解耦、流量消峰
kafka 分布式,基于zookeeper协调的分布式消息系统,支持分区(partition)多副本(replica)
每秒10万的吞吐量,零拷贝,不经过内存,没有遵守 jms规范
端口默认9092
中文文档
http://kafka.apachecn.org/
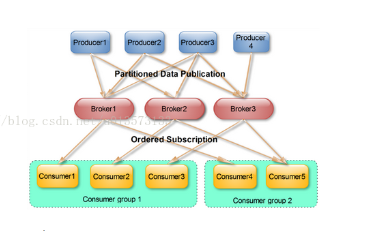

1、消费者 producer
自己决定向哪个partition生产消息,两种机制:hash,轮询
2、partiton 分区
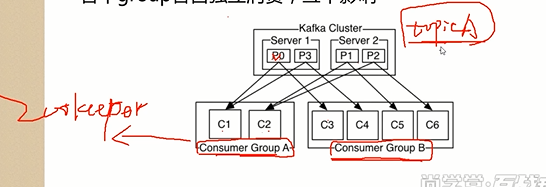
一个topic分成多个partition
每个partition内部消息强有序,其中每个消息都有一个序号叫offset
一个partition 只对应一个broker,一个broker可以管多个partition
消息直接写入文件,并不是存储在内容中
根据时间策略(默认一周)删除,而不是消费完就删除
consumer一次只能从一个分区 partition读消息
每个partition中的消息是强有序的
但是多个consumer 并发从partiton读消息不是整体消息有序的
partition 可已有副本
3、消费者 consumer
consumer自己维护消费到那个offset
每个consumer都有对应的group
同一个组内的consumer只能消费不同的partition,不能共同消费一个partition(除非这个consumer掉了),但是不同组内可以,一个消息在group内只能消费一次
4、topic
一类消息总成(一个消息队列)
5、broker kafka集群节点,没有主从关系,通过zookeeper管理,broker负责消息的读写和存储
一个broker可以管理多个partition
创建消息
kafka-topics.sh --zookeeper node3:2181,node4,node5 --create --topic t001 --partitions 3 --replication-factor 3
Kafaka connect
Kafaka connect 是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。Kafka Connect可以从数据库或应用程序服务器收集数据到Kafka topic,使数据可用于低延迟的流处理。导出作业可以将数据从Kafka topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析。
Kafaka connect的核心组件:
Source:负责将外部数据写入到kafka的topic中。
Sink:负责从kafka中读取数据到自己需要的地方去,比如读取到HDFS,hbase等。
Connectors :通过管理任务来协调数据流的高级抽象
Tasks:数据写入kafk和从kafka中读出数据的具体实现,source和sink使用时都需要Task
Workers:运行connectors和tasks的进程
安装
tar zxvf kafka_2.10-0.9.0.0.tgz
2、Kafka目录介绍
-
/bin 操作kafka的可执行脚本,还包含windows下脚本
-
/config 配置文件所在目录
-
/libs 依赖库目录
-
/logs 日志数据目录,目录kafka把server端日志分为5种类型,分为:server,request,state,log-cleaner,controller
3、配置
-
配置zookeeper
请参考zookeeper
-
进入kafka安装工程根目录编辑config/server.properties
kafka最为重要三个配置依次为:broker.id、log.dir、zookeeper.connect,kafka server端config/server.properties参数说明和解释如下:
4、启动Kafka
启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties &
启动kafka
bin/kafka-server-start.sh config/server.properties
创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic rokid
副本不能大于当前broker节点 数
查看kafka的topic中的内容
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic rokid
-
启动
进入kafka目录,敲入命令 bin/kafka-server-start.sh config/server.properties &
-
检测2181与9092端口
netstat -tunlp|egrep "(2181|9092)" tcp 0 0 :::2181 :::* LISTEN 19787/java tcp 0 0 :::9092 :::* LISTEN 28094/java
后台运行
./kafka-server-start.sh -daemon ../config/server.properties
说明:
Kafka的进程ID为28094,占用端口为9092
消费者消费消息
重复消息
消息丢失
自动提交 默认消费者消费完消息 自动提交调用poll后每5秒提交一次offset,可能会导致重复消费
解决办法 消费端自己做业务处理,进行消息去重
手动提交
异步提交:消息量非常大,业务允许重复消息,可能丢失
都可能导致重复消费
消息回溯 seek(),可指定进行消费,丢了之后再消费
再均衡