多个Task,多个Task构成了Task Set。他们之间的关系如下图所示:
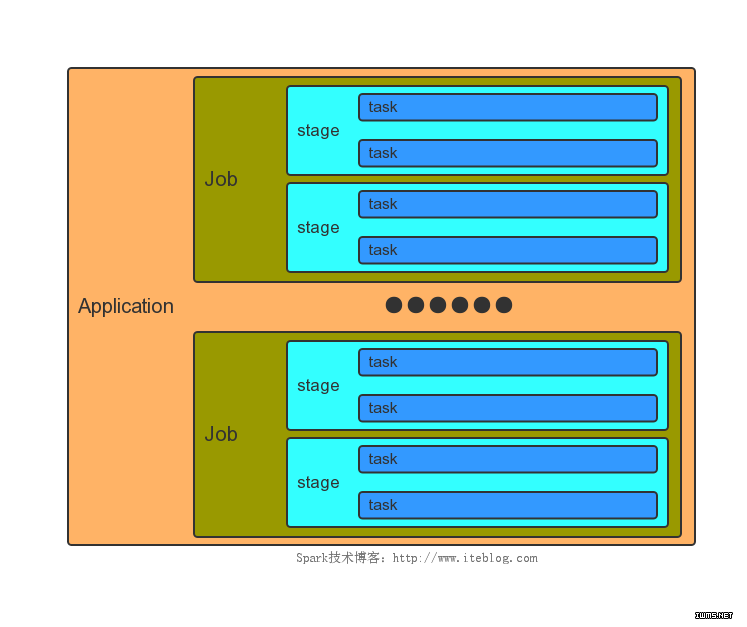
Mapreduce中的每个Task分别在自己的进程中运行,当该Task运行完的时候,该进程也就结束了。和Mapreduce不一样的 是,Spark中多个Task可以运行在一个进程里面,而且这个进程的生命周期和Application一样,即使没有Job在运行。
这个模型有什么好处呢?可以加快Spark的运行速度。Tasks可以快速地启动,并且处理内存中的数据。但是这个模型有的缺点就是粗粒度的资源管理,每个Application拥有固定数量的executor和固定数量的内存。
ref:转载自过往记忆(http://www.iteblog.com/)