环境 Linux tomcat7 solr

上linux解压IK 和 solr 新建文件夹保存
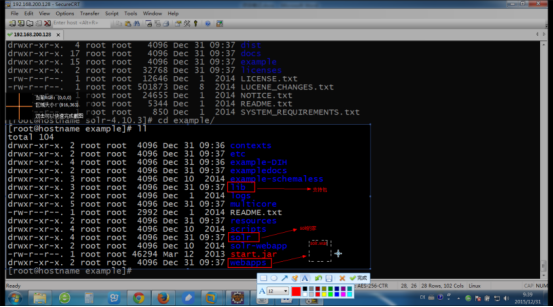

1第一步复制jar solor>example > ext 下的所有的jar拷贝至tomcat的lib下
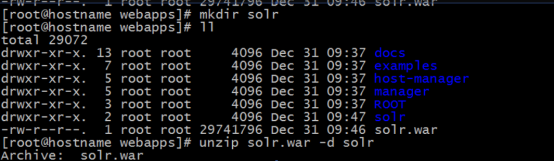
2将solr.war拷贝至tomcat的webapps下注意解压 war解压不会保留目录一定要先创建一个文件夹 mkdir solr。 然后将其解压至该文件夹中解压war使用unzip命令 然后删除其war包 不删除tomcat的运行将其解压会替换

 3进入tomcat的solr解压下面然后
3进入tomcat的solr解压下面然后
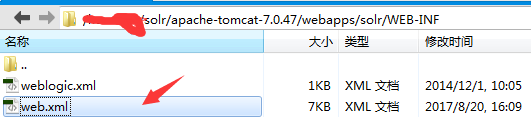
注意去掉注释 让其找到solr的家一定要注意路径,楼主不是用的root是普通权限

IK分词器、
将ik包解压到一个文件夹中
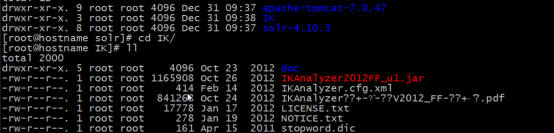



1
2
2步
完成第二步可以启动Tomcat http://linuxIp:8081/solr/#/
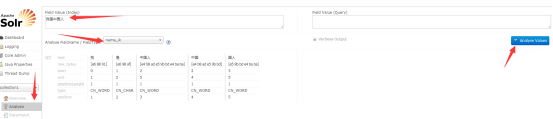
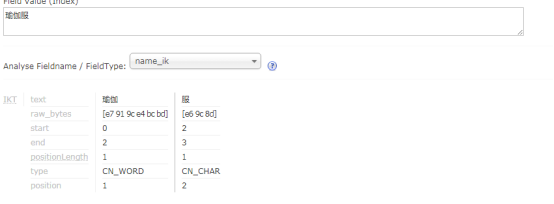
 就看看这文件>,<
就看看这文件>,<
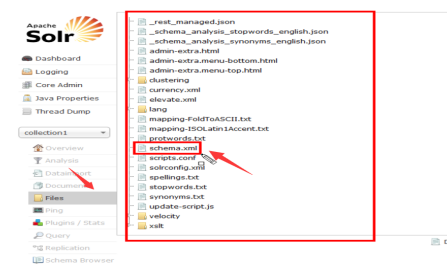
移动区至solr家里的conf目录找到配置文件
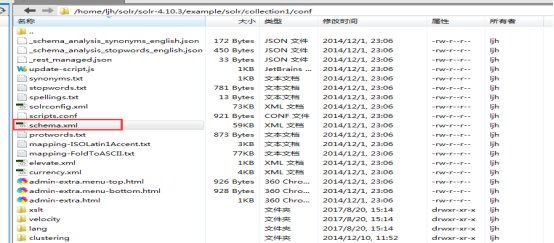
==========================================
<!-- 自定义数据类型 支持IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<field name="name_ik" type="text_ik" indexed="true" stored="true"/>

==================================================
扩展词

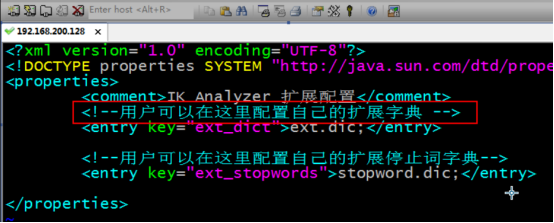
打开注释
2创建文件ext.dic

编辑

停止词
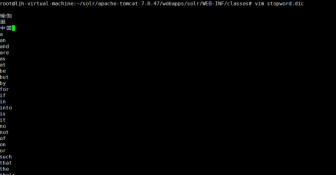
不能全部在一行 ,只能一行一个词
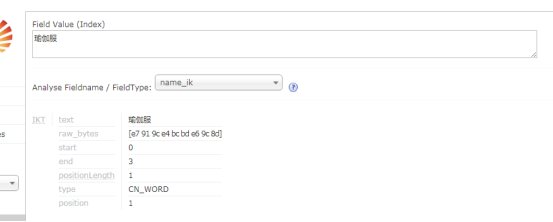
效果明显和上面不一样了,,,,
Ubuntu上时刻要记住权限的问题 害我找了好久,用root权限启动就OK了
http://blog.csdn.net/u013022826/article/details/58198993
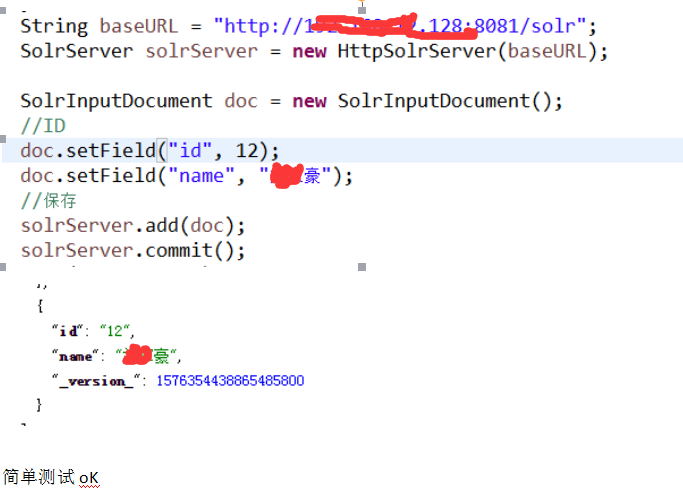

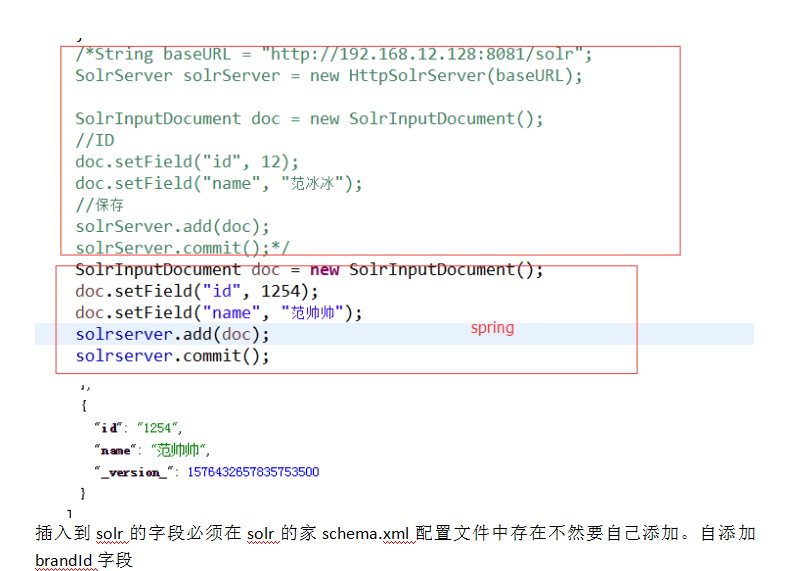
使用Spring插入数据
SolrInputDocument doc = new SolrInputDocument();
doc.setField("id", s);
doc.setField("name_ik", ption.getPtname());
float sourceF = Float.valueOf(ption.getMoney());
doc.setField("price", sourceF);
doc.setField("description",ption.getIntroduce());
doc.setField("brandId",ption.getPttype());
solrserver.add(doc);
solrserver.commit();
ptservice.addPt(ption);


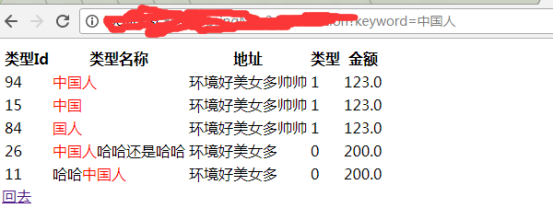
从solr服务器拿数据展示 Spring
public List<Position> selectPositionListFormDolr(String keyWord){
List<Position> position =new ArrayList<Position>();
SolrQuery solrQuery =new SolrQuery();
StringBuilder params=new StringBuilder();
params.append("keyWord=").append(keyWord);
solrQuery.set("q", "name_ik:"+keyWord);
solrQuery.setStart(0);
solrQuery.setRows(20);
solrQuery.addSort("price", ORDER.asc);//排序
solrQuery.setHighlight(true);//开启高亮
solrQuery.addHighlightField("name_ik");//设置高亮字段
solrQuery.setHighlightSimplePre("<span style='color:red'>");
solrQuery.setHighlightSimplePost("</span>");
try {
QueryResponse resp = solrServer.query(solrQuery);
//去高亮
Map<String, Map<String, List<String>>> highlighting = resp.getHighlighting();
SolrDocumentList results = resp.getResults();
System.out.println(results.size());
for(int i=0;i<results.size();i++){
Position positionObj =new Position();
String Id = (String) results.get(i).get("id");
//String name = (String) results.get(i).get("name_ik");从高亮容器中去名称
String description = (String) results.get(i).get("description");
String brandid = (String) results.get(i).get("brandId");
Object object = results.get(i).get("price");
positionObj.setMoney(object.toString());
positionObj.setPttype(brandid);
positionObj.setIntroduce(description);
Map<String, List<String>> map = highlighting.get(Id);//第二个Map
List<String> list = map.get("name_ik");//设置关键字
positionObj.setPtname(list.get(0));
positionObj.setPtid(Id);
position.add(positionObj);
}
results.getNumFound();
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return position;
}
好啦几天的solr练习全部奉上。。。。如果那里不是很清楚就多百度百度吧>><<