散列查找
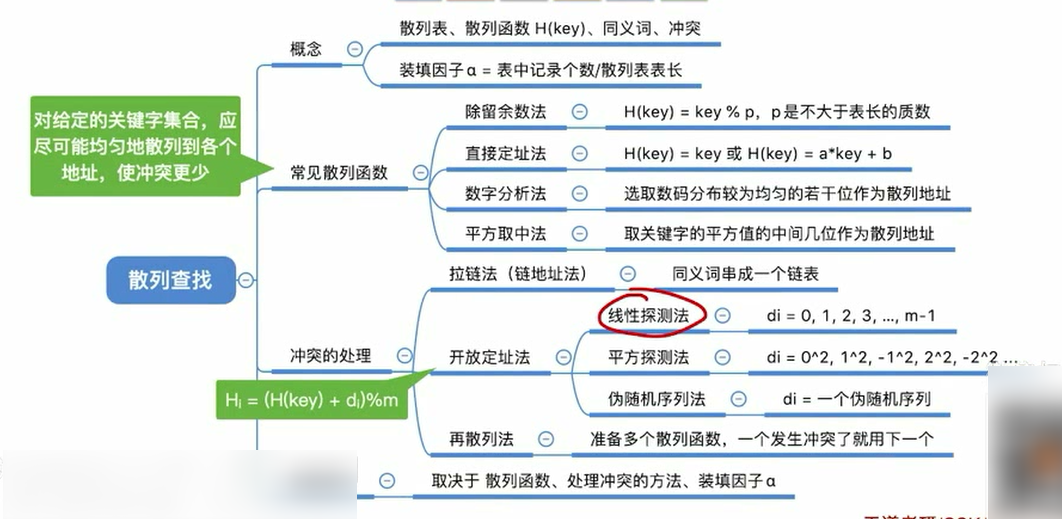
散列表(Hash Table)
散列表(Hash Table),又称哈希表,是一种数据结构,特点是:数据元素的关键字与其存储地址直接相关
如何建立“关键字”与“存储地址”的联系?
通过“散列函数(哈希函数)”:Addr=H(key)
若不同的关键字通过散列函数映射到同一个值,则称他们为“同义词”
通过散列函数确定的位置已经存放了其他元素,则称这种情况为“冲突”
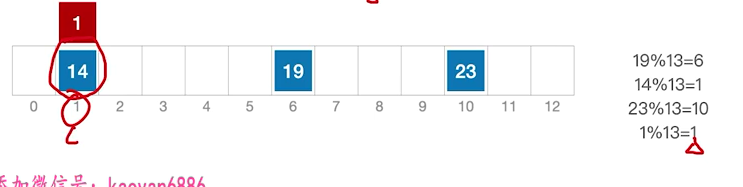
处理冲突的方法——拉链法
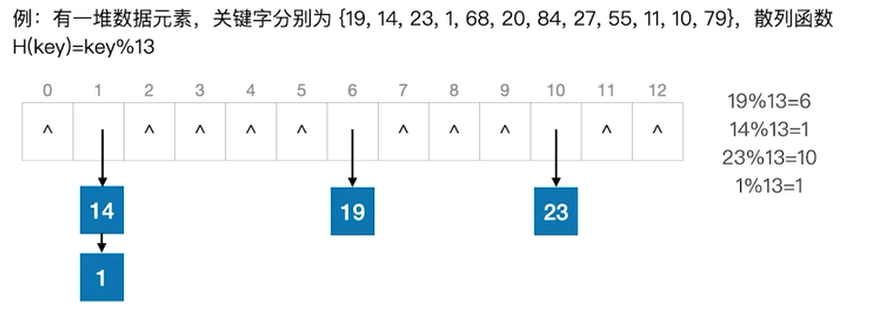
用拉链法(又称链接法,链地址法)处理“冲突”:把所有“同义词”存储在一个链表中
散列查找
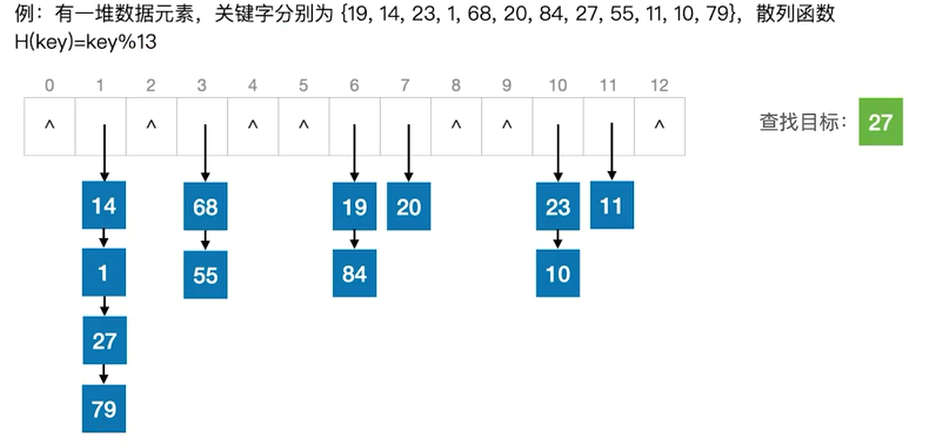
通过散列函数计算目标元素存储地址:Addr=H(Key)
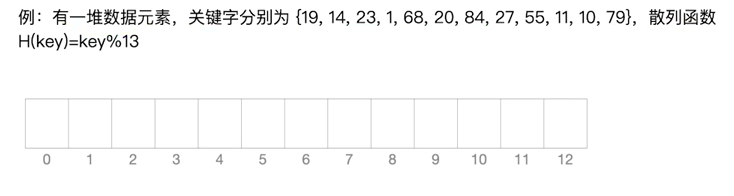
27%13=1
27的查找长度=3(对比次数)
查找目标:21
21%13=8
21的查找长度=0
查找长度——在查找运算中,需要对比关键字的次数称为查找长度
平均查找长度:
第一层结点6个,对比1次有6个机会
第二层结点4个,对比2次有4次机会
第三层结点1个
第四层结点1个
“冲突”越多,查找效率越低
下面那样情况就很好
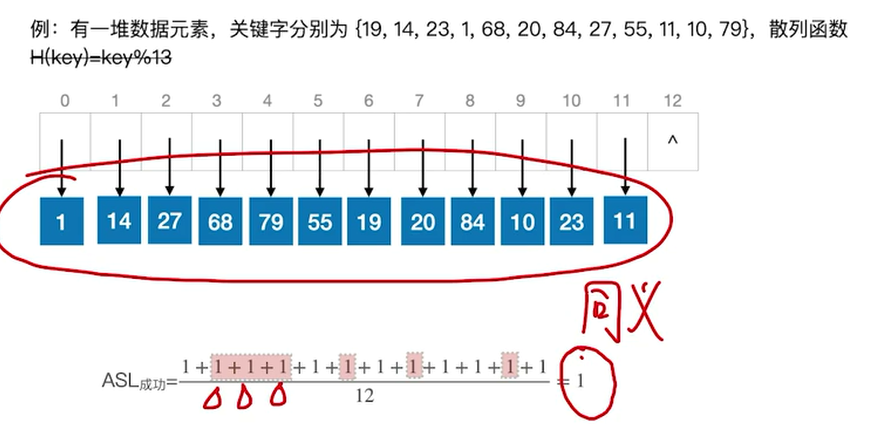
最理想情况:散列查找时间复杂度可达到O(1)
第一个对比0次就失败
第二个对比4次失败。。。
装填因子α=表中记录数/散列表长度
装填因子会直接影响散列表的查找效率
如何设计冲突更少的散列函数
常见的散列函数
除留余数法——H(key) = key%p
散列表表长为m,去一个不大于m但最接近或等于m的质数p
(质数:又称素数,指除了1和此整数自身外,不能被其他自然数整除的数)
相反概念——合数
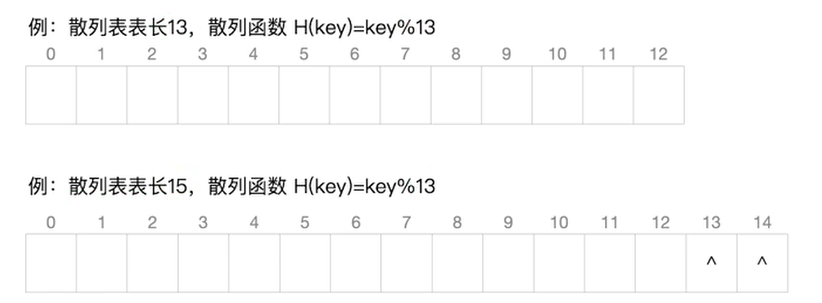
表长15,浪费了2个位置
设计目标——让不同关键字冲突尽可能的少
所以要取质数
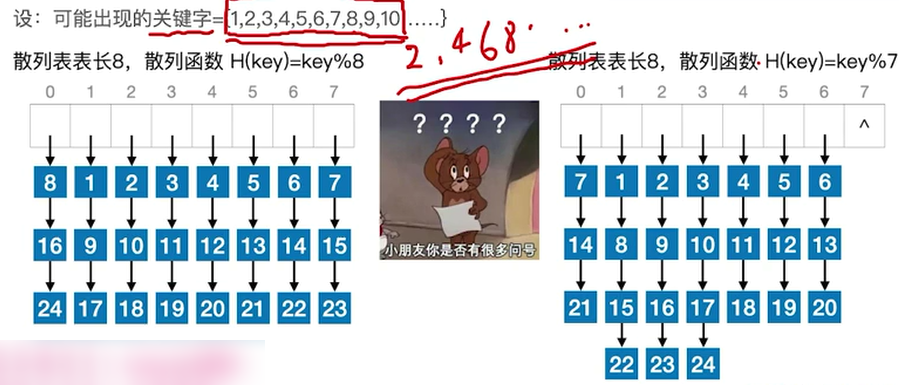

散列函数的设计要结合关键字分布特点来考虑,不要教条化
直接定址法——H(key) = key 或 H(key) = a*key +b
其中,a和b是常数。这种方法计算最简单,且不会产生冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费

数字分析法——选取数码分布较为均匀的若干位作为散列地址
设关键字是r进制数(如十进制数),而r个数码在各位 上出现的频率不一定相同,可能在某些位上均匀一些,每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,此时可选取数码分布较为均匀的若干位作为散列地址。这种方法适用于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数。

平方取中法——取关键字的平方值的中间几位作为散列地址
具体取多少位要视实际情况而定。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀,适用于关键字的每位取值都够均匀或均小于散列地址所需的位数。

假设学生不超过十万人,可身份证平方取中间5位

处理冲突的方法——开放定址法
- 线性探测法
- 平方探测法
- 伪随机序列法

第i次冲突
线性探测法
线性探测法——di=0,1,2,3,...m-1;即发生冲突时,每次往后探测相邻的下一个单元是否为空。
假如要插入1

H(key) = 1%13 =1 H0=(1+d0)%16=1最开始,冲突了,所以有:
H1 = (1+d1)%16=2(发生第一次冲突计算得到的哈希地址)
如果一直冲突就一步一步的找探测值往里带
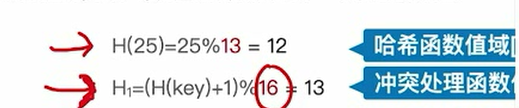
查找操作

同义词、非同义词都需要被检查


删除操作

注意:采用“开放定址法”时,删除节点不能简单地将被删结点的空间位置为空,否则将截断在它之后增加的散列表的同义词结点的查找路径,可以做一个“删除标记”,进行逻辑删除

查找效率分析(ASL)
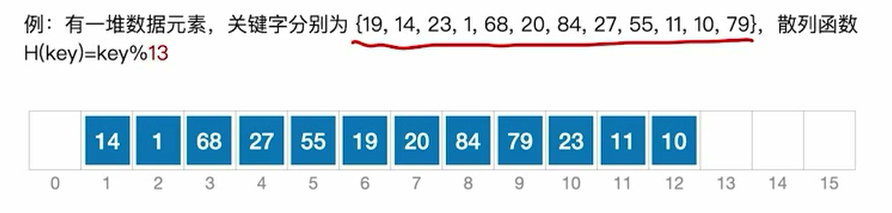
19%13=6——1次
14%13=1——1次
。。。
初次探测的地址H0只有可能在[0,12]
线性探测法很容易造成同义词,非同义词的“聚集(堆积)“现象,严重影响查找效率
产生原因——冲突后在探测一定是放在某个连续的位置
平方探测法

小坑:散列表长度m必须是一个可以表示成4j+3的素数,才能探测到所有位置
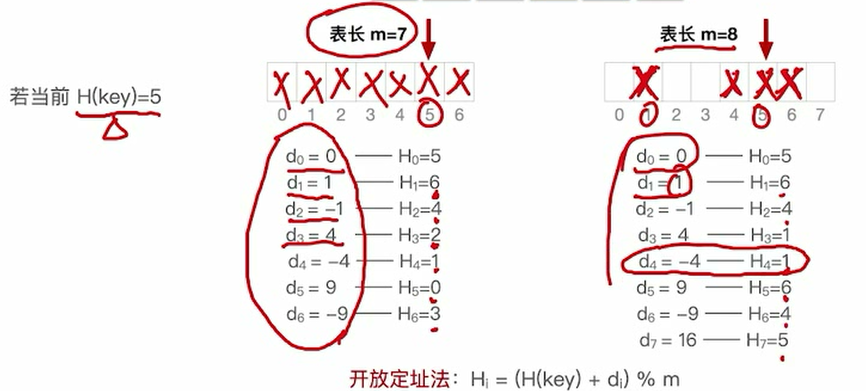
伪随机序列法

其实就是di不一样而已
处理冲突的方法——再散列法
再散列法(再哈希法):除了原始的散列函数H(key)之外,多准备几个散列函数,当散列函数冲突时,用下一个散列函数计算一个新地址,知道不冲突为止: