一、行多层索引
1.隐式创建
在构造函数中给index、colunms等多个数组实现(datafarme与series都可以)

df的多级索引创建方法类似:

2.显式创建pd.MultiIndex
其中.from_arrays为类似上面的参数,推荐使用简单的from_product函数(会自动进行交叉):

二、列多层索引
列多层索引同理:

三、多层索引操作与切片
1.Series多层索引
使用中括号和loc效果完全一样:

切片,只切第一级索引,与之前一致,需要指定某些指定行时,可以通过iloc切片,最后一级索引来切片:

2.dataframe的索引与切片
直接切与series类似,只切最外层索引:(包含中文时,可能会有bug!属于Pandas的bug)

使用Loc函数查找:

更多多级索引的操作,参考:https://www.jianshu.com/p/760cd4f46c8d
四、索引的stack堆——重排
堆,字面意思就是摞起来的意思,调用stack就会将数据摞起来:

在pandas里面,这个叫重排,参考:https://blog.csdn.net/S_o_l_o_n/article/details/80917211
五、聚合操作
1.sum()
可以通过axis来控制行还是列,通过之前对轴的介绍,知道axis = 0的默认值是逐行:
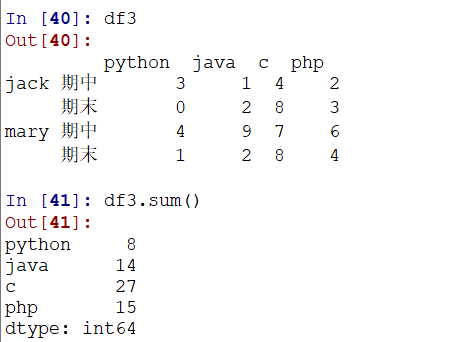
2.其他的聚合:max,min等同理:
