Hadoop 服务划分
使用三台节点,集群部署规划如下
|
服务主机 |
hadoop1 |
hadoop2 |
hadoop3 |
|---|---|---|---|
|
HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
IP地址规划
hadoop1 192.168.123.11 hadoop2 192.168.123.12 hadoop3 192.168.123.13
系统环境配置
一、基本信息配置(三台节点需要分别配置)
IP地址配置
# 配置 IP 地址,网卡配置文件不一定相同 vim /etc/sysconfig/network-scripts/ifcfg-ens33 # 自启动网卡 ONBOOT="yes" # IP地址 IPADDR="192.168.123.11" # 子网页码 PREFIX="24" # 网关 GATEWAY="192.168.123.2" # DNS 服务器 DNS1="119.29.29.29" # 重启网络服务 systemctl restart network
修改主机名
# 修改主机名字为 hadoop1 hostnamectl set-hostname hadoop1 # 退出当前用户再登录即可看见 logout
关闭防火墙,也可放行
# 关闭防火墙
systemctl stop firewalld
# 关闭防火墙开机自启动
systemctl disable firewalld
安装 Rsync 工具,用于同步主机之间的文件,这样后面的配置文件修改就不用每台机器都改一遍,直接同步过去即可
# 清空 yum 源。若已配置源,直接安装即可 rm -rf /etc/yum.repos.d/* # 配置阿里 yum 源 curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo # 安装 rsync yum install -y rsync
二、基本服务配置(配置一台主机,其他主机同步即可)
配置主机之间相互免密登录
# 以一台机器为例子,其他一样 # 生成密钥文件,一直回车 ssh-keygen -t ecdsa -b 521 # 配置免密登录,需要输入远程主机密码,本机也需要配置 ssh-copy-id -i ~/.ssh/id_ecdsa.pub hadoop1 ssh-copy-id -i ~/.ssh/id_ecdsa.pub hadoop2 ssh-copy-id -i ~/.ssh/id_ecdsa.pub hadoop3 # 验证,不用输密码即为成功 ssh hadoop1 ls /
添加主机名到 Hosts 文件
vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 # 对应本机IP地址,非 127.0.0.1 192.168.123.11 hadoop1 192.168.123.12 hadoop2 192.168.123.13 hadoop3
安装 JDK https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
# 解压 tar -zxf /opt/jdk-8u202-linux-x64.tar.gz -C /opt/ # 配置环境变量 vim /etc/profile # JAVA_HOME export JAVA_HOME=/opt/jdk1.8.0_202/ export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH # 刷新环境变量 source /etc/profile # 验证 java -version # java version "1.8.0_202" # Java(TM) SE Runtime Environment (build 1.8.0_202-b08) # Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
安装 Hadoop https://hadoop.apache.org/releases.html
# 解压 tar -zxf /opt/hadoop-2.9.2-snappy-64.tar.gz -C /opt/ # 配置环境变量 vim /etc/profile # HADOOP_HOME export HADOOP_HOME=/opt/hadoop-2.9.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin # 刷新环境变量 source /etc/profile # 验证 hadoop version # Hadoop 2.9.2 # Subversion Unknown -r Unknown # Compiled by root on 2018-12-16T09:39Z # Compiled with protoc 2.5.0 # From source with checksum 3a9939967262218aa556c684d107985 # This command was run using /opt/hadoop-2.9.2/share/hadoop/common/hadoop-common-2.9.2.jar
同步服务到其他机器
# 同步 Hosts 文件 rsync -avz /etc/hosts hadoop2:/etc/ rsync -avz /etc/hosts hadoop3:/etc/ # 同步 JDK,源路径不要带斜杠 rsync -avz /opt/jdk1.8.0_202 hadoop2:/opt/ rsync -avz /opt/jdk1.8.0_202 hadoop3:/opt/ # 同步 Hadoop,源路径不要带斜杠 rsync -avz /opt/hadoop-2.9.2 hadoop2:/opt/ rsync -avz /opt/hadoop-2.9.2 hadoop3:/opt/ # 同步环境变量文件 profile,目标主机上的环境变量需要手动刷新:source /etc/profile rsync -avz /etc/profile hadoop2:/etc/ rsync -avz /etc/profile hadoop3:/etc/
Hadoop分布式配置
配置一台机器,其他同步即可,配置文件目录:hadoop-2.9.2/etc/hadoop/
一、基本配置
core-site.xml
<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-tmp</value> </property> </configuration>
hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/opt/jdk1.8.0_202/
二、HDFS 配置
hdfs-site.xml
<configuration> <!-- 指定文件块副本数 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop3:50090</value> </property> </configuration>
三、YARN 配置
yarn-env.sh
# some Java parameters export JAVA_HOME=/opt/jdk1.8.0_202/
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <!-- Reducer获取数据方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> </configuration>
四、MapReduce 配置
mapred-env.sh
# limitations under the License. export JAVA_HOME=/opt/jdk1.8.0_202/ # when HADOOP_JOB_HISTORYSERVER_HEAPSIZE is not defined, set it.
mapred-site.xml,将 mapred-site.xml.template 重命名为 mapred-site.xml
<configuration> <!-- 指定MapReduce运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
五、集群节点地址配置
slaves
# 所有 DataNode 节点的主机地址
hadoop1
hadoop2
hadoop3
六、将配置文件同步到其他节点
# 将 Hadoop 配置文件同步到其他节点上 rsync -avz /opt/hadoop-2.9.2 hadoop2:/opt/ rsync -avz /opt/hadoop-2.9.2 hadoop3:/opt/
启动 Hadoop 集群
一、第一次使用需要先格式化 NameNode,这里是在 hadoop1 上执行格式化
hadoop namenode -format
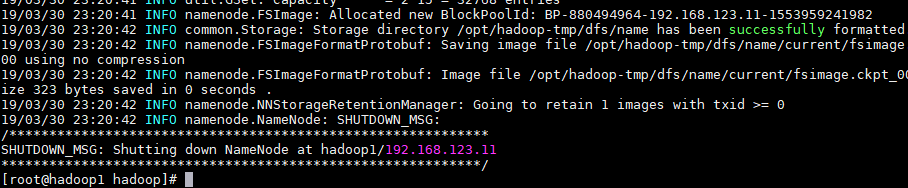
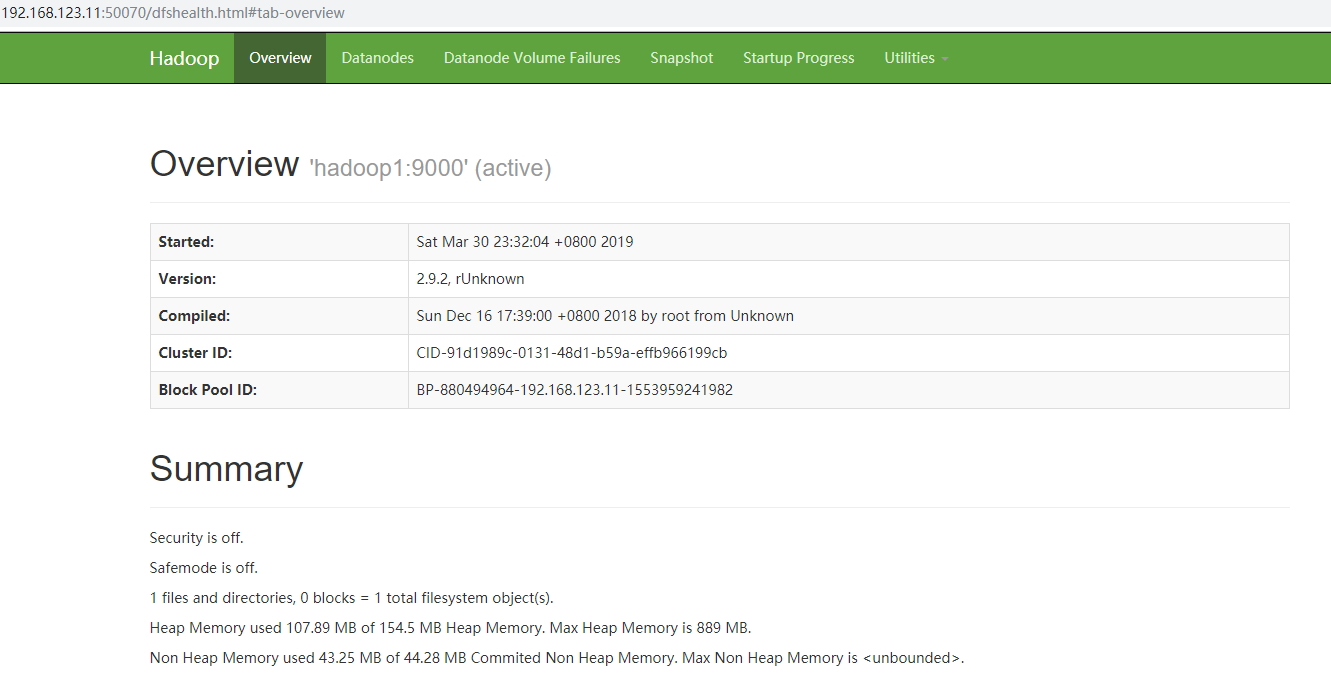
二、在 NameNode 所在节点启动 hdfs,这里是 hadoop1
start-dfs.sh

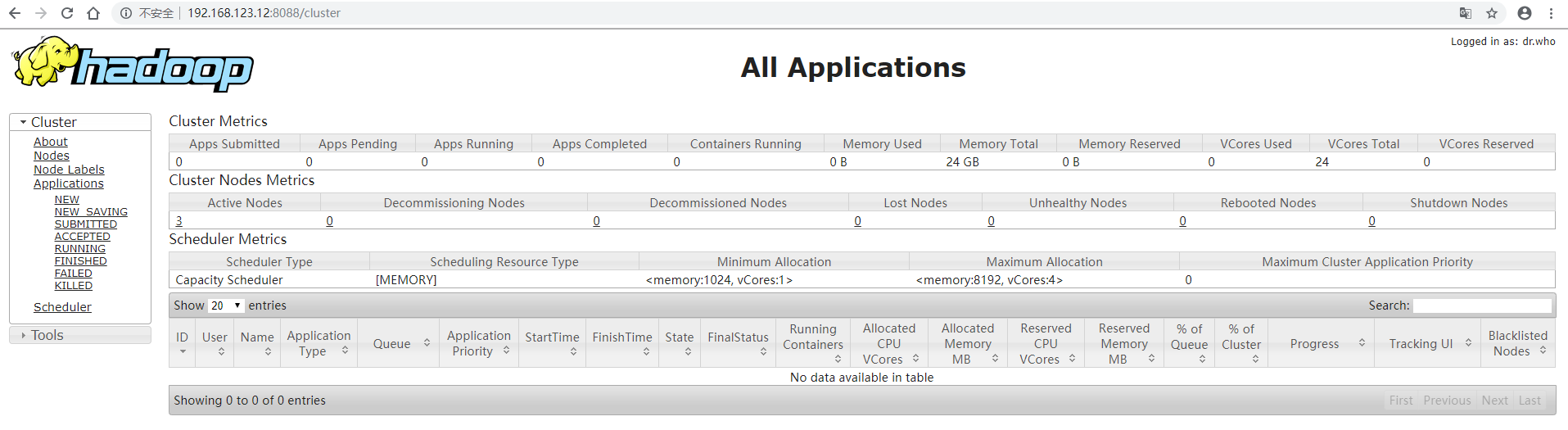
三、在 ResourceManger 所在节点启动 yarn,这里是 hadoop2
start-yarn.sh

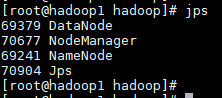
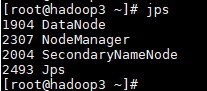
查看各个节点进程

配置时间服务
https://www.cnblogs.com/jhxxb/p/10579816.html
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html