CPU调度
基础

CPU利用率=CPU充分利用时间/CPU使用总时间
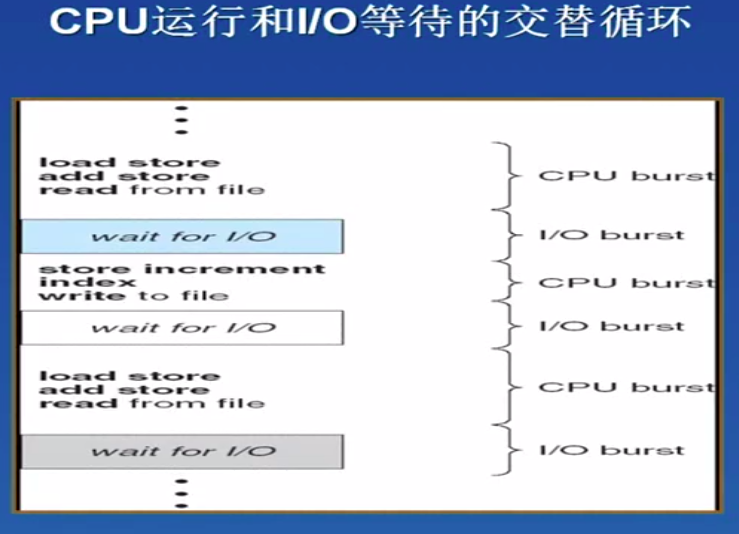

来源:https://www.zhihu.com/question/266544961
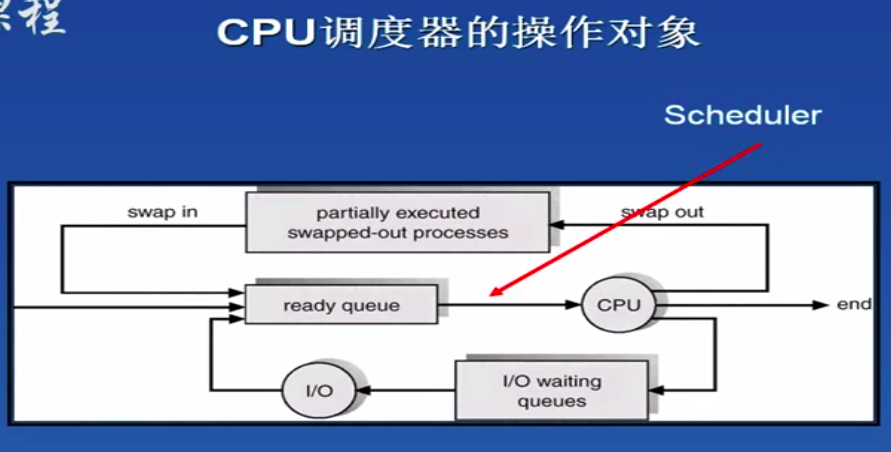
Schedule和dispatch的区别?
用“主要业务逻辑”做在哪里来区分。
schedule: 调度。 scheduler是具有重业务逻辑的,也就是调度算法。例如,linux kernel从中断出来后,会切入到scheduler routine,因为这里面的逻辑很多(CFS,RR,FIFO等调度算法),所以叫做 调度。
dispatch: 分发、派发。 dispatcher是轻业务逻辑或者没有业务逻辑,纯粹简单的转发、派发。例如,负载均衡的dispatcher收到请求后,通过哈希表找到response server,直接将请求派发下去,本身并不做业务逻辑。
有的操作系统scheduler和dispatcher是分开的,有的是合二为一的,例如后面要讲的linux版本中就是
调度器调度的时机举例:

第一种是因为该进程需要资源,所以处于等待状态
第二种是时间片被抢走了,例如有一个高优先级的进程进入就绪队列
第三种是需要的资源到了,因为优先级比较高,抢夺了时间片。这种和第二种其实是一回事
还有其他的许多情况需要调用调度器,例如CPU时间片到期等等
非抢占式:进程自愿交出CPU资源引起的调度

分配器做的事情不涉及到决策,是固定的事情
分配延时应该尽可能减少

等待时间:一个进程的任务很可能是不能在一次就执行完的,可能需要多次等待,所以这是个累计时间
响应时间:到调度器开始响应就算完,不需要完成响应
先来先服务算法(FCFS)

原理和名称一样,用一个队列就可以了
显然这个例子里平均等待时间不是最优的,但是CPU利用率的确是100%
换一下顺序,平均等待时间就好多了:

最短优先算法(SJF)

这个算法倒是能使得平均等待时间最短

也可以是抢占式的:

每次有进程进入就绪状态时,比较时是和原来在执行的进程的剩余执行所需时间相比
两种策略对比:

但是这种算法有致命问题:进程是没办法准确预报自己花费的CPU时间的(执行时间可能和资源和实际情况有关),所以只能停留在理论上23333
但是也不是完全不能预估,只不过就是要基于概率模型了,也就是有预估错误的可能性:

tn表示第n次的真实时间

最高响应比优先算法(HRN)

W表示该进程自从进入就绪队列至今的等待时间
HRN是大于等于1的,基准值是1
总是为相对等待时间较长的进程服务,这个“相对”表示的是相对于它的预估的CPU时间:需要CPU时间长的,就应该等待的长一点,反之,就应该短一点
优先权法

这是比较流行的一种方法
在PCB中加一个优先数
可以使用堆来每次获得优先级最高的进程
优先权法的一个问题:

从上也可以看出来不是什么大问题,所以这种算法是比较好的,也是在实际操作系统中比较常用的一种算法
轮转法

这种方法最原始的思想就是这样的,众生平等,轮流来
这种思路的一个好处是,任何一个进程的等待时间是有上限的,所以这种算法也是很流行的

分配给不同的进程时每次切换都要做一次上下文切换,对效率是有影响的

所以时间片长度的选择是很重要的

q大的话完成一个进程不需要做切换,就是先到显得了(FCFS),也不好
多层队列法
就绪队列中的进程是有不同的诉求的,有的侧重于低响应时间,有的侧重于充足的处理时间
前台侧重于响应时间,使用轮转法;后台对响应时间不那么敏感,使用先来先服务算法

不同队列间有不同的优先级

- 系统调度要尽量实时响应
- 交互要尽量及时
- 批处理和用户交互没什么关系,所以响应时间没那么重要

现在时间片的竞争主要是队列间的竞争
多层反馈队列法

反馈指的是就绪进程在队列间的迁移,这主要考虑到进程在不同情况下、任务下对实时性的需求是有变化的,有时候重交互,有时候重计算
举一个例子:



注意这只是调度方法中的一种,是否合理要看实际需求能否被满足
如何设计一个多层反馈队列:

实时调度
希望调度要很及时,但是不同任务的及时性的要求是不一样的
但是这一点是很难的,特别是通用性的操作系统,几乎不可能实现及时性(因为不同的进程要求不一样,用统一的调度方法当然不可能完全合适)
- 在嵌入式系统中使用硬实时调度,也就是时间节点是明确的,如果没有按时完成就作废
- 通用操作系统一般满足的是软实时调度,只能是尽量满足

调度算法的评估
要设计评估方法,尽量在早期就能对调度算法进行评估,不能依赖实际测试(因为开发周期长),所以下图中的第三种方案一般不靠谱。由于实际情况是非常复杂的,要确定和理论计算非常难,所以确定模型法也一般不靠谱

排队模型:先建立一个模型来模拟实际情况对算法进行测试,但是这对于模型的准确性就有了要求,要求其能尽可能反映实际使用场景,但是模型的准确率也是不容易很高的
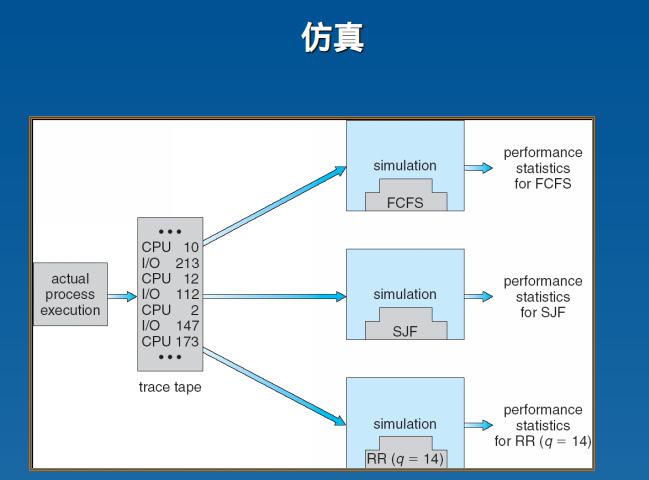
仿真:采集实际情况的数据,临时搭建平台进行测试,采集指标
这种方法的效果还是不错的,理论难度也比较低,是一种偏工程性的方法
linux调度算法
内存空间有4G,其中3G是用户空间,1G是内核空间
将优先权法和轮转法相结合:时间片到了之后引起中断响应,中断时从当前执行的进程的PCB拿出来,访问counter并减一,如果不等于0,就该进程继续响应;如果减到0,就重新设置counter(不设置统一的值,可以给每个进程设置一个值)、调用scheduler基于优先级重新调度
这是Linux较为早期时候的调度算法

sched_data:表示该CPU最近在为哪个进程在服务,该进程的上下文就保存在这里,这是为了多CPU而设置的
prev指向调度前的进程的PCB,next是将要调度给的进程的PCB,p是一个中间变量
tmp:用于优化用,没有实际含义
this_cpu:当前进程使用的是哪个CPU
c:临时变量,保存进程的优先权

和调度无关,如果有错就跳出,不继续调度

current指向当前执行进程的PCB。正如前面所说的那样,Linux操作系统中没有状态字来表示进程是正在执行的,TASK_RUNNING的含义是就绪状态。所以这里就用current来指向正在执行的进程的PCB

如果正在处于中断,就不继续调度了,直接返回

和同步相关

softirq:软中断。这里表示如果有软中断的工作还没有完成,就先去做这些工作



和调度直接相关。
轮转法:

如果prev的counter变成了0,就重新设置,注意设置时候传入的参数是prev->nice,也就是那个进程自己给自己设置的优先级,基于此(当然不光只考虑这一个参数)来重新设置counter


state表示进程状态
default处理其他状态的情况,从就绪队列中删除,不再继续执行
TASK_INTERRUPTABLE这个是怎么回事呢?它是为了处理这样一种特殊情况:
当前进程在执行的过程中需要进行一次中断,例如访问IO,但是正在它将自己的状态由TASK_RUNNING换为TASK_INTERRUPTABLE后,CPU时间片到期,通过中断发生了进程调度,它的counter也变成了0,被从current变成prev,加入了就绪队列的末尾。此时将它从TASK_INTERRUPTABLE状态恢复(也就是从等待队列中除去),也就是对于它的原有中断要放在之后再响应了

因为正在做调度(因为调度也是需要CPU时间的),所以不允许在下个时间片发生schedule()

先将next的初值置为idle task,也就是初始进程,并将其优先级设置为最小的。意思就是一般不调度这个原始进程,如果没有其他进程需要调度的话才调度,这个原始进程做一些进程监测和管理之类的工作


选择最高优先级的部分在still_running_back中完成
看算法,就是一次遍历


这种情况出现在所有进程的goodness都是0的情况下,意思就是就绪队列中的所有进程的counter都是0了,也就是时间片的时间都已经到了
recalculate:

注意这里使用了一个C语言的特性——复合语句,就是花括号括起来的部分,和代码块的概念比较类似。这里定义的局部变量只能在这里面使用,外部无法访问
>>1表示右移一位,也就是除2

然后再执行上面的still_running_back,就一定能选出c和next了

开始布置现场

这种不需要内存管理切换和上下文切换,所以之后到最后一步

kstat.content_switch记录了从开机以来的上下文切换次数

prepare_to_switch是做上下文切换的准备工作



注意一点,648行完了执行的还是649行吗?其实不是的,因为在648行已经完成了寄存器的转换,此时PC寄存器中保存的已经是另外的进程的PCB中的PC值了。649行何时执行呢?只有当这一次失去时间片的进程再次被调度才会被执行(会不会有不切换的情况呢,也就是获得调度的进程就是当前进程?这是不会的,因为看前面,如果不切换的话会直接从前面就调到same_process)

判断是否有调度需求,如果没有的话schedule()函数就结束了,返回内核中调用该函数处。
由此可见,schedule函数其实还做了dispatch的工作
goodness函数

什么是实时进程
https://blog.csdn.net/helloanthea/article/details/28877221
Linux的进程分普通进程和实时进程,普通进程即非实时进程SCHED_OTHER或SCHED_NORMAL,而实时进程又分SCHED_FIFO与SCHED_RR,实时进程的优先级(099)都比普通进程的优先级(100139)高,且直到死亡之前始终是活动进程,当系统中有实时进程运行时,普通进程几乎是无法分到时间片的(只能分到5%的CPU时间)。


out是什么呢:

out其实就是程序出口


将时间片的剩余值作为优先权,剩余时间越多越优先执行
mm是进程中管理内存的数据结构


优先权增加是因为不需要切换内存管理空间,上下文切换起来会更快

由此可见这里的nice是越小越好

评价
时间复杂度为O(n),n是就绪队列中的进程个数,这个应该比较好想,这个时间开销也还行,所以就一直用了。
但是有更好的:
优化
创建一个链表数组,数组的每个位置代表一个优先级,就绪状态的进程直接挂到数组的对应位置上。然后设置一个字节,表示当前有进程的最高的优先级是多少,这样调度的时候直接去找就好了。这种方法的复杂度是O(1)的
但是如果只使用一个数组的话,就会发生,高优先级的进程未完成的话会被反复调度,低优先级的进程无法获得时间片。所以实际上是设置了两个数组的,一个是active数组,一个是non_active数组,选择只在active数组进行,调度完成的进程回到non_active数组。只有当active数组上的进程都被调度一遍后,active数组和non_active数组交换(这是很简单的,只需要指向数组的指针交换一下就好)
但是这其实也不是十全十美的,例如它还有公平性的问题:有的应用程序可以开多进程从而有较大的可能性被调度执行,之后版本的Linux在此有了优化