package com.enation.newtest; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.commons.lang3.StringEscapeUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; // 爬取网易首页所有图片 public class Jsoup163 { public static void main(String[] args) throws Exception{ String downloadPath = "D:\360Downloads\test"; List<String> list = nameList("网易--首页"); getPictures(list,1,downloadPath); //1代表下载一页,一页一般有30张图片 } public static void getPictures(List<String> keywordList, int max,String downloadPath) throws Exception{ // key为关键词,max作为爬取的页数 String gsm=Integer.toHexString(max)+""; String finalURL = ""; String tempPath = ""; for(String keyword : keywordList){ tempPath = downloadPath; if(!tempPath.endsWith("\")){ tempPath = downloadPath+"\"; } tempPath = tempPath+keyword+"\"; File f = new File(tempPath); if(!f.exists()){ f.mkdirs(); } int picCount = 1; for(int page=1;page<=max;page++) { sop("正在下载第"+page+"页面"); Document document = null; try { String url ="http://www.163.com/"; sop(url); document = Jsoup.connect(url).data("query", "Java")//请求参数 .userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")//设置urer-agent get(); .timeout(5000) .get(); String xmlSource = document.toString(); xmlSource = StringEscapeUtils.unescapeHtml3(xmlSource); //sop(xmlSource); String reg = "<img.*src=(.*?)[^>]*?>"; String reg2 = "src\s*=\s*"?(.*?)("|>|\s+)"; String reg2datasrc = "data-src\s*=\s*"?(.*?)("|>|\s+)"; Pattern pattern = Pattern.compile(reg); Pattern pattern2 = Pattern.compile(reg2); Pattern pattern2datasrc = Pattern.compile(reg2datasrc); Matcher m = pattern.matcher(xmlSource); while (m.find()){ finalURL = m.group(); System.out.println(finalURL); Matcher m2 = null; if(finalURL.indexOf("data-src")>0){ m2 = pattern2datasrc.matcher(finalURL); }else { m2 = pattern2.matcher(finalURL); } if(m2.find()){ finalURL = m2.group(1); System.out.println(finalURL); if(finalURL.startsWith("http")){ sop(keyword+picCount+++":"+finalURL); download(finalURL,tempPath); sop(" 下载成功"); } } } } catch (IOException e) { e.printStackTrace(); } } } sop("下载完毕"); delMultyFile(downloadPath); sop("已经删除所有空图"); } public static void delMultyFile(String path){ File file = new File(path); if(!file.exists()) throw new RuntimeException("File ""+path+"" NotFound when excute the method of delMultyFile()...."); File[] fileList = file.listFiles(); File tempFile=null; for(File f : fileList){ if(f.isDirectory()){ delMultyFile(f.getAbsolutePath()); }else{ if(f.length()==0) sop(f.delete()+"---"+f.getName()); } } } public static List<String> nameList(String nameList){ List<String> arr = new ArrayList<String>(); String[] list; if(nameList.contains(",")) list= nameList.split(","); else if(nameList.contains("、")) list= nameList.split("、"); else if(nameList.contains(" ")) list= nameList.split(" "); else{ arr.add(nameList); return arr; } for(String s : list){ arr.add(s); } return arr; } public static void sop(Object obj){ System.out.println(obj); } //根据图片网络地址下载图片 public static void download(String url,String path){ //path = path.substring(0,path.length()-2); File file= null; File dirFile=null; FileOutputStream fos=null; HttpURLConnection httpCon = null; URLConnection con = null; URL urlObj=null; InputStream in =null; byte[] size = new byte[1024]; int num=0; try { String downloadName= url.substring(url.lastIndexOf("/")+1); dirFile = new File(path); if(!dirFile.exists() && path.length()>0){ if(dirFile.mkdir()){ sop("creat document file ""+path.substring(0,path.length()-1)+"" success... "); } }else{ file = new File(path+downloadName); fos = new FileOutputStream(file); if(url.startsWith("http")){ urlObj = new URL(url); con = urlObj.openConnection(); httpCon =(HttpURLConnection) con; int responseCode = httpCon.getResponseCode(); if(responseCode == 200){ in = httpCon.getInputStream(); while((num=in.read(size)) != -1){ for(int i=0;i<num;i++) fos.write(size[i]); } }else { System.out.println("状态码:"+responseCode+" 地址:"+url); } } } }catch (FileNotFoundException notFoundE) { sop("找不到该网络图片...."); }catch(NullPointerException nullPointerE){ sop("找不到该网络图片...."); }catch(IOException ioE){ sop("产生IO异常....."); }catch (Exception e) { e.printStackTrace(); }finally{ try { if(fos!=null){ fos.close(); } } catch (Exception e) { e.printStackTrace(); } } } }
其中,关键点在于获取图片img标签的正则表达式和图片的链接地址
String reg = "<img.*src=(.*?)[^>]*?>";
String reg2 = "src\s*=\s*"?(.*?)("|>|\s+)";
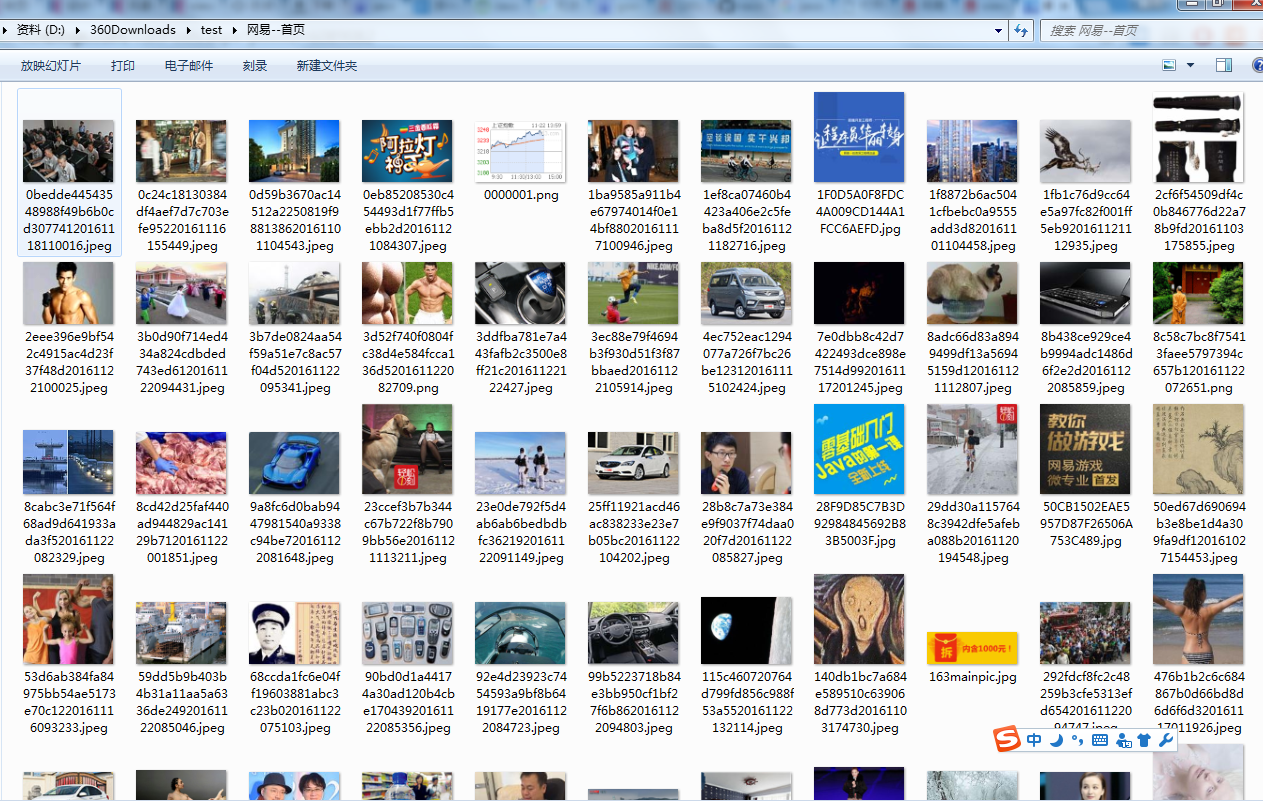
运行结果: