深入理解Hadoop集群和网络
原文地址 http://blog.csdn.net/kickxxx/article/details/8230328
本文侧重于Hadoop集群的体系结构和方法,以及它与网络和服务器基础设施这件的关系。文章的素材主要来自于研究工作以及同现实生活中运行Hadoop集群客户的讨论。如果你也在你的数据中心运行产品级的Hadoop集群,那么我希望你能写下有价值的评论。
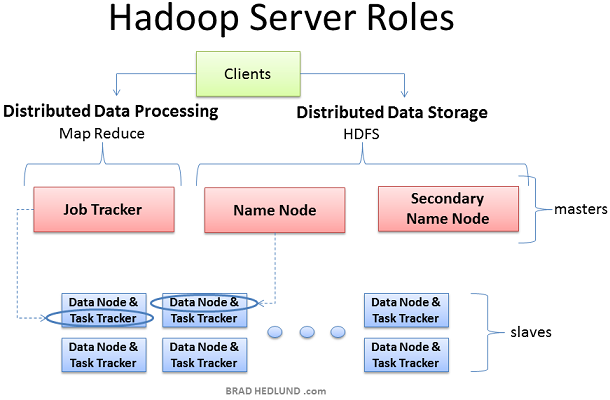
Hadoop集群部署时有三个角色:Client machines, Master nodes和Slave nodes。
Master nodes负责Hadoop的两个关键功能:数据存储(HDFS);以及运行在这个数据之上的并行计算,又称为Map-Reduce。Name node负责调度数据存储,而Job Tracker则负责并行数据处理的调度(使用Map-Reduce技术)。Slave nodes由大量的机器组成,完成数据存储以及运行计算这样的脏活。每个slave node都运行Data node和Task Tracker daemon,这些slave daemon和master nodes的相应daemon进行通信。Task tracker daemon由Job Tracker管理,Data node Daemon由Name node管理。
Client机器包含了Hadoop集群的所有设置,但是它既不是Master也不是Slave。Client的角色是向集群保存数据,提交Map-Reduce jobs(描述如何处理数据),获取查看MR jobs的计算结果。在小型集群中(40节点)你可能会发现一个物理机器扮演多个角色,比如既是Job Tracker又是Name node,在中等或者大规模集群中,一般都是用独立的服务器负责单独的角色。
在真正的产品集群中,不存在虚拟服务器和虚拟机平台,因为他们仅会导致不必要的性能损耗。Hadoop最好运行在linux机器上,直接工作于底层硬件之上。换句话说,Hadoop可以工作在虚拟机之上,对于学习Hadoop是一个不错的廉价方法,我本身就有一个6-node的Hadoop cluster运行Windows 7 laptop的VMware Workstation之上

上图是Hadoop集群的典型架构。机架服务器(不是刀锋服务器)分布在多个机架中,连接到一个1GB(2GB)带宽的机架交换机,机架交换机连接到上一层的交换机,这样所有的节点通过最上层的交换机连接到一起。大部分的服务器都是Slave nodes配置有大的磁盘存储 中等的CPU和DRAM,少部分是Master nodes配置较少的存储空间 但是有强大的CPU和大DRAM
本文中,我们不讨论网络设计的各种细节,而是把精力放在其他方面。首先我们看下应用的工作流程。

为什么会出现Hadoop? 它又解决了什么问题? 简单的说,是由于商业和政府有大量的数据需要快速分析和处理,如果我们把这些巨大的数据切分为小的数据块分散到多台计算机中,并且用这些计算机并行处理分配给他们的小块数据,可以快速的得到结果,这就是Hadoop能做的事情。
在我们的简单例子中,我们有一个大文件保存着所有发给客户服务部分的邮件,想要快速统计单词"Refund"被输入了多少次,这个结果有助于评估对退换货部门的需求,以指定相应对策。这是一个简单的单词计数练习。Client上传数据到集群(File.txt),提交一个job来描述如何分析数据,集群存储结果到一个新文件(Result.txt),然后Client读取结果文件。
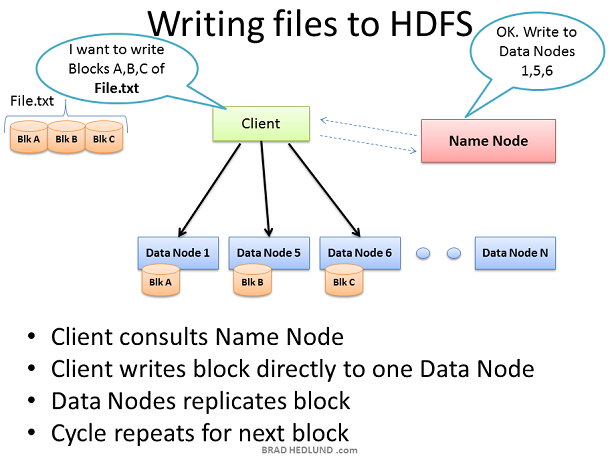
没有加载数据,Hadoop集群就没有任何用途。所以我们首先从加载大文件File.txt到集群中以便处理。目标是能够快速并行处理许多数据,为了达到这个目的需要尽可能多的机器能够同时操纵文件数据。Client把数据文件切分成许多小blocks,然后把他们分散到集群的不同机器上。块数越多,用来处理这些数据的机器就越多。同时这些机器一定会失效,所以要确保每个数据块保存到多个机器上以防止数据丢失。所以每个数据块在存入集群时会进行复制。Hadoop的标准设定是集群中的每个block有三份copy,这个配置可以由hdfs-site.xml的dfs.replication 参数设置
Client把文件File.txt分成3块,对于每一块,Client和Name node协商获取可以保存它以及备份块的Data nodes列表。Client然后直接写block数据到Data node,Data node负责写入数据并且复制copy到其他的Data nodes。重复操作,直到所有的块写完。Name node本身不参与数据保存,Name node仅仅提供文件数据位置以及数据可用位置(文件系统元数据)
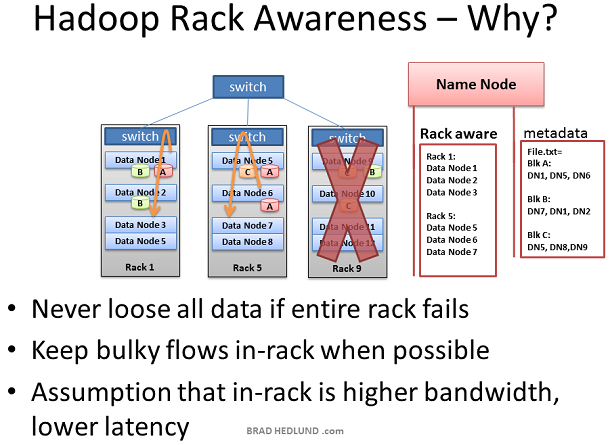
Hadoop引入了Rack Awareness的概念。作为Hadoop系统管理员,你能够手动定义集群中每一个slave Data node的rack号。为什么要把自己置于这种麻烦呢?有两个关键的原因:数据丢失和网络性能。记住每一个数据块都会被复制到多台Data node上,以防止某台机器失效导致数据丢失。有没有可能一份数据的所有备份恰好都在同一个机架上,而这个机架又出现了故障,比如交换机失效或者电源失效。为了防止这种情况,Name node需要知道Data nodes在网络拓扑中的位置,并且使用这个信息决定数据应该复制到集群的什么位置。
我们还假定同一机架的两台机器间相比不同机架的两台机器间 有更高的带宽和更低的网络延迟,在大部分情况下是正确的。机架交换机的上行带宽通常小于下行带宽。此外,机架内延迟通常低于机架间延迟。如果上面的假定成立,那么采用Rack Awareness既可以通过优化位置保护数据,同时提升网络性能,岂不是太cool了。是的,的确是这样,非常cool,对不对。
别急,Not cool的是Rack Awareness是需要手工定义的,并且要持续的更新它,并且保证这个信息精确。如果机架交换机可以自动提供它下面的Data node列表给Name node,那就更cool了。或者如果Data nodes可以自动告知Name node他们属于哪个交换机,一样很cool.
此外,让人感兴趣的是OpenFlow 网络,Name node可以请求OpenFlow控制器关于节点位置的拓扑情况。
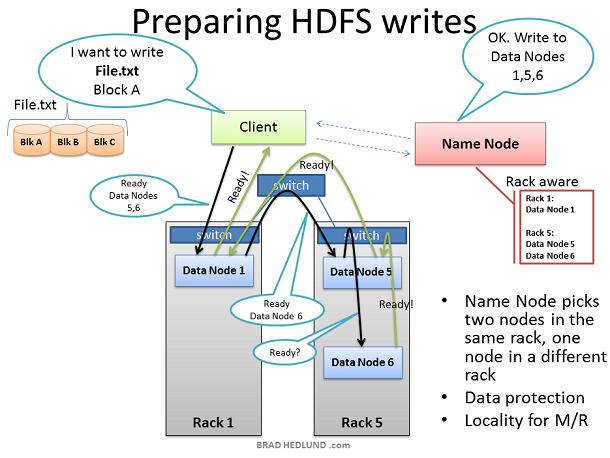
Client准备写文件File.txt到集群时,把文件划分为块,块A为第一个块。Client向Name node申请写文件File.txt,从Name node获得许可,并且接收到一个Data nodes列表(3个表项),每一个Data nodes用来写入块A的一个copy。Name node使用Rack Awareness来决定这个Data nodes列表。规则是:对于每一个数据块,两个 copy存放在一个机架上,另外一个copy存放在另外一个机架上。
在Client写Block A之前,它要知道准备接受”Block A“ copy的Data nodes是否以及做好了准备。首先,Client选择list中的第一个节点Data Node1,打开一个TCP50010链接然后请求:“hey,准备接受一个block,这是一个Data nodes列表(2个表项),Data node5和Data node6”,请确保他们两个也准备好了“;于是Data Node1打开一个到Data node5的TCP500100连接然后说:”Hey,准备接受一个block,这是一个Data nodes列表(1个表项),Data node6”,请确保他准备好了“;Data Node5同样会问Data Node6:“Hey, 准备好接收一个block吗“
”准备就绪“的响应通过已经创建好的TCP pipeline传回来,直到Data Node1发送一个"Ready"给Client。现在Client可以开始写入数据了。
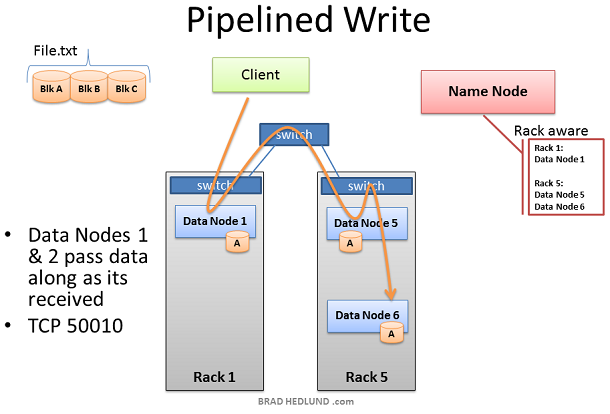
写入数据的过程中,在涉及写操作的Data nodes之间创建一个复制pipeline。也就是说一个数据节点接收数据的同时,同时会把这份数据通过pipeline push到下一个Node中。
从上图可以看到,Rack Awareness起到了改善集群性能的做用。Data node5和Data node6在同一个机架上,因此pipeline的最后一步复制是发生在机架内,这就受益于机架内带宽以及低延迟。在Data node1, Data node5, Data node6完成block A之前,block B的操作不会开始。
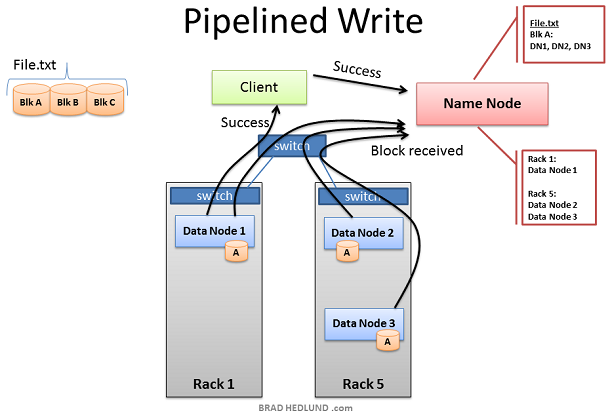
当三个Nodes成功的接收到Block A后,挥发送"Block received"报告给Name node,同时发送"Success"到pipeline中,然后关闭TCP事务。Client在接收到Success信息后,通知Name node数据块已经成功的写入。Name node更新File.txt中Block A的metadata信息(包含Name locations信息)
Client现在可以开始Block B的传输了

随着File.txt的块被写入,越来越多的Data nodes涉及到pipeline中,散落到机架内的热点,以及跨机架的复制
Hadoop占用了很多的网络带宽和存储空间。Hadoop专为处理大文件而生,比如TB级尺寸的文件。每一个文件在网络和存储中都被复制了三次。如果你有一个1TB的文件,那么将消耗3TB的网络带宽,同时要消耗3TB的磁盘空间存贮这个文件。
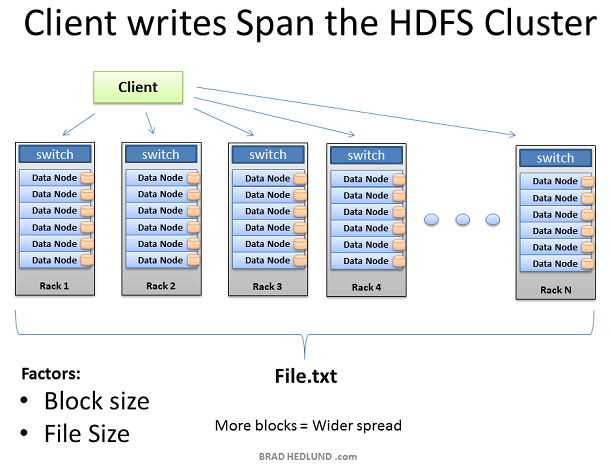
随着每块的复制pipeline的完成,文件被成功的写入集群。文件散落在集群内的机器上,每个机器保存文件的一小部分数据。组成文件的块数目越多,数据散落的机器就越多,将来更多的CPU和磁盘驱动器就能参与到并行处理中来,提供更强大更快的处理能力。这也是建造巨大集群的原动力。当机器的数变多,集群则变得wide,网络也相应的需要扩展。
扩展集群的另外一种方法是deep扩展。就是维持机器数据不便,而是增加机器的CPU处理能力和磁盘驱动器的数目。在这种情况下,需要提高网络的I/O吞吐量以适应增大的机器处理能力,因此如何让Hadoop集群运行10GB nodes称为一个重要的考虑。
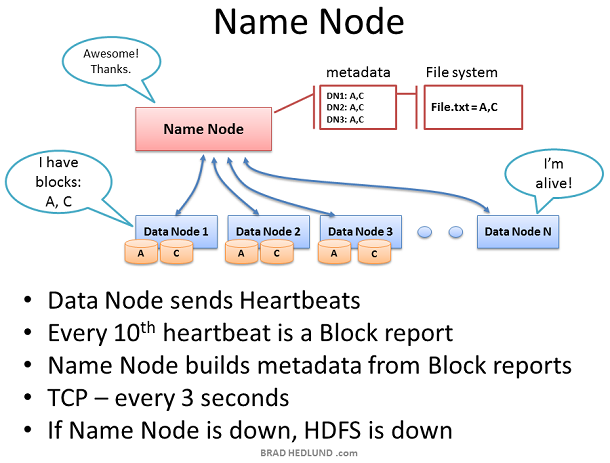
Name node保存集群内所有文件的metadata,监督Data nodes的健康以及协调数据的存取。Name node是HDFS的控制中心。它本身并不保存任何cluster data。Name node知道一个文件由哪些块组成以及这些块存放在集群内的什么地方。Name node告诉Client需要和哪些Data node交互,管理集群的存储容量,掌握Data node的健康状况,确保每一个数据块都符合系统备份策略。
Data node每3秒钟发送一个heartbeats给Name node ,二者使用TCP9000端口的TCP握手来实现heartbeats。每十个heartbeats会有一个block report,Data node告知它所保存的数据块。block report使得Namenode能够重建它的metadata以确保每个数据block有足够的copy,并且分布在不同的机架上。
Name node是Hadoop Distributed File System(HDFS)的关键部件。没有Name node,clients无法从HDFS读写数据,也无法执行Map Reduce jobs。因此Name node 最好配置为一台高冗余的企业级服务器:双电源,热插拔风扇,冗余NIC连接等。
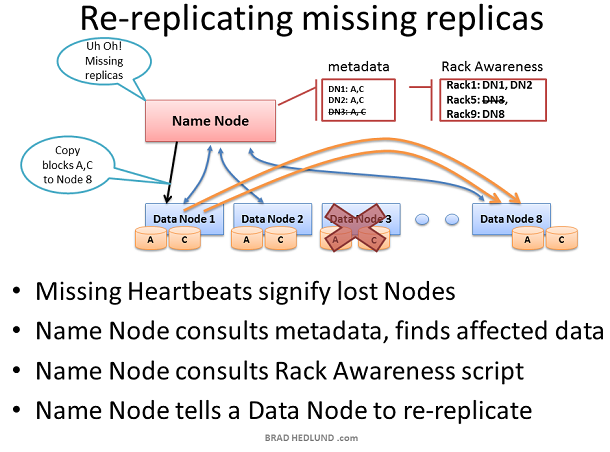
如果Name node收不到某Data node的heartbeats,那么Name node假定这个Data node死机并且Data node上的所有数据也丢失了。通过这台dead Data node的block report,Name node知道哪些block copies需要复制到其他Data nodes。Name node参考Rack Awareness数据来选择接收新copy的Data node,并遵守以下复制规则:一个机架保存两份copies,另一个机架保存第三份copy。
考虑由于机架交换机或者机架电源失败导致的整个机架Data node都失效的情况。Name node将指导集群内的剩余Data nodes开始复制失效机架上的所有数据。如果失效机架上服务器的存储容量为12TB,那么这将导致数百TB的数据在网络中传输。
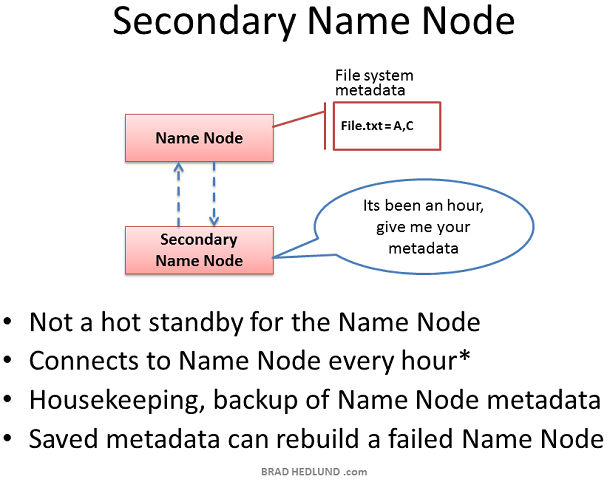
Secondary Name node是Hadoop的一种服务器角色。一个很普遍的误解是它提供了对Name node的高可用性备份,实际上不是。
Secondary Name node偶尔会连接到Name node(缺省为每小时),同步Name node in-memory metadata以及保存metadata的文件。Secondary Name node合并这些信息到一个组新的文件中,保存到本地的同时把这些文件发送回Name Node。
当Name node宕机,保存在Secondary Name node中的文件可以用来恢复Name node。在一个繁忙的集群中,系统管理员可以配置同步时间为更小的时间间隔,比如每分钟。
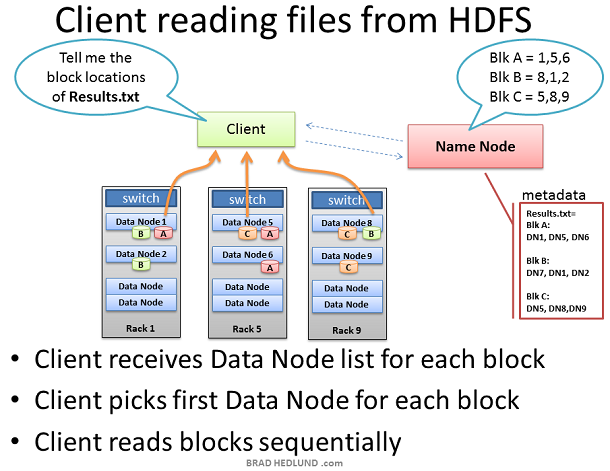
当一个Client想要从HDFS获取一个文件时,比如job的输出结果。Client首先从Name node查询文件block的位置。Name node返回一个包含所有block位置的链表,每个block位置包含全部copies所在的Data node
Client选取一个数据块的Data node位置,通过TCP50010端口从这个Data node读取一块,在读取完当前块之前,Client不会处理下一块。
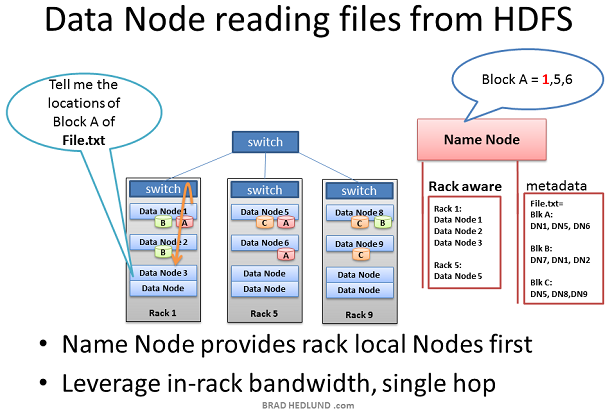
在某些情况下Data node daemon本身需要从HDFS读取数据块。比如Data Node被请求处理自身不存在的数据,因而它必须从网络上的其他Data node获得数据然后才能开始处理。
另外一种情况是Name node的Rack Awareness信息提供的网络优化行为。当Data node向Name node查询数据块位置信息,Name node优先查看请求者所在的机架内的Data nodes包含这个数据块。如果包含,那么Name node把这个Data node提供给请求的Data node。这样可以保证数据仅在in-rack内流动,可以加快数据的处理速度以及job的完成速度
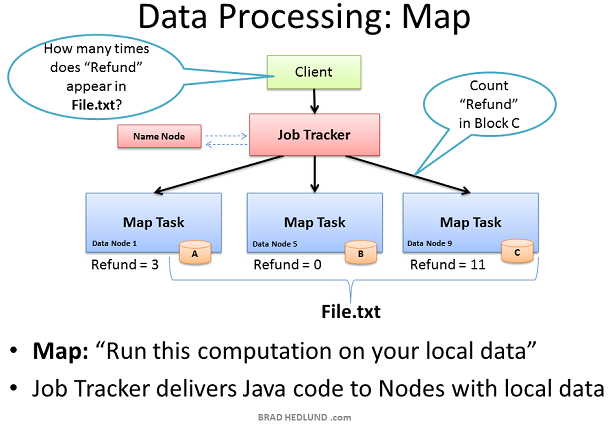
现在File.txt分散到集群的机器中这样就可以提供更快更有效的并行处理速度。Hadoop并行处理框架称为Map Reduce,名称来自于并行处理的两个重要步骤:Map和Reduce
第一步是Map 过程,这个步骤同时请求所有包含数据的Data node运行计算。在我们的例子中则是请求这些Data node统计存储在他们上的File.txt数据块包含多少此Refund
要达到这个目的,Client首先提交Map Reduce job给Job tracker,发送请求:“How many times does Refund occur in file.txt”。Job tracker向Name node查询哪些Data nodes包含文件File.txt的数据块。然后Job Tracker在这些Data nodes上运行Java代码 在Data node的本地数据上执行Map计算。Task Tracker启动一个Map task监测这些tasks的执行。Task Tracker通过heartbeats向Job Tracker汇报task的状态。
当每一个Map task都完成后,计算结果保存在这些节点的临时存储区内,我们称之为"intermediate data"。下一步是把这些中间数据通过网络发送给运行Reduce的节点以便完成最后的计算。

Job tracker总是尝试选择包含待处理数据的Data node做Map task,但是有时不会这样。比如,所有包含这块数据的Data node已经有太多的tasks正在运行,不再接收其他的task.
这种情况下,Job Tracker将询问Name node,Name node会根据Rack Awareness建议一个in-rack Data node。Job tracker把task分配给这个in-rack Data node。这个Data node会在Name node的指导下从包含待处理数据的in-rack Data node获取数据。

Map Reduce 框架的第二部分叫做Reduce。Map task已经完成了计算,计算结果保存在intermediate data。现在我们需要把所有的中间数据汇集到一起作进一步处理得到最终结果。
Job Tracker可以在集群内的任意一个node上执行Reduce,它指导Reduce task从所有完成Map trasks的Data node获取中间数据。这些Map tasks可能同时响应Reducer,这就导致了很多nodes几乎同时向单一节点发起TCP连接。我们称之为incast或者fan-in(微突发流)。如果这种微突发流比较多,那么就要求网络交换机有良好的内部流量管理能力,以及相应的buffers。这种间歇性的buffers使用可能会影响其他的网络行为。这需要另开一篇详细讨论。
Reducer task已经收集了所有intermediate data,现在可以做最后计算了。在这个例子中,我们只需简单的把数字相加就得到了最终结果,写入result.txt
我们的这个例子并没有导致很多的intermediate data在网络间传输。然而其他的jobs可能会产生大量的intermediate data:比如,TB级数据的排序,输出的结果是原始数据集的重新排序,结果尺寸和原始文件大小一致。Map Reduce过程会产生多大的网络流量王权依赖于给定的Job类型。
如果你对网络管理很感兴趣,那么你将了解更多Map Reduce和你运行集群的Jobs类型,以及这些Jobs类型如何影响到网络。如果你是一个Hadoop网络的狂热爱好者,那么你可能会建议写更好的Map Reduce jobs代码来优化网络性能,更快的完成Job

Hadoop通过在现有数据的基础上提供某种商业价值,从而在你的组织内获得成功。当人们意识到它的价值,那么你可能获得更多的资金购买更多的机架和服务器,来扩展现有的Hadoop集群。
当增加一个装满服务器的新机架到Hadoop集群中时,你可能会面临集群不平衡的局面。在上图的例子中,Rack1和Rack2是已经存在的机器,保存着文件File.txt并且正在运行Map Reduce jogs。当我们增加两个新的机架到集群中时,File.txt 数据并不会神奇的自动散布到新的机架中。
新的Data node服务器由于没有数据只能空闲着,直到Client开始保存新的数据到集群中。此外当Rack1和Rack2上的服务器都满负荷的工作,那么Job Tracker可能没有别的选择,只能把作用在File.txt上的Map task分配到这些没有数据的新服务器上,新服务器需要通过网络跨机架获取数据。这就导致更多的网络流量,更慢的处理速度。
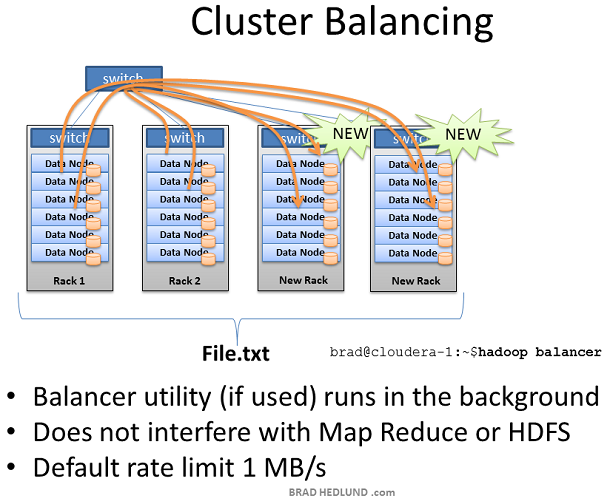
为了处理这种情况,Hadoop包含一个时髦的工具叫做 balancer
Balancer查看节点可用存储的差异性,在达到特定的阀值后尝试执行balance。有很多空闲空间的新节点将被检测到,然后balancer开始从空闲空间很少的Data node拷贝数据到这个新节点。Balancer通过控制台的命令行启动,通过控制台取消或者关闭balancer
Balancer可用的网络流量是非常低的,缺省设置为1MB/s。可以通过hdfs-site.xml的df.balance.bandwidthPerSec参数来修改。
Balancer是你的集群的好管家。在你增加服务器时一定会用到它,定期(每周)运行一次也是一个好主意。Balancer使用缺省带宽可能会导致很长时间才能完成工作,比如几天或者几周。
本文是基于Training from Cloudera 的学习 以及对我的Hadoop实验环境的观测。这里讨论的内容都是基于latest stable release of Cloudera's CDH3 distribution of Hadoop 。本文并没有讨论Hadoop的新技术,比如:Hadoop on Demand(HOD)和HDFS Federation ,但是这些的确值得花时间去研究。