1、what?
JUC就是java.util.concurrent下面的类包,专门用于多线程的开发。
2、why?
解决多线程、高并发
3、how?
||
||
﹀
question1:多个线程共享资源时,彼此不可见; 可以给资源加锁,但是加锁,线程会阻塞,效率较低;如何在不使用锁的情况下,更新资源,即给资源加上volatile关键字。
point2:原子性
原子变量:Java提供了原子变量,在java.util.concurrent.atomic包下; 使用CAS(Compare And Swap)来保证原子性;当内存值==预估值时,我才会把更新值更新到内存。但此时会出现一个ABA问题,即一个线程修改变量A,为B再改回A,此时CAS察觉不到,被修改了,当然基本数据类型是不要紧的,但如果是引用数据呢?这个对象中有多个变量,我不知道有没有被修改。因此,增加版本号就成了一个很好的选择;
point3:锁分段机制
在java.util.concurrent包中提供了多种并发容器类来改进同步容器类的性能。其中最主要的就是ConcurrentHashMap。 ConcurrentHashMap采用了分段锁机制,是一个线程安全的hash表,我们知道HashMap不是线程安全的,HashTable加了锁,是线程安全的,因此他效率低。而ConcurrentHashMap默认分成了16个segment,每个segment对应一个hash表,且有自己独立的锁。所以每一个线程访问一个segment,就可以并行访问了,这大大的提高了效率;
point4:锁
1、传统锁synchronized关键字:
a、锁代码块、锁类; b、当这个关键字锁到一个带有static的方法时,锁的是这个类模板。
class X{ public Synchronized void f(){ methods body... } }
2、Lock接口:
是在juc包下的,首先要声明一个可重入锁; 有三个实现类:ReentrantLock(可重入锁 常用)、 ReentrantReadWriteLock.ReadLock(读锁)、ReentrantReadWriteLock.WriteLock(写锁)
class X{ Lock lock = new ReentrantLock(); public void f(){ lock.lock; try{ method body..... }finally{ lock.unlock; } } }
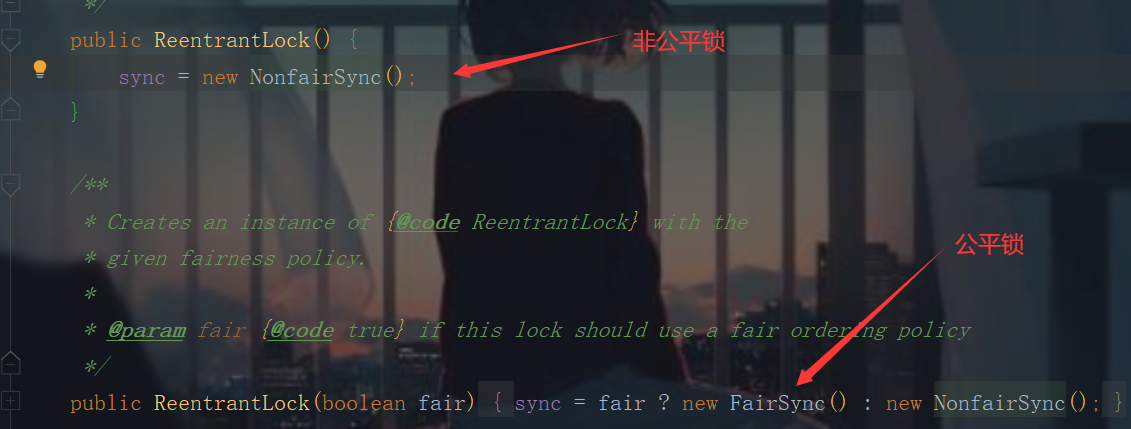
1、公平锁:十分公平,先来后到;
2、非公平锁:十分不公平,可以插队(默认);
3.lock与Synchronized的区别
>1、Synchronized是内置关键字;Lock是接口;
>2、Synchronized无法判断获取锁的状态;Lock可以判断;
>3、Synchronized会自动释放锁;Lock需要手动释放,不释放会出现死锁现象;
>4、Synchronized(当a线程获取锁并阻塞,b线程会一直等);Lock不会这样(tryLock()方法,当目前可以获取锁时返回true,反之false)
>5、Synchronized是可重入锁、不可中断、非公平锁;Lock可重入、可判断锁、公平性(可以自定义),扩展性更好;
>6、Synchronized可以锁少量同步代码;Lock可以锁大量的同步代码;
4、锁的类型
可重入锁:拿到外面的锁后,会自动拿到里面的锁;
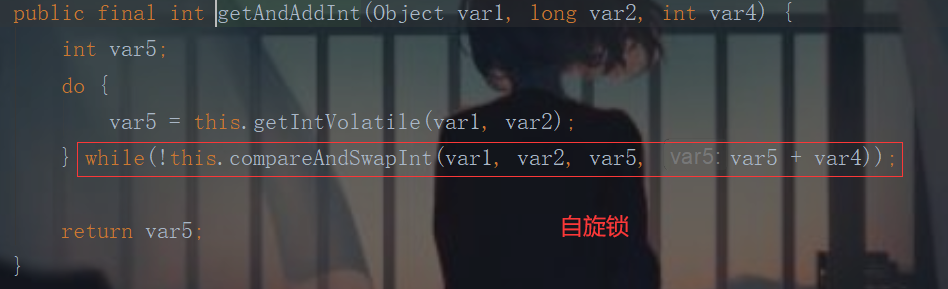
自旋锁:
point5:生产者和消费者问题
1、线程之间通信问题:生产者和消费者问题!
2、三部曲:判断是否需要等待 this.wait() 、业务、通知 this.notifyAll()
3、线程的虚假唤醒问题,将if()改为while()判断;
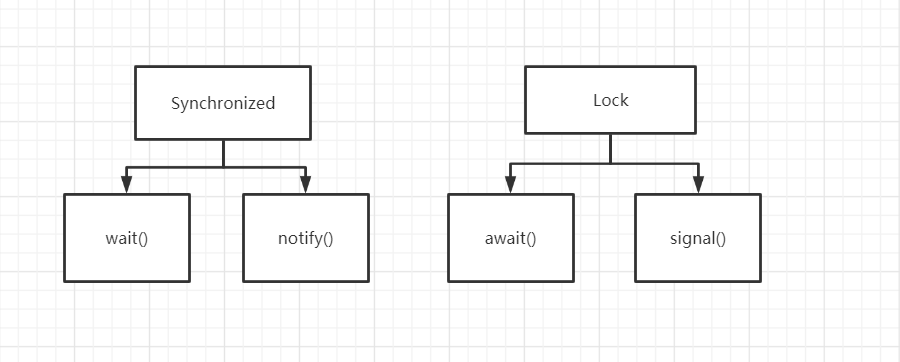
Condition condition = lock.newCondition();
condition.await();//等待
condition.signal();//通知
Condition实现精确通知
Condition condition1 = lock1.newCondition();
Condition condition2 = lock2.newCondition();
Condition condition3 = lock3.newCondition();
例子:当前condition1,要通知condition3,则要condition3.signal();
point6:8锁现象
解释见:https://blog.csdn.net/makyan/article/details/104524725
point7:集合不安全
异常:ConcurrentModificationException,并发修改异常;
解决方案:
List<String> list =new ArrayList<String>();
1、List<String> list = new Vector(); --->被synchronized修饰的方法效率很低;
2、List<String> list = Collections.syncronizedList(new ArrayList<>());
3、List<String> list = new CopyOnWriteArrayList<>();
Set<String> set = new HashSet<>();
1、Set<String> set = Collections.synchroniazedSet(new HashSet<>());
2、Set<String> set = new CopyOnWriteArraySet<>(); HashSet本质就是用了HashMap的key不重复来实现去重的;
Map<String,String> map = new HashMap<>();
1、Map<String,String> map = Collections.synchronizedMap<>();
2、Map<String,String>map = new ConcurrentHashMap<>();--->详情见point3
point8:Callable与Runable
先看一下两个接口的定义:
Callable
public interface Callable<V> {
V call() throws Exception;
}
Runnable
interface Runnable {
public abstract void run();
}
和明显能看到区别:
1.Callable能接受一个泛型,然后在call方法中返回一个这个类型的值。而Runnable的run方法没有返回值
2.Callable的call方法可以抛出异常,而Runnable的run方法不会抛出异常。
point9:常用辅助类
1、CountDownLatch 减法计数器
CountDownLatch count=new CountDownLatch(5); for (int i = 1; i <=5 ; i++) { new Thread(()->{ System.out.println(Thread.currentThread().getName()+"go out"); count.countDown();//count-- },String.valueOf(i)).start(); } count.await();//等待计数器归零,然后向下执行 System.out.println("over");
2、CyclicBarrier 加法计数器(集齐七龙珠召唤神龙)
CyclicBarrier cyclicBarrier = new CyclicBarrier(7,()-> System.out.println("召唤神龙")); for (int i = 1; i <=7 ; i++) { final int temp = i; new Thread(()->{ System.out.println(Thread.currentThread().getName()+"收集第"+temp+"个龙珠"); try { cyclicBarrier.await();//等待 } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } },String.valueOf(i)).start(); }
3、Semaphore 流量
停车位,限流;三个车位,六辆车;
//有3个停车位,有六辆车 Semaphore semaphore = new Semaphore(3); for (int i = 1; i <=6 ; i++) { new Thread(()->{ try { semaphore.acquire();//获取许可 System.out.println(Thread.currentThread().getName()+"抢到车位"); TimeUnit.SECONDS.sleep(2); System.out.println(Thread.currentThread().getName()+"离开车位"); } catch (InterruptedException e) { e.printStackTrace(); }finally{ semaphore.release();//释放信号 } },String.valueOf(i)).start(); }
point10:读写锁
ReentrantReadWriteLock 看一下jdk源码:

point11:阻塞队列BlockingQueue
1、使用情况:
2、四种API:
| 方法 | 抛出异常 | 有返回值,不抛异常 | 阻塞等待 | 超时等待 |
|---|---|---|---|---|
| 添加 | add() | offer() | put | offer(Object o,Long timeout,TimeUnit t) |
| 移除 | remove() | poll() | take | poll(Long timeout,TimeUnit t) |
| 检测队首 | element() | peek |
/** * 抛出异常 */ public static void test1(){ ArrayBlockingQueue arrayBlockingQueue = new ArrayBlockingQueue(3); System.out.println(arrayBlockingQueue.add("a")); System.out.println(arrayBlockingQueue.add("b")); System.out.println(arrayBlockingQueue.add("c")); //检查队首元素 System.out.println(arrayBlockingQueue.element()); System.out.println("================="); System.out.println(arrayBlockingQueue.remove()); System.out.println(arrayBlockingQueue.remove()); System.out.println(arrayBlockingQueue.remove()); }
/** * 有返回值,不抛出异常 */ public static void test2(){ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue(3); System.out.println(blockingQueue.offer("a")); System.out.println(blockingQueue.offer("b")); System.out.println(blockingQueue.offer("c")); System.out.println(blockingQueue.offer("c")); //查看队首元素 System.out.println(blockingQueue.peek()); System.out.println("======================="); System.out.println(blockingQueue.poll()); System.out.println(blockingQueue.poll()); System.out.println(blockingQueue.poll()); System.out.println(blockingQueue.poll()); }
/** * 阻塞等待 */ public static void test3(){ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue(3); try { blockingQueue.put("a"); blockingQueue.put("b"); blockingQueue.put("c"); System.out.println("==="); blockingQueue.take(); blockingQueue.take(); blockingQueue.take(); } catch (InterruptedException e) { e.printStackTrace(); } }
/** * 超时等待 */ public static void test4(){ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue(3); try { System.out.println(blockingQueue.offer("a", 2, TimeUnit.SECONDS)); System.out.println(blockingQueue.offer("a", 2, TimeUnit.SECONDS)); System.out.println(blockingQueue.offer("a", 2, TimeUnit.SECONDS)); System.out.println(blockingQueue.offer("a", 2, TimeUnit.SECONDS)); System.out.println("===================="); System.out.println(blockingQueue.poll(2, TimeUnit.SECONDS)); System.out.println(blockingQueue.poll(2, TimeUnit.SECONDS)); System.out.println(blockingQueue.poll(2, TimeUnit.SECONDS)); } catch (InterruptedException e) { e.printStackTrace(); } }
point12:SynchronousQueue同步队列
同步队列和阻塞队列不同,同步队列不存储元素; 往里面put一个元素,必须要先take取出来;
point13:线程池(重点)
1、为什么要用线程池?线程池的好处?
>a、降低资源的消耗,不用频繁的创先销毁线程; >b、提高响应速度 >c、方便管理
2、三大方法、七大参数、四种拒绝策略
A、三大方法
//不要使用Executors工具类来创建线程池,用最原生的ThreadPoolExecutor; ExecutorService threadPool= Executors.newSingleThreadExecutor();//单个线程 ExecutorService threadPool1=Executors.newFixedThreadPool(5);//固定线程 ExecutorService threadPool2= Executors.newCachedThreadPool();//可变线程,遇强则强,遇弱则弱; try{ for(int i=0;i<10;i++){ //使用线程池创建线程 threadPool.execute(()->{ System.out.println(Thread.currentThread().getName()+"OK"); }) } }finally{ threadPool.shoutdown();//线程池用完,程序关闭,最后关闭线程池 }
B、七大参数
ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,//核心线程数 int maximumPoolSize,//允许最大线程数 long keepAliveTime,//当线程数大于核心线程数时,这就是多余空闲线程的存活时间 TimeUnit unit,//时间单位 BlockingQueue<Runnable> workQueue,//在执行任务之前用于保留任务的队列。 此队列将仅保存execute方法提交的Runnable任务 ThreadFactory threadFactory,//执行过程中创建新的线程所需要的工厂 RejectedExecutionHandler handler//拒绝策略,当线程满了、阻塞队列也满了时会执行的策略 )
C、4种拒绝策略RejectedExecutionHandler:
new ThreadPoolExecutor.AbortPolicy();//银行满了,还有人进来,不处理,抛异常; new ThreadPoolExecutor.CallerRunsPolicy();//哪里来的回哪里 new ThreadPoolExecutor.DiscardOldestPolicy();//队列满了尝试和最早的竞争,不会抛出异常; new ThreadPoolExecutor.DiscardPolicy();//队列满了丢掉任务,不会抛异常;
3、最大线程怎么定义(调优)
A、CPU密集型 获取当前CPU的核数:Runtime.getRuntime().availableProcessors() 最大线程==当前CPU核数
B、IO密集型 判断程序中十分耗IO的线程 最大线程 > 十分耗IO的线程数
point14:四大函数式接口(简化编程模型
函数型接口
Function function = (str)->{ return str;};//有参数、有返回值
断定型接口
Predicate<String> predicate =(str)->{return str.isEmpty();};//有参数,返回布尔值
消费性接口
Consumer<String> consumer =(str)->{ System.out.println("已消费"); };//有参数,无返回值
供给型接口
Supplier supplier=()->{return "你好";};//无参数,有返回值
ponit15:Stream流
/* 筛选条件 * 1、id为偶数 * 2、年龄大于22 * 3、名字转为大写 * 4、倒序 * 5、输出一个 */ User u1 =new User(1,"a",20); User u2 =new User(2,"b",21); User u3 =new User(3,"c",22); User u4 =new User(4,"d",23); User u5 =new User(5,"e",24); User u6 =new User(6,"f",25); List<User> list = Arrays.asList(u1, u2, u3, u4,u5,u6); list.stream().filter(u->{return u.getId()%2==0;}) .filter(u->{return u.getAge()>22;}) .map(u->{return u.getName().toUpperCase();}) .sorted((uu1,uu2)->{return uu2.compareTo(uu1);}) .limit(1) .forEach(System.out::println);
point16:ForkJoin
把一个大任务拆成多个小任务并行执行 例如:计算1-10亿内的数累加 使用ForkJoin可以提升速度,使用Stream流会更快
point17:异步回调