一、直接插入排序
直接插入排序(straight insertion sort)的做法是:
每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍然有序。
第一趟比较前两个数,然后把第二个数按大小插入到有序表中; 第二趟把第三个数据与前两个数从后向前扫描,把第三个数按大小插入到有序表中;依次进行下去,进行了(n-1)趟扫描以后就完成了整个排序过程。
1 void insertSort(int arr[],int len) 2 { 3 int i,j; 4 for(i = 1; i < len; ++i) 5 { 6 for(j = i; j > 0 && arr[j] < arr[j-1]; --j)//j为待排序序列头部 7 { 8 int tmp = arr[j]; 9 arr[j] = arr[j-1]; 10 arr[j-1] = tmp; 11 } 12 } 13 }
直接插入排序总结:
时间复杂度:平均情况O(n2),最好情况O(n),最坏情况O(n2)
空间复杂度:O(1)
稳定性:稳定
直接插入排序较为简单,一笔带过,我们下面看看另一种优化的插入排序---Shell排序。
二、Shell排序
观察一下”插入排序“:其实不难发现它有个缺点:
如果当数据是“5, 4, 3, 2, 1”的时候,此时我们将“待排序序列”中的记录插入到“有序序列”时,每次比较都要挪动数据,此时插入排序的效率可想而知。
shell根据这个弱点进行了算法改进,融入了一种叫做“缩小增量排序法”的思想,其实也蛮简单的,不过有点注意的就是:增量不是乱取,而是有规律可循的。
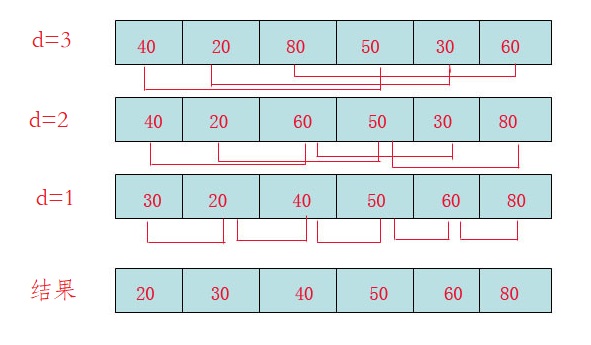
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
插入类排序的特点就是:越有序越快。
#include <stdio.h>
void Shell(int arr[],int arr_len,int dk)
{
int i,j;
//此时dk就是一个单位长度,相当于直接插入排序中的1
for(i = dk; i < arr_len; ++i)
{
for(j = i - dk; j >= 0 && arr[j+dk] < arr[j]; j -=dk)
{
int tmp = arr[j+dk];
arr[j+dk] = arr[j];
arr[j] = tmp;
}
}
}
void ShellSort(int arr[],int arr_len,int dka[],int dka_len)//分组
{
int i;
for (i = 0; i < dka_len; i++)
{
Shell(arr,arr_len,dka[i]);
}
}
void Show(int arr[],int len)
{
for(int i = 0; i < len; i++)
{
printf("%d ",arr[i]);
}
printf("
");
}
int main ()
{
int arr[] = {-1,12,3,44,3,52,6,23,43,32,24,67,5,10,1,21};
int dk[] = {5,3,1};
int len = sizeof(arr)/sizeof(arr[0]);
int lenDk = sizeof(dk)/sizeof(dk[0]);
printf("before:
");
Show(arr,len);
ShellSort(arr,len,dk,lenDk);
printf("after:
");
Show(arr,len);
return 0;
}
那么如何选取关键字呢?就是分成三组,一组,这个分组的依据是什么呢?为什么不是二组,六组或者其它组嘞?
增量序列的共同特征:
① 最后一个增量必须为1(如果最后一个增量不为1,会出现有数据没有参加排序)
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况(如果为倍数,相当于,后面的排序再重复之前的行为)
Shell排序总结:
时间复杂度:平均情况O(n1.3),最好情况O(n),最坏情况O(n2)
空间复杂度:O(1)
稳定性:不稳定
优劣: