哈希表
什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。(或者:把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。)
其中,记录的位置 = H(关键字),H称为哈希函数。
哈希构造方法
-
直接定址法
例如如果我们现在要对0-100岁的人口数字统计表,那么我们对年龄这个关键字就可以直接用年龄的数字作为地址。此时f(key) = key。
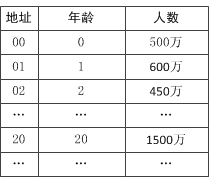
这个时候,我们可以得出这么个哈希函数:f(0) = 0,f(1) = 1,……,f(20) = 20。这个是根据我们自己设定的直接定址来的。人数我们可以不管,我们关心的是如何通过关键字找到地址。
-
除留余数法
除留余数法此方法为最常用的构造散列函数方法。对于散列表长为m的散列函数公式为:
$$
f( key ) = key mod p ( p ≤ m )
$$mod是取模(求余数)的意思。事实上,这方法不仅可以对关键字直接取模,也可在折叠、平方取中后再取模。
-
数字分析法
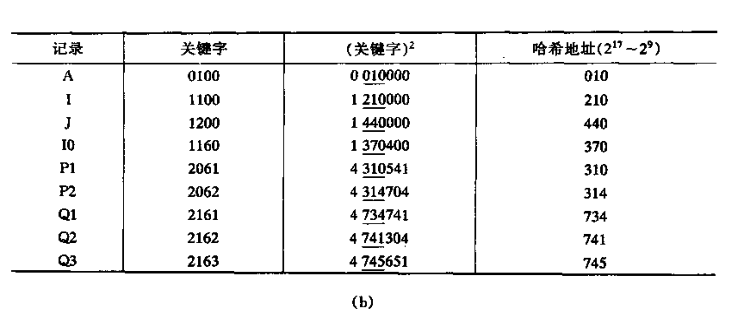
如下图所示,有80个记录,每一行为一个记录中的键,假设表长为100,则可取两位十进制数组成哈希地址。

-
折叠法
将关键字分成位数相同的几部分(最后一位可以不同),然后取叠加和作为哈希地址,这一方法被称为折叠法。当表的键位数很多,而且每一位上数字分布比较均匀的时候, 可以考虑采用这一方法。 折叠法有移位叠加和间位叠加两种方法例如国际标准图书编号0-442-20586-4的哈希地址可以用这两种方法表示为

-
平方取中法
取关键字平方后的中间几位为哈希地址,这种方法叫做平方取中法。它弥补了数字分析法的一些缺陷,因为我们有时并不能知道键的全部情况,取其中几位也不一定合适,而一个数平方后的中间几个数和原数的每一位都相关,由此我们就能得到随机性更强的哈希地址取的位数由表长决定。
哈希表处理冲突的方法
-
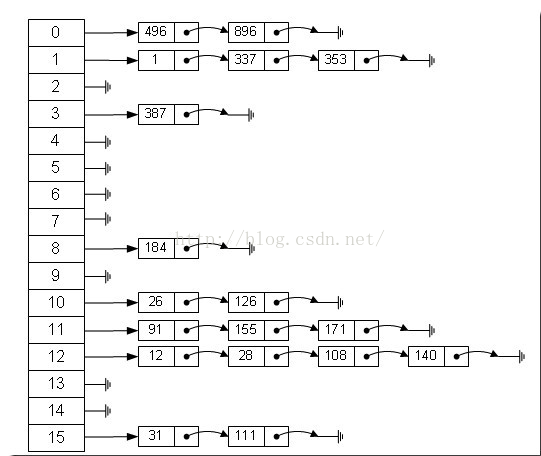
链地址法
冲突的关键字存储在一个链表中,查找的时候可能需要遍历链表。例如下面:
-
开放地址法
开放定址法是指可存放新表项的空闲地址,既向它的同义词表项开放,又向它的非同义词表项开放。
一般有一个递推公式:l
$$H_i = (H(key) + d_i) % m$$
式中,i = 1,2,…,k,m为散列表表长,$d_i$为增量序列。$d_i$通常有以下几种取法:
- 当$d_i = 1,2,…,m - 1$时,称为线性探测法。其特点是,冲突发生时顺序查看表中下一个单元,直到找出一个空单元或查遍全表。
- 当$d_i = 12,-12,22,-22,…,k^2,-k2$时,又称为二次探测法。
- 当$d_i$ = 伪随机数序列时,称为伪随机探测法。
-
再散列法
当发生冲突时,再利用一个新的哈希函数计算得到一个新的地址,直到不发生冲突时进行存放。
-
公共溢出区
所有发生冲突的关键字都存储在这个公共溢出区,当查找不到的时候来这里查找。
哈希表的优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
数据结构及图示
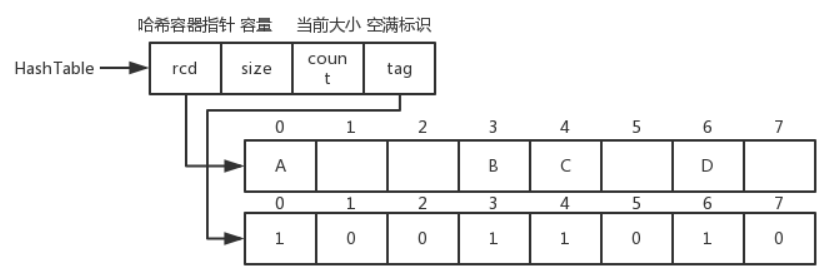
线性探测的哈希表数据结构和图片
typedef char KeyType;
typedef struct {
KeyType key;
}RcdType;
typedef struct {
RcdType *rcd;
int size;
int count;
bool *tag;
}HashTable;
哈希表实现:
#include<stdio.h>
#include<stdlib.h>
#define SUCCESS 1
#define UNSUCCESS 0
#define OVERFLOW -1
#define OK 1
#define ERROR -1
#define MAXNUM 9999 // 用于初始化哈希表的记录 key
typedef int Status;
typedef int KeyType;
// 哈希表中的记录类型
typedef struct {
KeyType key;
}RcdType;
// 哈希表类型
typedef struct {
RcdType *rcd;
int size;
int count;
int *tag;
}HashTable;
// 哈希表每次重建增长后的大小
int hashsize[] = { 11, 31, 61, 127, 251, 503 };
int index = 0;
// 初始哈希表
Status InitHashTable(HashTable &H, int size) {
int i;
H.rcd = (RcdType *)malloc(sizeof(RcdType)*size);
H.tag = (int *)malloc(sizeof(int)*size);
if (NULL == H.rcd || NULL == H.tag) return OVERFLOW;
KeyType maxNum = MAXNUM;
for (i = 0; i < size; i++) {
H.tag[i] = 0;
H.rcd[i].key = maxNum;
}
H.size = size;
H.count = 0;
return OK;
}
// 哈希函数:除留余数法
int Hash(KeyType key, int m) {
return (3 * key) % m;
}
// 处理哈希冲突:线性探测
void collision(int &p, int m) {
p = (p + 1) % m;
}
// 在哈希表中查询
Status SearchHash(HashTable H, KeyType key, int &p, int &c) {
p = Hash(key, H.size);
int h = p;
c = 0;
while ((1 == H.tag[p] && H.rcd[p].key != key) || -1 == H.tag[p]) {
collision(p, H.size); c++;
}
if (1 == H.tag[p] && key == H.rcd[p].key) return SUCCESS;
else return UNSUCCESS;
}
//打印哈希表
void printHash(HashTable H)
{
int i;
printf("key : ");
for (i = 0; i < H.size; i++)
printf("%3d ", H.rcd[i].key);
printf("
");
printf("tag : ");
for (i = 0; i < H.size; i++)
printf("%3d ", H.tag[i]);
printf("
");
}
// 函数声明:插入哈希表
Status InsertHash(HashTable &H, KeyType key);
// 重建哈希表
Status recreateHash(HashTable &H) {
RcdType *orcd;
int *otag, osize, i;
orcd = H.rcd;
otag = H.tag;
osize = H.size;
InitHashTable(H, hashsize[index++]);
//把所有元素,按照新哈希函数放到新表中
for (i = 0; i < osize; i++) {
if (1 == otag[i]) {
InsertHash(H, orcd[i].key);
}
}
return OK;
}
// 插入哈希表
Status InsertHash(HashTable &H, KeyType key) {
int p, c;
if (UNSUCCESS == SearchHash(H, key, p, c)) { //没有相同key
if (c*1.0 / H.size < 0.5) { //冲突次数未达到上线
//插入代码
H.rcd[p].key = key;
H.tag[p] = 1;
H.count++;
return SUCCESS;
}
else recreateHash(H); //重构哈希表
}
return UNSUCCESS;
}
// 删除哈希表
Status DeleteHash(HashTable &H, KeyType key) {
int p, c;
if (SUCCESS == SearchHash(H, key, p, c)) {
//删除代码
H.tag[p] = -1;
H.count--;
return SUCCESS;
}
else return UNSUCCESS;
}
int main()
{
printf("-----哈希表-----
");
HashTable H;
int i;
int size = 11;
KeyType array[8] = { 22, 41, 53, 46, 30, 13, 12, 67 };
KeyType key;
//初始化哈希表
printf("初始化哈希表
");
if (SUCCESS == InitHashTable(H, hashsize[index++])) printf("初始化成功
");
//插入哈希表
printf("插入哈希表
");
for (i = 0; i <= 7; i++) {
key = array[i];
InsertHash(H, key);
printHash(H);
}
//删除哈希表
printf("删除哈希表中key为12的元素
");
int p, c;
if (SUCCESS == DeleteHash(H, 12)) {
printf("删除成功,此时哈希表为:
");
printHash(H);
}
//查询哈希表
printf("查询哈希表中key为67的元素
");
if (SUCCESS == SearchHash(H, 67, p, c)) printf("查询成功
");
//再次插入,测试哈希表的重建
printf("再次插入,测试哈希表的重建:
");
KeyType array1[8] = { 27, 47, 57, 47, 37, 17, 93, 67 };
for (i = 0; i <= 7; i++) {
key = array1[i];
InsertHash(H, key);
printHash(H);
}
getchar();
return 0;
}
参考链接: