作业5——多线程电梯
设计框架——UML协作时序图
(想看大图的话 crtl+滚轮 比较方便)
我为什么不用UML协作图(Communication Diagram),而是用UML时序图(Sequence Diagram)。
一方面,这样横平竖直的图更加直观美观。另一方面,使用Eclipse的plantUML插件能够比较方便地生成时序图。虽然从二者的区别上看:
时序图主要侧重于对象间消息传递在时间上的先后关系,
而协作图表达对象间的交互过程及对象间的关联关系。
协作图似乎能够更好地描述线程之间的协作关系,但是我发现有些软件是可以自动由时序图生成协作图的,这说明二者本质上描述的东西是一样的,只不过传达的角度有所侧重。相信聪明的你一定能够多角度看问题嘿嘿嘿~
【插播一则 eclipse的plantUML插件安装和使用方法】—— 摘自 http://www.importnew.com/24706.html
1. 安装:
PlantUML for Eclipse 插件主要用于在 Eclipse 中使用 PlantUML。在 Eclipse 的插件市场中安装,点击 Help --> Install new software --> add --> 起个帅气的name,location中输入网址:http://plantuml.sourceforge.net/updatesitejuno/ --> 其它安装操作
2. 点击“Window/Show View/Other..”,可以将 PlantUML 预览窗口面板显示出来。
然后我自己摸索了下就这样做了:在eclipse中右键工程--> New --> Untitled Text File (就是在工程文件夹下建了一个txt)。
在txt中按照一定的语法编写代码就能够在PlantUML 预览窗口中实时看到对应的时序图。像这样:
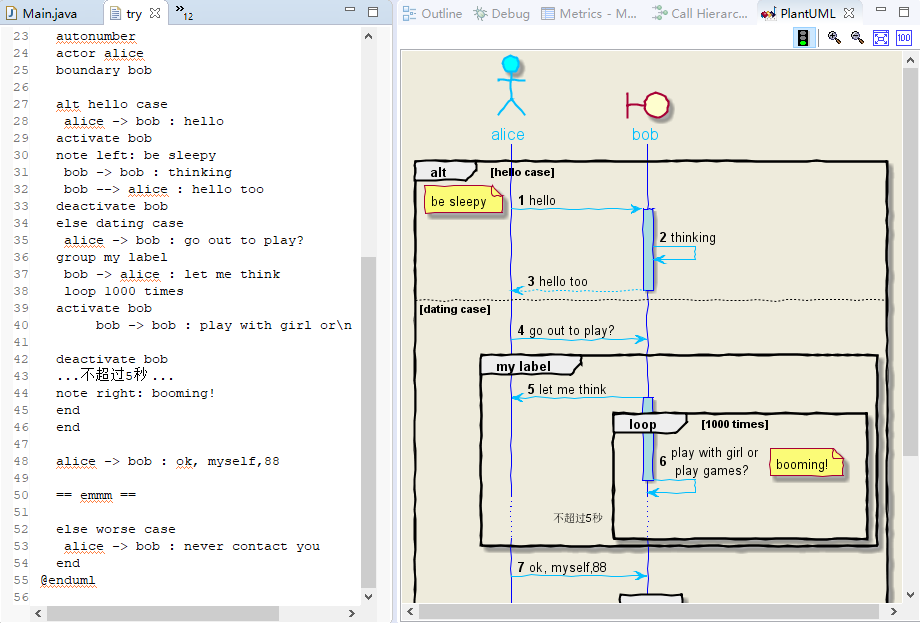
3. 所以编写代码的语法是什么呢?超简单的!
官方教程文档(中文):
http://translate.plantuml.com/zh/PlantUML_Language_Reference_Guide_ZH.pdf
【插播完毕,回归正题】
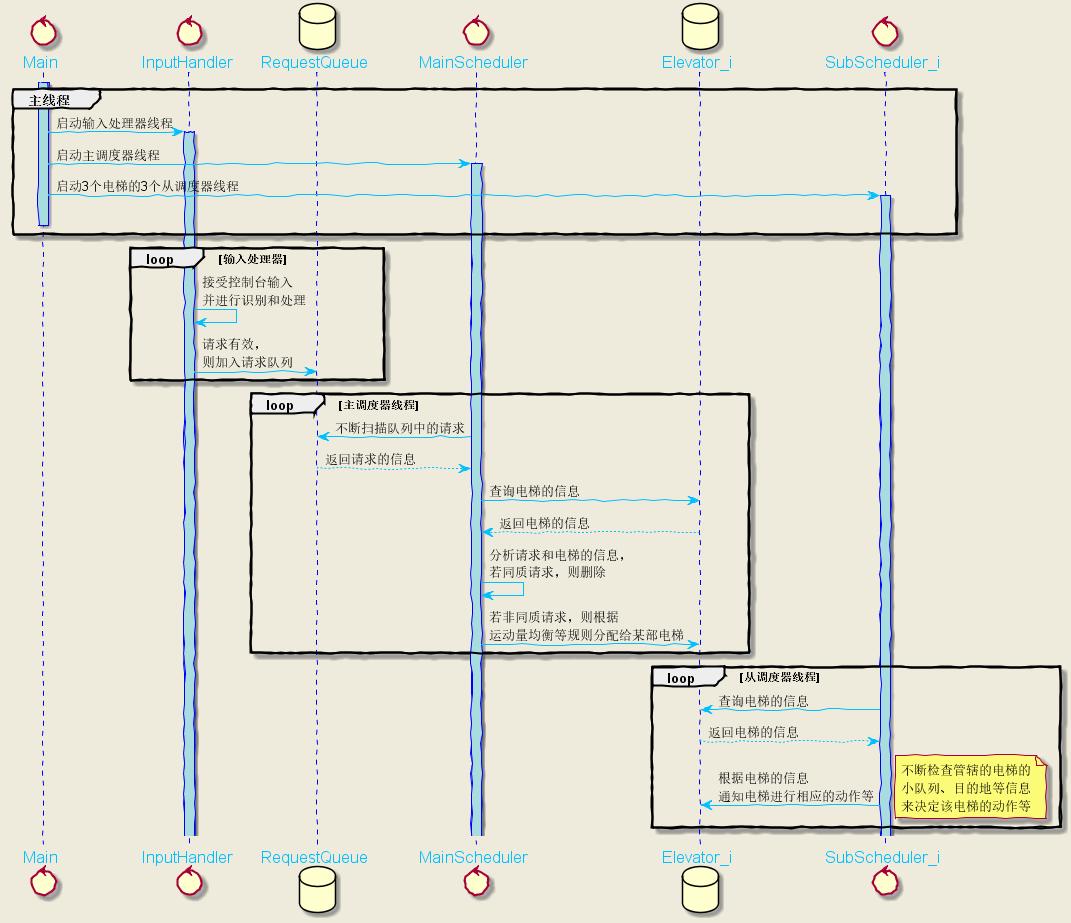
我的多线程电梯UML时序图:
线程总数:主线程Main + 输入处理InputHandler + 主调度器MainScheduler + 从调度器SubScheduler * 3 = 6个线程
(注:一共4个请求队列,一个大的,3个小的分别是归属于3部电梯的)
- 主线程:启动其它线程。
- 输入处理器:不断接受控制台输入,并进行分析,如果有效,则将请求放入请求队列。
- 主调度器:不断扫描请求队列中的请求。判断是否是同质请求,是则删除,不是则:判断是否能被某部电梯捎带,是则选择一部可捎带电梯并将这个请求丢给它,不是则:找出运动量最小的电梯并将这个烫手请求丢给它。
- 从调度器:不断检查自己所管辖的电梯的小队列的情况以及电梯的情况,来决定并通知电梯接下来的动作等。
设计类图
有了设计框架,就进一步细化成 设计类图:(我手动进行了删减和移位)

程序度量分析——Metrics
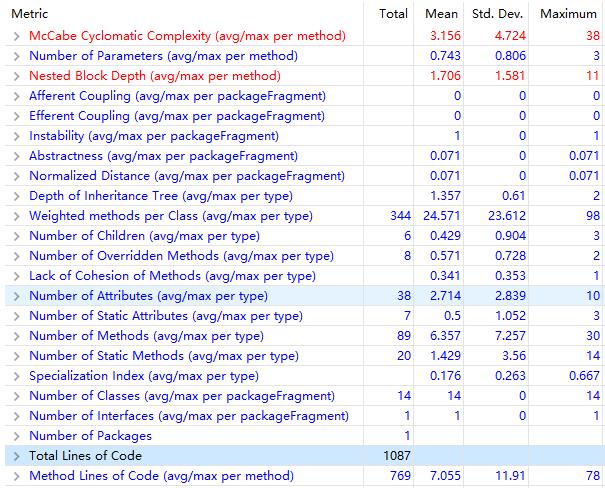
圈复杂度大在哪?

嵌套块深度大在哪?
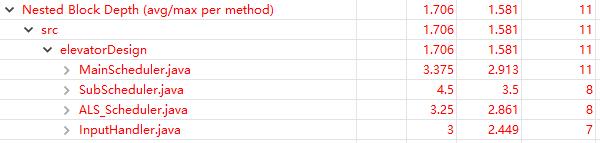
不出所料...当初写这个作业的时候没有想那么多设计上的权衡之类的问题,只是一股脑地想做出来...所以该包装的、该划分功能的地方我都有所忽略。
然后打开代码,就发现以前怎么这么丑陋啊啊啊
- 主调度器的轮廓是这样的:
- 从调度器和输入处理器比它好一些。电梯中也有些小方法是 > 形状的...
线程安全的考虑
- 虽然3个小请求队列 是3个电梯独有的,只会被从调度器使用,但是 大请求队列是 输入处理器线程 和 主调度器线程 共享的对象,因此我将请求队列类的所有 修改或者读取队列内容的方法 都设置成同步方法。(这么一想,是不是电梯的队列 应该另做一个不需要同步的队列类 来提高一丝丝效率呢?)
- 3个电梯是 主调度器 和 从调度器 共享的对象,因此我将电梯类的所有 修改或者读取电梯信息 的方法 都设置成同步方法。
- 当时比较年轻的我还是不大放心,又在4个调度器的run方法里面的某些代码块进行了同步化。
自评优缺点和反思设计原则
- 优点:不是无效。总体框架还算清晰有逻辑。
- 缺点:(1)细节的实现没有考虑简化,只是想做出来而已...所以搞得有些复杂,导致心情浮躁课下漏洞较多。(2)主调度器做的事情有点多,应该把判断同质请求放在到 输入处理器 或者 请求队列 中。(3)没有把功能进行 划分、精细化,导致几个很大块的方法的存在,可读性、可维护性不强。
- 反思设计原则:(1)最大的问题:方法的职责不够单一、不够精细,也就是违反了SRP原则、责任均衡分配原则。(2)没有使用枚举类、全局静态变量等,不符合显式表达原则。(3)高层次的模块直接依赖于低层次的模块而非抽象,即没有考虑到DIP原则。
Bug分析
- 课下调试:(1)没有使用枚举类 而且在判断字符串是否相同的时候 直接使用了==,我真的是=.=,而且是多处如此,而且其中有一个地方忘了改过来导致没有过公测的那个权重为5的测试点真是心痛心痛心痛。(2)在主请求 从无到有、从有到无、由一个变到另外一个即升级未完成的捎带请求为主请求 这几种变化情况上,急匆匆地就搞得比较复杂,出现了一些bug,然后我静下心来重新捋一遍就好了。
- 公测:没有过公测的那个权重为5的测试点真是好心痛。
- 互测:我方安全,对方完美。
- 我栽大了。
- 顺带感谢一波laj小朋友对我的信任!
作业6——IFTTT监控程序
设计框架——UML时序图

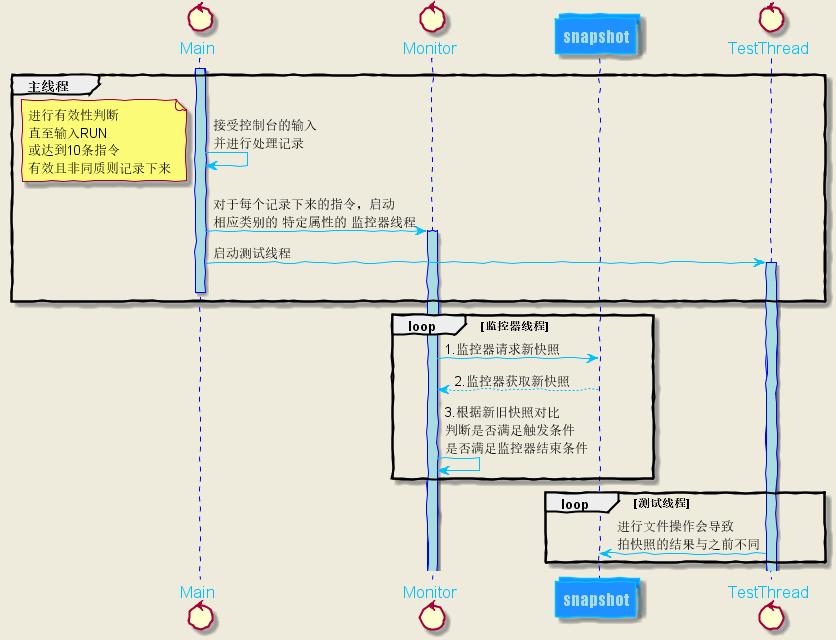
- 为什么没有输入处理器:首先,你要知道,我的程序的输入顺序是酱的:
- 控制台接受IFTTT指令,直到输入RUN,表明指令输入结束。
- 根据输入的指令,启动所有的相应的触发器线程,让主线程睡眠一小段时间,以便于初始化所有触发器线程和快照。
- 创建和启动测试线程,进行一系列文件操作,来进行测试。
- 在启动测试线程之后,主程序将等待您在控制台输入END来结束所有还未结束的触发器线程。
- 可见,输入处理器并不是一个单独的线程,所以我就懒了一把,直接把输入处理的方法都写在Main的类方法中了。
- 上图中,为了简化,就用父类Monitor 来代替 4种监控器线程,因为每类监控器做的事情类似:不断获取新的快照,并与旧快照相比,来判断是否满足触发条件并执行相应动作,以及是否满足监控器的结束条件。每类监控器的属性以及做的事情中的相同的部分,我都提取到了父类Monitor中。
- 一共有4类监控器线程,每个监控器线程以 被监控对象(某个目录或者某个文件)和 触发条件即监控器类型(4选1)作为 这个监控器线程区别于其他监控器线程的标志,也就是说 本程序的监控器线程最多有10*4个,而非10*4*3个。
触发条件和监控条件经过我的readme如下:(正如我上一篇博客所提到的策略,我进行了所有情况的遍历,以避免我遗漏了什么条件)

表1

表2
设计类图
再细化一下,就有了设计类图:(我手动进行了删减和移位)

程序度量分析——Metrics
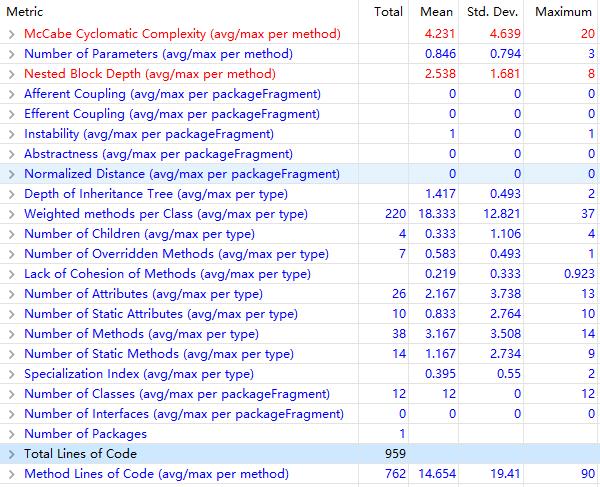
圈复杂度又是哪里大?
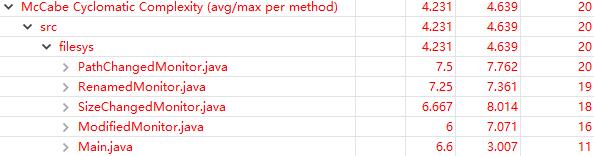
嵌套块深度又是哪里大?
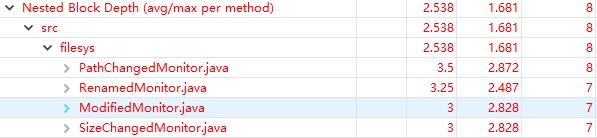
- 嗯,还是老问题,没有把功能进行细分包装。
- 而且我的四个类别的监控器的run方法比较相似:我是先写完一个最难的RenamedMonitor,然后把它的bug找得差不多了,才复制到其它3类监控器中,进行部分代码的修改,这样能够尽量避免 在发现一个bug之后,不会手忙脚乱地去改4个或者2个子监控器类的代码。
- 【分享我这次的码代码经验】
- 首先搭了一个差不多的类的框架,然后写了Main方法以及输入处理,并进行相应的debug
- 然后写完一个最难的RenamedMonitor
- 然后在RenamedMonitor中开一个主方法,在这个主方法中通过参数构造一个RenamedMonitor对象,然后调用他的 run( )方法 。
- 开始单步调试,然后直接操作文件系统:进行创建、移动、重命名等操作,文件操作与 单步调试 交叉进行,同时你还可以查看你实时输出的detail或者summary内容。
- RenamedMonitor监控器的bug找得差不多了。同理可以单独调试另外3个监控器类。
- 最后单线程调得差不多了,就开启多个线程,这时,就不能像上述那样 在多线程的边缘试探 了....老老实实打印出来debug吧,这个时候出现的问题,基本就是线程安全和协作的问题了。前面的步骤已经为你de掉了许多小bug还是可取的。
线程安全的考虑
- 拍快照的时候,会读取文件信息,要求此时文件的信息不能发生改变,因此将 线程安全的文件类SafeFile 的方法设置成了同步方法。
- 另外,如果仅仅按照上一条所述进行同步,仍然可能出现这种情况:遍历某个文件夹下的文件进行拍照时,有可能拍照拍到一半的时候,CPU切换给了测试线程,测试线程对文件A进行了某些操作,当CPU切换回来继续拍照时,照相机可能已经对文件A拍过照了,这时就有会把 A文件被更改这个消息 延迟到 下一次拍快照的时候 发现。
- 为了解决这个问题,我想加把大大的锁,进行文件操作或者拍快照之前,都必须获得这把大锁,这把全局锁是这样的:Object lock = new Object( )。
- (但是现在想想,好像这个延迟的问题并不大,反正马上就要进行下一次拍照了QAQ....)
自评优缺点和反思设计原则
- 优点:总体框架比较清晰有逻辑;自己想出来了个在多线程边缘试探的debug方法;把 四个类别的监控器 的共同方法 和属性 抽出来放到了父类Monitor里面,代码重用性还算好。
- 缺点:(1)有些设计没有必要...(2)没有把功能进行 划分、精细化,可读性、可维护性不强。
- 反思设计原则:(1)方法的职责不够单一、不够精细,违反了SRP原则、责任均衡分配原则。(2)没有考虑到DIP原则。
Bug分析
- 课下调试:对象复制时,什么时候是要 对对象的引用进行复制,什么时候是要 clone一个新的对象出来,这个问题在我调试时反复折磨我,于是我赶紧搞清了这二者的区别,然后又从头缕了一遍。
- 公测:安全。
- 互测——对方:对方的设计思路是最多开120个监控器线程的那种,由于处理不当出现了 “若监控一个文件,且被触发后要执行的任务多于1个,若该文件满足了触发条件,那么有时候这些任务都会被执行,有时候这些任务只会被执行一部分”,这是设计框架的时候容易忽略的一个问题。(我当初没有想过这个问题,当初选择 最多开40个监控器线程的思路 的时候,纯粹是怕120个线程太多了....)
- 互测——我方:我方抛出一个NoPointerException异常,似乎是因为我后来为了能实现 “若监控目录,且满足触发条件后的任务包括recover,那么每当监测到一个文件满足触发条件后,就把快照回退到这个文件改变前的状态” 这一目标,而导致我解决了一个bug后另一个bug又浮出水面....
- 我服。
作业7——出租车的乘客呼叫与应答系统
设计框架——UML时序图
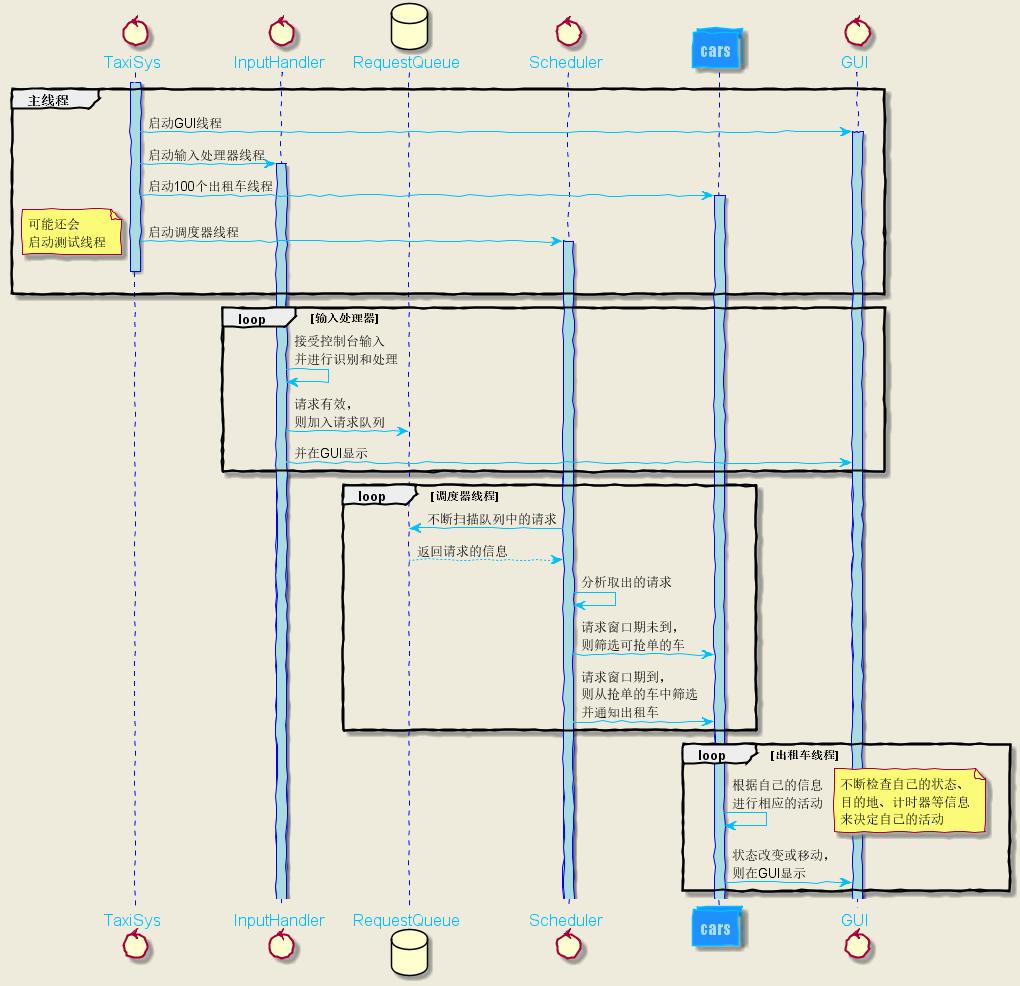
线程总数:主线程TaxiSys + 输入处理InputHandler + 调度器Scheduler + 图形化界面GUI + 出租车Car * 100 = 104个线程
- 主线程:启动其它线程。
- 输入处理器:不断接受控制台输入,并进行分析,如果有效且非同质,则将请求放入请求队列。
- 调度器:不断扫描请求队列中的请求。若请求窗口时间未到,则在所有出租车中寻找具备抢单条件的车。若请求窗口时间到了,则从队列中删除该请求、从所有抢单的车中筛选出最终进行派单的车,然后跟这辆车说,你去响应这个请求吧。
- 出租车线程:不断检查自己的状态等信息,根据自身信息来决定自己接下来该做什么。
- GUI:没什么好说的。
设计类图
有了设计框架,就进一步细化成 设计类图:(我手动进行了删减,为了提取重点和优美)
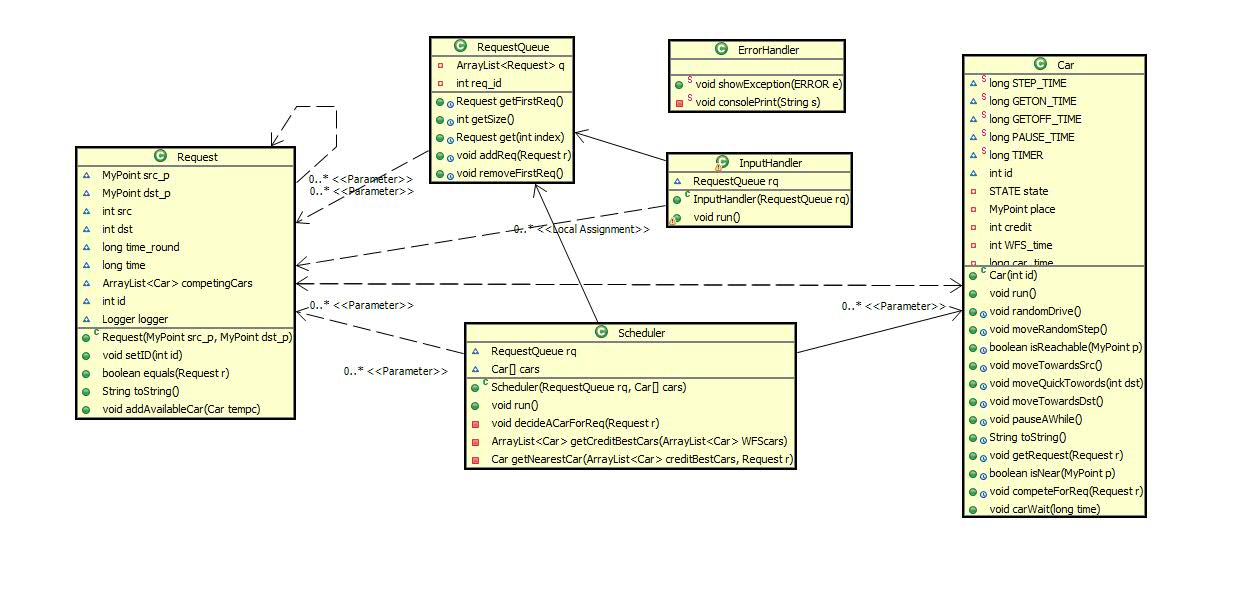
再细化一些,我的程序包括这么些类:
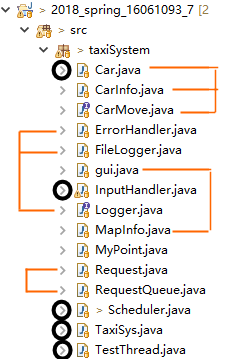
- 打黑色圆圈的是上述104个线程。
- 出租车的属性比较多,而且有些是不需要被外人知道的,为了传递出租车的信息时更加简便,我就做了个出租车信息的类。(我为什么没有做RequestInfo,因为请求的信息比较简单...纯属个人想法,如果您觉得这样做不大对,欢迎留言讨论)
- 为了抽象,我抽取出汽车的运动方法成CarMove接口。(或许以后滴滴还能有truck、motorbike...)
- ErrorHandler你懂的。
- FileLogger是输出日志的类,考虑到DIP原则和扩展性,我又把它抽取成Logger接口。
- gui是课程组提供的,为了读入地图文件信息并转化为数组,我又做了MapInfo。
- 做MyPoint类是为了扩展Point类的功能。
- 请求和请求队列你也懂的。
- 还有一些表示 状态类型、错误类型的 枚举类,就没有列出了。
程序度量分析——Metrics

与前两次相比有了较大进步。
圈复杂度哪里大?

嵌套块深度哪里大?

- gui类我没办法了肝不动了....
- InputHandler和MapInfo都是输入处理,我就没考虑拆分。我的输入处理比较精确,写了35行代码,看来要拆分一下。
- Scheduler我拆分包装得挺好了呀,咋回事?找到Scheduler的run方法,我发现了这个东西 :)

线程安全的考虑
- 请求队列是 输入处理器线程 和 调度器线程 共享的对象,所以我将请求队列的所有 修改或者读取队列内容的方法 都设置成同步方法。
- 每个出租车对象是 这个出租车线程 和 调度器线程 共享的对象, 所以我将出租车的 修改或者读取 出租车状态等信息 的方法 都设置成同步方法。
自评优缺点和反思设计原则
- 优点:结构和逻辑比较清晰,因此debug比较方便。
- 缺点:感觉不是很工程化;在给某一个请求寻找能够抢单的出租车时,采用的是遍历100辆出租车的方法,这样似乎有点浪费资源消耗时间。或许可以如老师所说,【给出租车做几个队列,不同状态的车进不同的队列】,这样查找起来比较方便,又或者,【给出租车做几个队列,不同区域的车进不同的队列】?
- 反思设计原则:这次作业前老师讲了设计原则,因此我这些设计原则实现得还算不错,不过都是自我感觉良好....还是要去看看真正的工程化代码[fighting]
Bug分析
- 课下自我调试:(1)曾经在使用 wait(200) 还是 Thread.sleep(200) 这件事上犹豫了,最后我是这样考虑的:我的出租车类的方法基本都是同步方法,这辆出租车自己 和 调度器是 唯二的 可能拿到这辆出租车的锁 的人,出租车在运动过程中花费200ms的时候,应该把锁让出去给调度器,所以用wait(200)。当然如果你的线程同步设计和我不同,可能结论也不同。(2)为了能够实时输出日志信息,且为了避免所有请求实时输出到一个文件时发生的交错 不优美 的问题,我给不同的请求都分配了日志,但是课下debug时,居然出现了 请求1的部分日志信息写到了 请求2的日志文件中去 的魑魅魍魉现象,我百思不得其解,后来不知道为什么,又好了....(有遇到同样问题且知道幕后黑手的同学欢迎留言...)
- 公测:通过
- 互测:我方安全,对方的输出不符合指导书和issue的要求,而且请求多于3个就抛异常,而且还有一辆车同时匹配2个请求的情况。
- 终于平安耶。
其它总结
设计策略的变化
- 心态上的变化:一开始接触多线程的时候,如上述所讲,我比较急匆匆、晕乎乎,后来掌握了一些套路,就能够冷静下来分析,特别是线程安全相关的问题。当然,冷静的同时还要有紧迫感,反正我隔三差五跟自己说:你要无效了无效了笑了...
- 由全局到细节地考虑。我一般是这样的,先考虑和讨论大框架:应该有多少线程、分别都做什么事情、有共享什么对象吗,这样的设计能够满足那些硬性的大的需求吗。然后再去考虑如何调整小部件去实现那些小的需求。然后感觉差不多了,我就把大概想一想 列一列 有什么类、大概有什么属性和方法、有共同点可以提取吗、有什么线程安全问题要解决。然后开始在纸上把 尽量考虑到各个设计和实现细节的伪代码 写出来。然后开始码代码,在码代码的过程中可能会发现自己伪代码的一些错误或者遗漏,这个时候就能补救;另外,每写完一个 可以测试的 适度规模的 模块的时候,我就先对这个模块进行debug。最后再对整个多线程程序以打印的方式进行debug。
- 尽量不要推倒重构(反正我是没有这个能力和勇气)。这就是我为什么采取上述2策略的原因。
- 码代码的时候就尽量考虑到功能的单一化精细化,不要相信 你有时间 能够在de完bug之后 把某些代码段提取出来成方法 进行功能的归一化。
发现bug的策略
在我的上一篇博客的所述策略——
- 解剖指导书。我遍历了几遍指导书,而且自己用笔把一条条规定都简单列了出来,用红笔标记不同条列之间的关系以及易忽略的点。然后进行一些深入思考,比如指导书说到出租车可能的几个状态的时候,我就画了个状态机出来。深入了解指导书是前提。
- 给自己程序打过的补丁,也可能是别人容易漏掉的。
- 不同的设计方式会有不同的易错点,如果你抽到的代码的设计方式和你不同,可以找找其他使用这个设计方法的同学,问问他们课下de出来了什么bug。比如IFTTT作业中的“最多40个线程设计”和“最多120个线程设计”,这就属于两种不同的设计方式。
- 讨论区和微信群里大家的讨论也都一条条列出来。
- 与你亲爱的同学交换测试样例。(多线程的话,这条基本不管用了....)
- 以更加宏观、复杂、遍历的视角去看待问题,就更容易发现问题所在。比如我在IFTTT作业中,将不同文件操作是否满足4种触发器的触发条件或者结束条件 列了个表格分析。
的基础上,又总结出了一些策略:
- 由简单到复杂地进行自测。自我测试的时候好理解,从小补丁开始打起。
- 互测的时候,你就可以灵活些了。你可以一上来先炸它100个输入(比如100个出租车请求),看他是不是大佬,如果结果和预期不同,你就可以轻轻一笑(如果结果和预期相同,你还可以祈祷它有小bug),然后用 分离的 功能点的 测试样例 去测他的代码,然后一步步增加测试样例的复杂度。(好吧,我承认一上来炸它一个大数据主要是为了把握大局....)
- 灵活地构造测试样例。比如出租车作业中,我构造了这么一个好玩的样例:在 全世界的每个小区域里 发出乘车请求,目标北航,然后看着GUI上出租车大部分都到了北航的时候,乘客们发现北航人都开飞机去了,于是乘客们在北航附近 发出了许多乘车请求想要离开,去哪里就随意吧。这个时候,会出现许多辆出租车抢单的情况,然后你就可以根据 日志输出的抢单的车在请求窗口结束时的信息 来判断应该是哪一个辆车最终被分配到请求。(好吧,这个样例只是好玩而已,可能并不是很有效嘻嘻....)
- 我一般不会仔细地去看人家的代码,除非那人代码特别棒没有bug我就会开始欣赏。但我会大概结合被测程序的代码设计结构,来设计测试用例。因为不同的设计结构会有不同的容易遗漏的问题。
再次感谢各位帮助过我的大佬么么哒~
也继续预祝大家 习得OO,策马归来~