import re
def str2ner_train_data(s,save_path):
ner_data = []
result_1 = re.finditer(r'[@', s)
result_2 = re.finditer(r'*]', s)
begin = []
end = []
for each in result_1:
begin.append(each.start())
for each in result_2:
end.append(each.end())
assert len(begin) == len(end)
i = 0
j = 0
while i < len(s):
if i not in begin:
ner_data.append([s[i], 0])
i = i + 1
else:
ann = s[i + 2:end[j] - 2]
entity, ner = ann.rsplit('#')
if (len(entity) == 1):
ner_data.append([entity, 'S-' + ner])
else:
if (len(entity) == 2):
ner_data.append([entity[0], 'B-' + ner])
ner_data.append([entity[1], 'E-' + ner])
else:
ner_data.append([entity[0], 'B-' + ner])
for n in range(1, len(entity) - 1):
ner_data.append([entity[n], 'I-' + ner])
ner_data.append([entity[-1], 'E-' + ner])
i = end[j]
j = j + 1
f = open(save_path, 'w', encoding='utf-8')
for each in ner_data:
f.write(each[0] + ' ' + str(each[1]))
f.write('
')
f.close()
def txt2ner_train_data(file_path,save_path):
fr=open(file_path,'r',encoding='utf-8')
lines=fr.readlines()
s=''
for line in lines:
line=line.replace('
','')
line=line.replace(' ','')
s=s+line
fr.close()
str2ner_train_data(s, save_path)
if(__name__=='__main__'):
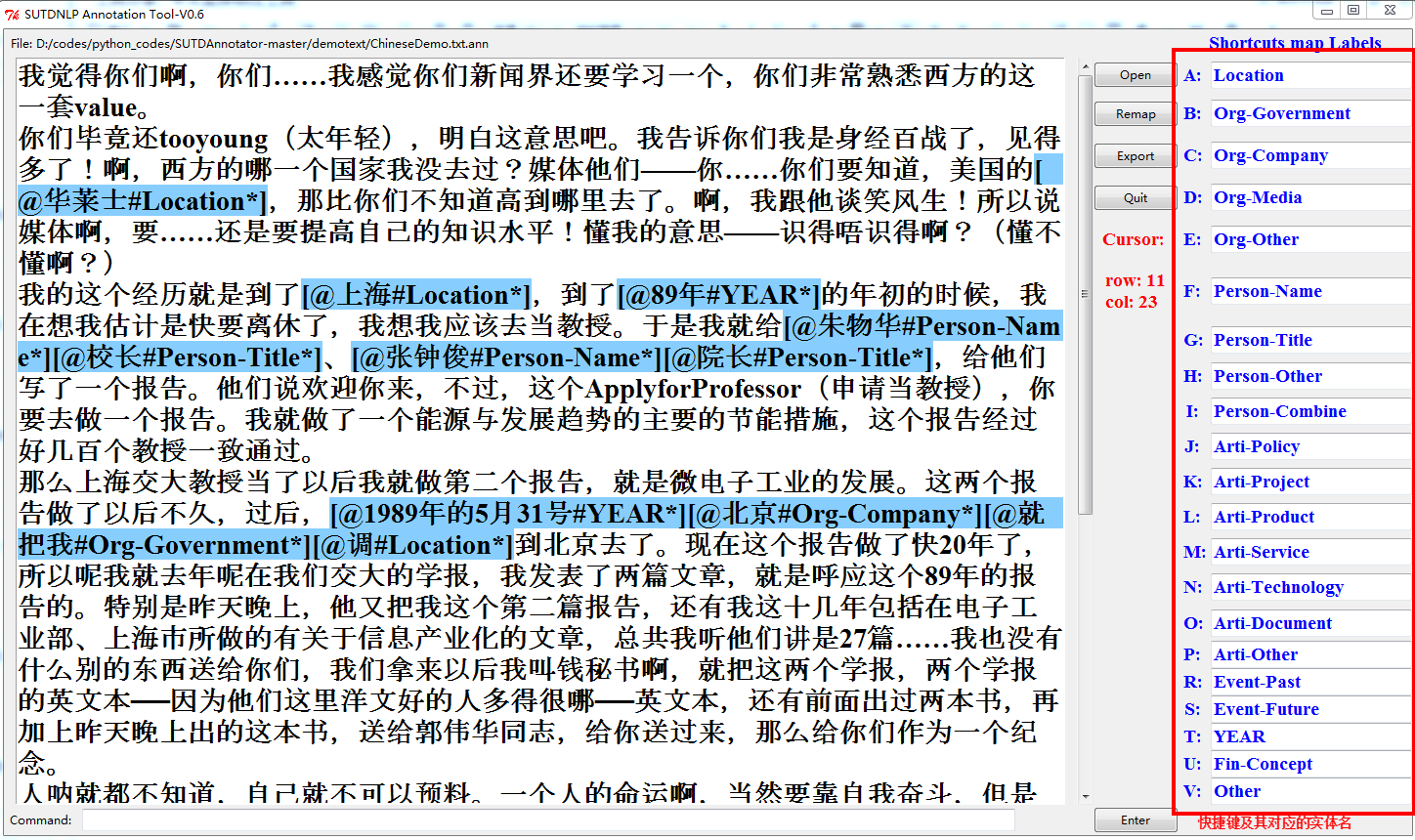
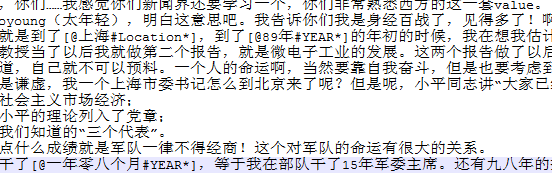
s = '我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
save_path = 's.txt'
str2ner_train_data(s, save_path)
file_path='D:\codes\python_codes\SUTDAnnotator-master\demotext\ChineseDemo.txt.ann'
txt2ner_train_data(file_path,'s1.txt')