sed - stream editor for filtering and transforming text
过滤和转换文本的流处理器
sed按顺序逐行读取文件。然后,它执行为该行指定的所有操作,并在完成请求的修改之后的内容显示出来,也可以存放到文件中。
完成了一行上的所有操作之后,它读取文件的下一行,然后重复该过程直到它完成该文件。
在这里要注意一点,源文件(默认地)保持不被修改。sed 默认读取整个文件并对其中的每一行进行修改。说白了就是一行一行的操作。
主要用作替换
sed --help
[root@node0 ~]# sed --help
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file].. #支持单个脚本,如果有多个命令使用-e或-f
-n, --quiet, --silent 取消自动打印模式空间,仅显示script处理后的结果
suppress automatic printing of pattern space
-e script, --expression=script 以选项中的指定的script来处理输入的文本文件
add the script to the commands to be executed
-f script-file, --file=script-file 以选项中指定的script文件来处理输入的文本文件
add the contents of script-file to the commands to be executed
--follow-symlinks
follow symlinks when processing in place; hard links
will still be broken.
-i[SUFFIX], --in-place[=SUFFIX] 修改源文件
edit files in place (makes backup if extension supplied).
The default operation mode is to break symbolic and hard links.
This can be changed with --follow-symlinks and --copy.
-c, --copy
use copy instead of rename when shuffling files in -i mode.
While this will avoid breaking links (symbolic or hard), the
resulting editing operation is not atomic. This is rarely
the desired mode; --follow-symlinks is usually enough, and
it is both faster and more secure.
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
--help display this help and exit 显示帮助
--version output version information and exit 显示版本
If no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read.
COMMAND SYNOPSIS
Zero-address ''commands''
: label
Label for b and t commands.
#comment
The comment extends until the next newline (or the end of a -e script fragment).
} The closing bracket of a { } block.
Zero- or One- address commands
= Print the current line number. 打印行号
a 在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用""续行
text Append text, which has each embedded newline preceded by a backslash.
i 在当前行之前插入文本。多行时除最后一行外,每行末尾需用""续行
text Insert text, which has each embedded newline preceded by a backslash.
q [exit-code]
Immediately quit the sed script without processing any more input, except that if auto-print is not disabled the
current pattern space will be printed. The exit code argument is a GNU extension.
Q [exit-code]
Immediately quit the sed script without processing any more input. This is a GNU extension.
r filename
Append text read from filename.
R filename
Append a line read from filename. Each invocation of the command reads a line from the file. This is a GNU
extension.
Commands which accept address ranges
{ Begin a block of commands (end with a }).
b label
Branch to label; if label is omitted, branch to end of script.
t label
If a s/// has done a successful substitution since the last input line was read and since the last t or T com-
mand, then branch to label; if label is omitted, branch to end of script.
T label
If no s/// has done a successful substitution since the last input line was read and since the last t or T com-
mand, then branch to label; if label is omitted, branch to end of script. This is a GNU extension.
c
text Replace the selected lines with text, which has each embedded newline preceded by a backslash.
d Delete pattern space. Start next cycle. 删除行
D Delete up to the first embedded newline in the pattern space. Start next cycle, but skip reading from the input
if there is still data in the pattern space.
h H Copy/append pattern space to hold space.
g G Copy/append hold space to pattern space. 在行内进行全局替换
x Exchange the contents of the hold and pattern spaces.
l List out the current line in a ''visually unambiguous'' form.
l width
List out the current line in a ''visually unambiguous'' form, breaking it at width characters. This is a GNU
extension.
n N Read/append the next line of input into the pattern space. 读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理
p Print the current pattern space. 打印行
P Print up to the first embedded newline of the current pattern space.
s/regexp/replacement/ 用一个字符串替换另一个
Attempt to match regexp against the pattern space. If successful, replace that portion matched with replace-
ment. The replacement may contain the special character & to refer to that portion of the pattern space which
matched, and the special escapes 1 through 9 to refer to the corresponding matching sub-expressions in the
regexp.
w filename
Write the current pattern space to filename.
W filename
Write the first line of the current pattern space to filename. This is a GNU extension.
y/source/dest/
Transliterate the characters in the pattern space which appear in source to the corresponding character in dest.
Addresses
Sed commands can be given with no addresses, in which case the command will be executed for all input lines; 不给地址,作用在所有行上
with one address, in which case the command will only be executed for input lines which match that address; 给一个地址,只作用在给定行
or with two addresses, in which case the command will be executed for all input lines which match the inclusive range of lines starting from the first address and continuing to the second address. 给两个地址,作用域为第一个地址到第二个地址
Three things to note about address ranges:
the syntax is addr1,addr2 (i.e., the addresses are separated by a comma); 语法为逗号分隔的两个地址
the line which addr1 matched will always be accepted, even if addr2 selects an earlier line; 第一个地址总会被执行,及时第二个地址比第一个小
and if addr2 is a regexp, it will not be tested against the line that addr1 matched.
After the address (or address-range), and before the command, a ! may be inserted, which specifies that the command shall only be executed if the address (or address-range) does not match. 在地址后,command前,加一个叹号表示只有不匹配的地址行上才执行command
The following address types are supported:
number Match only the specified line number.
first~step 从第一个地址开始,步长为step的行
Match every step'th line starting with line first. For example, ''sed -n 1~2p'' will print all the odd-numbered
lines in the input stream, and the address 2~5 will match every fifth line, starting with the second. first can
be zero; in this case, sed operates as if it were equal to step. (This is an extension.)
$ Match the last line. $表示最后一行
/regexp/ 匹配满足正则表达式的行
Match lines matching the regular expression regexp.
cregexpc
Match lines matching the regular expression regexp. The c may be any character.
GNU sed also supports some special 2-address forms:
0,addr2 从第一个地址到第二个地址
Start out in "matched first address" state, until addr2 is found. This is similar to 1,addr2, except that if
addr2 matches the very first line of input the 0,addr2 form will be at the end of its range, whereas the 1,addr2
form will still be at the beginning of its range. This works only when addr2 is a regular expression.
addr1,+N 匹配第一个地址行,及以后N行,共N+1行
Will match addr1 and the N lines following addr1.
addr1,~N
Will match addr1 and the lines following addr1 until the next line whose input line number is a multiple of N.
REGULAR EXPRESSIONS
POSIX.2 BREs should be supported, but they aren't completely because of performance problems. The sequence in a
regular expression matches the newline character, and similarly for a, , and other sequences.
示例
p 打印行
只打印第三行
[root@node0 ~]# sed -n '3p' /etc/passwd
daemon:x:2:2:daemon:/sbin:/sbin/nologin
打印第三到第九行
[root@node0 ~]# sed -n '3,9p' /etc/passwd
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
过滤特定字符串,打印,类似grep
[root@node0 ~]# sed -n '/root/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
显示包含root到包含bin之间的行
1root:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
11operator:x:11:0:operator:/root:/sbin/nologin
12games:x:12:100:games:/usr/games:/sbin/nologin
打印最后一行
[root@node0 tmp]# sed -n '$p' /tmp/passwd
34view:x:500:500:view.localhost:/home/view:/bin/bash
= 打印行号
[root@node0 tmp]# sed '=' passwd
1
1root:x:0:0:root:/root:/bin/bash
2
2bin:x:1:1:bin:/bin:/sbin/nologin
3
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
4
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6
6sync:x:5:0:sync:/sbin:/bin/sync
7
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8
8halt:x:7:0:halt:/sbin:/sbin/halt
9
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
a 在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用""续行
[root@node0 tmp]# sed '3a after 3' passwd
1root:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
after 3
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6sync:x:5:0:sync:/sbin:/bin/sync
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8halt:x:7:0:halt:/sbin:/sbin/halt
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
i 在当前行之前插入文本。多行时除最后一行外,每行末尾需用""续行
[root@node0 tmp]# sed '3i before 3' passwd
1root:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
before 3
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6sync:x:5:0:sync:/sbin:/bin/sync
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8halt:x:7:0:halt:/sbin:/sbin/halt
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
d 删除行
删除第三行
sed '3d' passed
删除第三行到第九行
[root@node0 tmp]# sed '3,9d' passwd
1root:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
删除最后一行
sed '$d' passwd
删除第2行到末尾的所有行
sed '2,$d' passwd
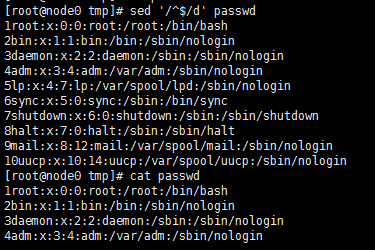
删除空白行
sed '/^$/d' passwd
s/regexp/replacement/ 用一个字符串替换另一个,替换一次
[root@node0 tmp]# sed 's/root/ROOT/' passwd
1ROOT:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6sync:x:5:0:sync:/sbin:/bin/sync
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8halt:x:7:0:halt:/sbin:/sbin/halt
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
g G 在行内进行全局替换
[root@node0 tmp]# sed 's/root/ROOT/g' passwd
1ROOT:x:0:0:ROOT:/ROOT:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6sync:x:5:0:sync:/sbin:/bin/sync
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8halt:x:7:0:halt:/sbin:/sbin/halt
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
-e 执行多个任务
[root@node0 tmp]# sed -n -e '1,5p' -e 's/root/ROOT/' passwd
1root:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-n 取消自动打印模式空间
[root@node0 tmp]# sed '3p' passwd
1root:x:0:0:root:/root:/bin/bash
2bin:x:1:1:bin:/bin:/sbin/nologin
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
4adm:x:3:4:adm:/var/adm:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6sync:x:5:0:sync:/sbin:/bin/sync
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8halt:x:7:0:halt:/sbin:/sbin/halt
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
[root@node0 tmp]# sed -n '3p' passwd
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
打印奇数行
[root@node0 tmp]# sed -n '1~2p' passwd
1root:x:0:0:root:/root:/bin/bash
3daemon:x:2:2:daemon:/sbin:/sbin/nologin
5lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
7shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
9mail:x:8:12:mail:/var/spool/mail:/sbin/nologin