基于scoll+bulk+索引别名实现零停机重建索引
1、重建索引
一个field的设置是不能被修改的,如果要修改一个Field,那么应该重新按照新的mapping,建立一个index,然后将数据批量查询出来,重新用bulk api写入index中
批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来reindex数据,每次scoll就查询指定日期的一段数据,交给一个线程即可
(1)一开始,依靠dynamic mapping,插入数据,但是不小心有些数据是2017-01-01这种日期格式的,所以title这种field被自动映射为了date类型,实际上它应该是string类型的
PUT /my_index/my_type/3
{
"title": "2017-01-03"
}
查看自动构建的type类型
{
"my_index":{
"mappings":{
"my_type":{
"properties":{
"title":{
"type":"date"
}
}
}
}
}
}
(2)当后期向索引中加入string类型的title值的时候,就会报错
PUT /my_index/my_type/4
{
"title": "my first article"
}
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse [title]"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse [title]",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Invalid format: "my first article""
}
},
"status": 400
}
(3)如果此时想修改title的类型,是不可能的
PUT /my_index/_mapping/my_type
{
"properties":{
"title":{
"type":"text"
}
}
}
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "mapper [title] of different type, current_type [date], merged_type [text]"
}
],
"type": "illegal_argument_exception",
"reason": "mapper [title] of different type, current_type [date], merged_type [text]"
},
"status": 400
}
(4)此时,唯一的办法,就是进行reindex,也就是说,重新建立一个索引,将旧索引的数据查询出来,再导入新索引
(5)如果说旧索引的名字,是old_index,新索引的名字是new_index,终端java应用,已经在使用old_index在操作了,难道还要去停止java应用,修改使用的index为new_index,才重新启动java应用吗?这个过程中,就会导致java应用停机,可用性降低
(6)所以说,给java应用一个别名,这个别名是指向旧索引的,java应用先用着,java应用先用goods_index alias来操作,此时实际指向的是旧的my_index
PUT /my_index/_alias/goods_index
(7)新建一个index,调整其title的类型为string
PUT /my_index_new
{
"mappings":{
"my_type":{
"properties":{
"title":{
"type":"text"
}
}
}
}
}
(8)使用scroll api将数据批量查询出来
GET /my_index/_search?scroll=1m
{
"query":{
"match_all":{
}
},
"sort":[
"_doc"
],
"size":1
}
{
"_scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAADpAFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAA6QRY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAAOkIWNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAADpDFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAA6RBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3",
"took":1,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0
},
"hits":{
"total":3,
"max_score":null,
"hits":[
{
"_index":"my_index",
"_type":"my_type",
"_id":"2",
"_score":null,
"_source":{
"title":"2017-01-02"
},
"sort":[
0
]
}
]
}
}
(9)采用bulk api将scoll查出来的一批数据,批量写入新索引
POST /_bulk
{ "index": { "_index": "my_index_new", "_type": "my_type", "_id": "2" }}
{ "title": "2017-01-02" }
(10)反复循环8~9,查询一批又一批的数据出来,采取bulk api将每一批数据批量写入新索引
(11)将goods_index alias切换到my_index_new上去,java应用会直接通过index别名使用新的索引中的数据,java应用程序不需要停机,零提交,高可用
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index", "alias": "goods_index" }},
{ "add": { "index": "my_index_new", "alias": "goods_index" }}
]
}
(12)直接通过goods_index别名来查询,是否ok
GET /goods_index/my_type/_search
2、基于alias对client透明切换index
PUT /my_index_v1/_alias/my_index
client对my_index进行操作
reindex操作,完成之后,切换v1到v2
POST /_aliases
{
"actions":[
{
"remove":{
"index":"my_index_v1",
"alias":"my_index"
}
},
{
"add":{
"index":"my_index_v2",
"alias":"my_index"
}
}
]
}
倒排索引
倒排索引,是适合用于进行搜索的
倒排索引的结构
(1)包含这个关键词的document list
(2)包含这个关键词的所有document的数量:IDF(inverse document frequency)
(3)这个关键词在每个document中出现的次数:TF(term frequency)
(4)这个关键词在这个document中的次序
(5)每个document的长度:length norm
(6)包含这个关键词的所有document的平均长度
倒排索引不可变的好处
(1)不需要锁,提升并发能力,避免锁的问题
(2)数据不变,一直保存在os cache中,只要cache内存足够
(3)filter cache一直驻留在内存,因为数据不变
(4)可以压缩,节省cpu和io开销
倒排索引不可变的坏处:每次都要重新构建整个索引
写入流程实现durability可靠存储
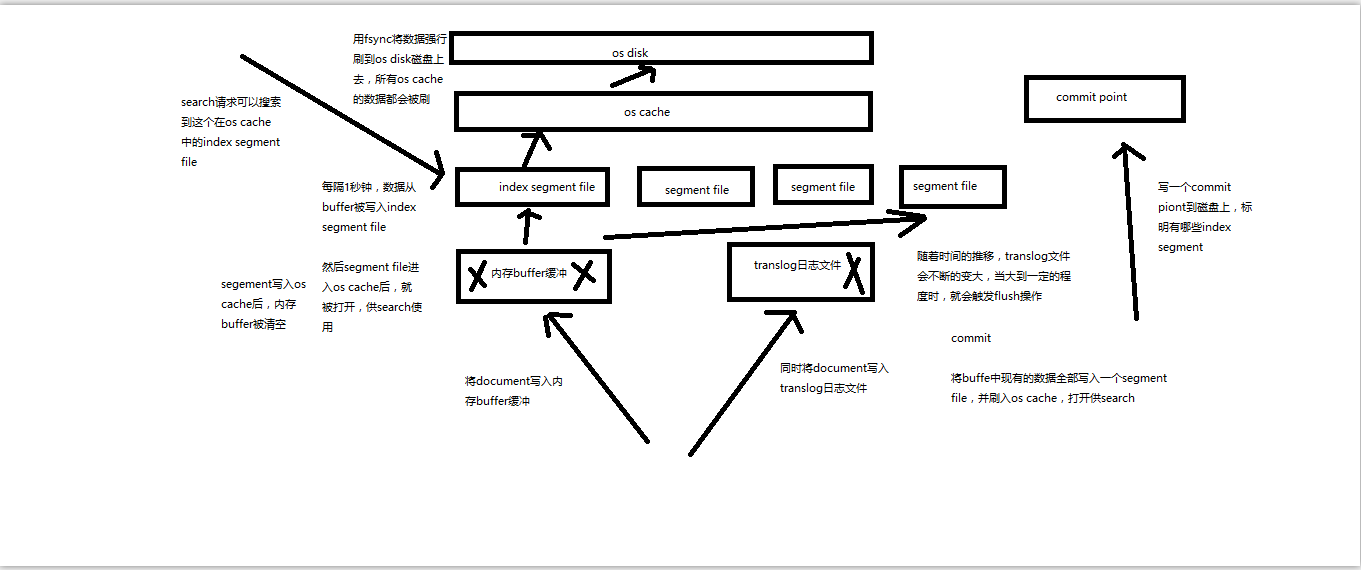
再次优化的写入流程
(1)数据写入buffer缓冲和translog日志文件
(2)每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用
(3)buffer被清空
(4)重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
(5)当translog长度达到一定程度的时候,commit操作发生
(5-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
(5-2)buffer被清空
(5-3)一个commit ponit被写入磁盘,标明了所有的index segment
(5-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
(5-5)现有的translog被清空,创建一个新的translog
基于translog和commit point,如何进行数据恢复
fsync+清空translog,就是flush,默认每隔30分钟flush一次,或者当translog过大的时候,也会flush
POST /my_index/_flush,一般来说别手动flush,让它自动执行就可以了
translog,每隔5秒被fsync一次到磁盘上。在一次增删改操作之后,当fsync在primary shard和replica shard都成功之后,那次增删改操作才会成功
但是这种在一次增删改时强行fsync translog可能会导致部分操作比较耗时,也可以允许部分数据丢失(5s),设置异步fsync translog
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}

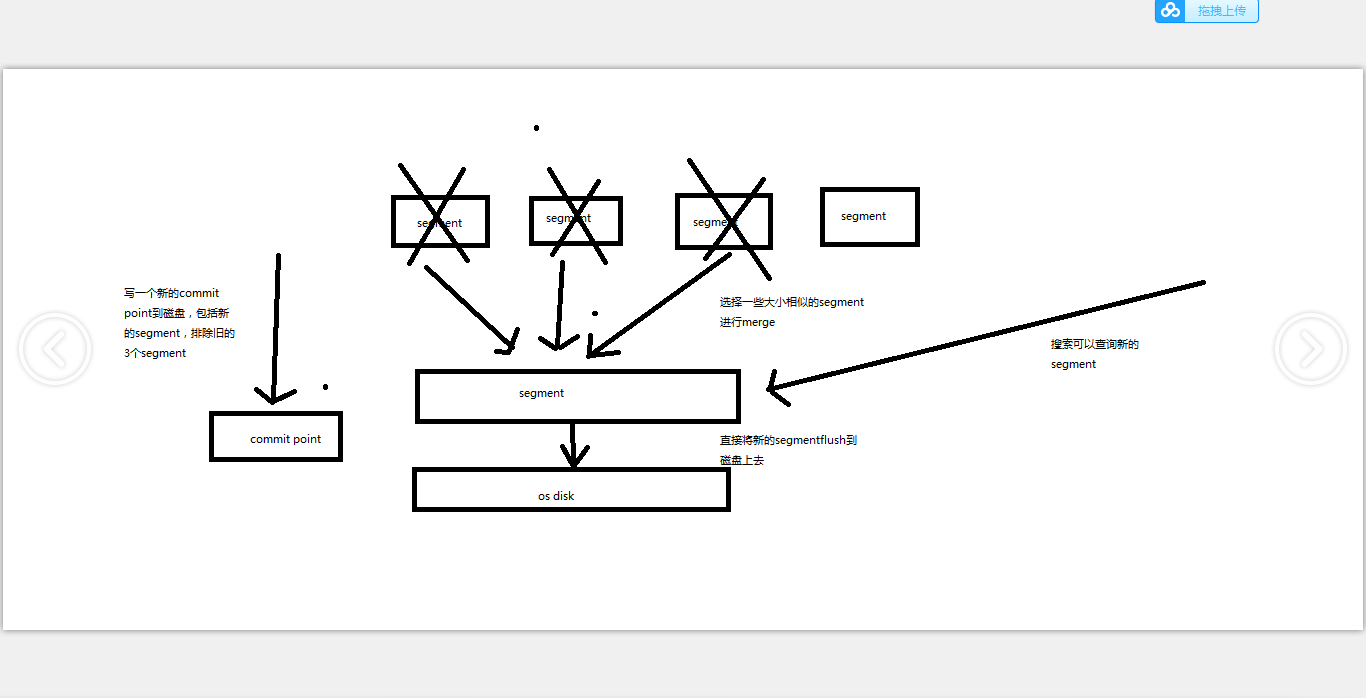
每秒一个segment file,文件过多,而且每次search都要搜索所有的segment,很耗时
默认会在后台执行segment merge操作,在merge的时候,被标记为deleted的document也会被彻底物理删除
每次merge操作的执行流程
(1)选择一些有相似大小的segment,merge成一个大的segment
(2)将新的segment flush到磁盘上去
(3)写一个新的commit point,包括了新的segment,并且排除旧的那些segment
(4)将新的segment打开供搜索
(5)将旧的segment删除