

1/mr的combiner 2/mr的排序 3/mr的shuffle 4/mr与yarn 5/mr运行模式 6/mr实现join 7/mr全局图 8/mr的压缩
一、流量汇总排序的实现
1.需求
对日志数据中的上下行流量信息汇总,并输出按照总流量倒序排序的结果
2.分析
基本思路:实现自定义的bean来封装流量信息,并将bean作为map输出的key来传输
MR程序在处理数据的过程中会对数据排序(map输出的kv对传输到reduce之前,会排序),排序的依据是map输出的key
所以,我们如果要实现自己需要的排序规则,则可以考虑将排序因素放到key中,让key实现接口:WritableComparable然后重写key的compareTo方法
当然,这里还需要考虑的问题是如果分区导致了结果多个reducer,则单个reducer是有序的,但全局不一定有序!
3.代码
package com.mr.flowsort; import com.mr.flowsum.FlowBean; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * mapper * 这个排序针对的是上次流量汇总的结果,所以输入就是上次流量汇总输出的文件 * 输出就是Bean作为输入,手机号作为输出 * * @author zcc ON 2018/2/2 **/ public class FlowSortMapper extends Mapper<LongWritable, Text, FlowBean, Text> { private FlowBean flowBean = new FlowBean(); private Text phone = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 各手机号的总流量信息 String line = value.toString(); String[] fields = line.split(" "); String phoneNum = fields[0]; String bean = fields[1]; // 封装设置属性方法,下面封装的方法之所以如此费劲,是由于Bean的toString()方法所致 flowBean.setFields(getUpFlow(bean), getDownFlow(bean)); phone.set(phoneNum); // 写出去(已序列化),同样Text也不能在这里new,否则new的次数过多,浪费内存 context.write(flowBean, phone); } private long getUpFlow(String bean) { int start = StringUtils.ordinalIndexOf(bean, "=", 1); int end = StringUtils.ordinalIndexOf(bean, ",", 1); String upFlow = bean.substring(start + 1, end); return Long.parseLong(upFlow); } private long getDownFlow(String bean) { int start = StringUtils.ordinalIndexOf(bean, "=", 2); int end = StringUtils.ordinalIndexOf(bean, ",", 2); String downFlow = bean.substring(start + 1, end); return Long.parseLong(downFlow); } // 以上方法可合并 private long getFlow(String bean, int ordinal) { int start = StringUtils.ordinalIndexOf(bean, "=", ordinal); int end = StringUtils.ordinalIndexOf(bean, ",", ordinal); String flow = bean.substring(start + 1, end); return Long.parseLong(flow); } }
package com.mr.flowsort; import com.mr.flowsum.FlowBean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * reducer * * @author zcc ON 2018/2/2 **/ public class FlowSortReducer extends Reducer<FlowBean,Text,Text,FlowBean>{ /** * 进来的数据是<bean,phoneNum>,而且bean是不会相同的,所以迭代器此时只有一个元素 * @param key * @param values * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 直接写出即可,注意此时values只有一个 context.write(values.iterator().next(), key); } }
package com.mr.flowsum; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 这里选择实现WritableComparable接口即可,因为此接口继承了Writable接口(继承树关系) * @author zcc ON 2018/1/31 **/ public class FlowBean implements WritableComparable<FlowBean>{ private long upFlow; private long downFlow; private long sumFlow; /** * 反序列化时需要显式调用空参 */ public FlowBean() { } public FlowBean(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public void setFields(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /** * 序列化 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } /** * 反序列化,注意序列化与反序列化的顺序必须一致! * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } @Override public String toString() { return "FlowBean{" + "upFlow=" + upFlow + ", downFlow=" + downFlow + ", sumFlow=" + sumFlow + '}'; } @Override public int compareTo(FlowBean o) { return Long.compare(this.getSumFlow(), o.getSumFlow()); } }
package com.mr.flowsort; import com.mr.flowsum.*; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 配置Driver * * @author zcc ON 2018/2/2 **/ public class FlowSortDriver { public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置本程序jar包本地位置 job.setJarByClass(FlowSortDriver.class); // 指定本业务job要使用的mapper/reducer业务类 job.setMapperClass(FlowSortMapper.class); job.setReducerClass(FlowSortReducer.class); // 指定map输出的数据类型(由于可插拔的序列化机制导致) job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); // 设置自定义分区器,这里不分区 // job.setPartitionerClass(ProvincePartitioner.class); // 设置相应分区数量的reduceTask // job.setNumReduceTasks(5); // 指定最终输出(reduce)的的数据类型(可选,因为有时候不需要reduce) job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 指定job的原始输入/输出目录(可以改为由外面输入,而不必写死) FileInputFormat.setInputPaths(job, new Path("/flowcount/output")); FileOutputFormat.setOutputPath(job, new Path("/flowsort/output")); // 提交(将job中的相关参数以及java类所在的jar包提交给yarn运行) // job.submit(); // 反馈集群信息 boolean b = job.waitForCompletion(true); System.exit(b ? 0 :1); } }
这里注意一下输入输出路径即可,这里再次提醒运行的方式:
hadoop jar zk03.jar com.mr.flowsort.FlowSortDriver
二、MR内部shuffer过程
这里对上面一整个排序的过程、数据的流向进行剖析:
(注意mr不仅仅是处理文本文件,只要更改默认的inputFormat即可,像之前的一次读一行就是由TextInputFormat决定的。所以是支持自定义的!常见的操作多行的文本的InputFormat也是有例如NLineInputFormat等定义的!)
1.概述
v mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;
通俗的讲, Shuffle描述着数据从map task输出到reduce task输入的这段过程
v shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
v 具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
2.流程详解
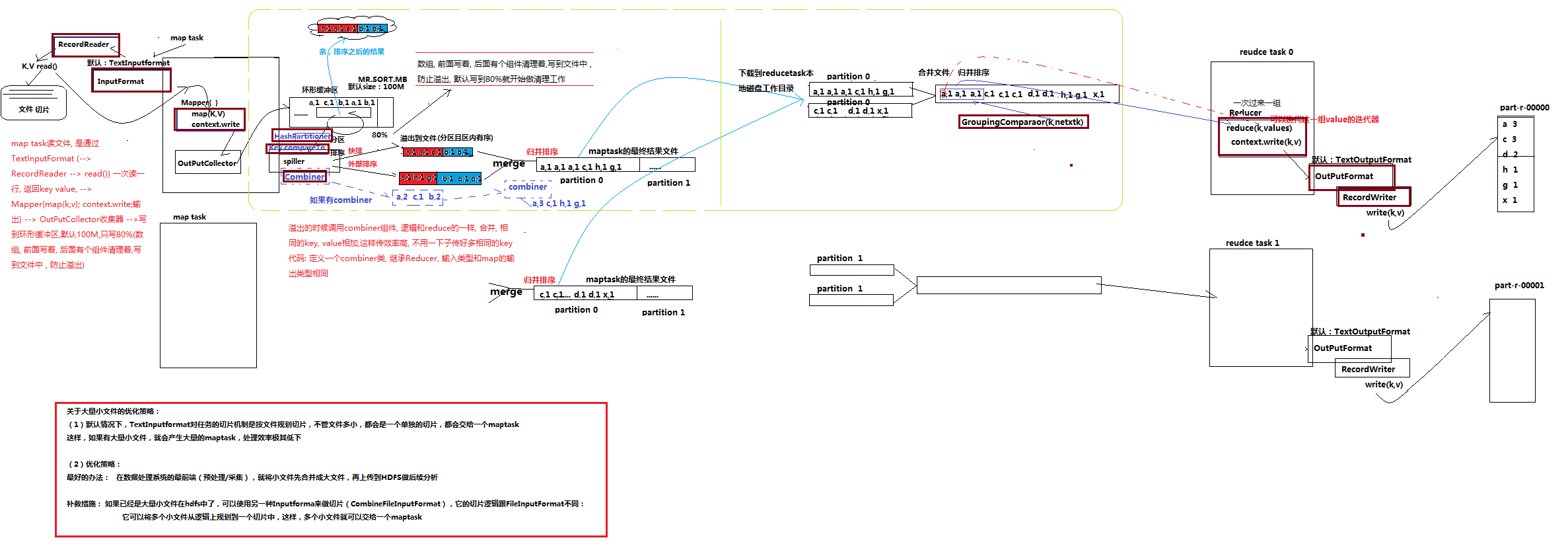
流程详解:
1、maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
2、从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3、多个溢出文件会被合并成大的溢出文件
4、在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5、reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6、reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
7、合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
推荐阅读shuffer详解的博文;http://langyu.iteye.com/blog/992916
http://blog.csdn.net/techchan/article/details/53405519
三、MR中的Combiner
(1)combiner是MR程序中Mapper和Reducer之外的一种组件
(2)combiner组件的父类就是Reducer
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果;
(4) combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
具体实现步骤:
1、 自定义一个combiner继承Reducer,重写reduce方法
2、 在job中设置: job.setCombinerClass(CustomCombiner.class)
package com.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * combiner * * @author zcc ON 2018/2/2 **/ public class WordcountCombiner extends Reducer<Text,IntWritable,Text,IntWritable>{ private IntWritable count = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int c = 0; for (IntWritable value : values) { c += value.get(); } count.set(c); context.write(key, count); } }
package com.mr.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * wordcount的任务配置类 * 相当于yarn集群的客户端,在此封装MR配置参数 * @author zcc ON 2018/1/31 **/ public class WordCountDriver { public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置本程序jar包本地位置 job.setJarByClass(WordCountDriver.class); // 指定本业务job要使用的mapper/reducer业务类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 指定map输出的数据类型(由于可插拔的序列化机制导致) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 指定最终输出(reduce)的的数据类型(可选,因为有时候不需要reduce) job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 指定Combiner job.setCombinerClass(WordcountCombiner.class); // 指定job的原始输入/输出目录(可以改为由外面输入,而不必写死) FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); // 提交(将job中的相关参数以及java类所在的jar包提交给yarn运行) // job.submit(); // 反馈集群信息 boolean b = job.waitForCompletion(true); System.exit(b ? 0 :1); } }
(5) combiner能够应用的前提是不能影响最终的业务逻辑
而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来
注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。
整个流程以及combiner的所处位置,参考详解:https://www.cnblogs.com/ljy2013/articles/4435657.html
四、mapreduce与yarn集群分析
1.yarn概述
Yarn是一个分布式的资源管理系统,用以提高分布式的集群环境下的资源利用率,
这些资源包括内存、IO、网络、磁盘等。其产生的原因是为了解决原MapReduce框架的不足。
最初MapReduce的committer们还可以周期性的在已有的代码上进行修改,可是随着代码的增加以及原MapReduce框架设计的不足,在原MapReduce框架上进行修改变得越来越困难,
所以MapReduce的committer们决定从架构上重新设计MapReduce,使下一代的MapReduce(MRv2/Yarn)框架具有更好的扩展性、可用性、可靠性、向后兼容性和更高的资源利用率
以及能支持除了MapReduce计算框架外的更多的计算框架。
2.yarn重要概念
1、 yarn并不清楚用户提交的程序的运行机制
2、 yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3、 yarn中的主管角色叫ResourceManager
4、 yarn中具体提供运算资源的角色叫NodeManager
5、 这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如 mapreduce、storm程序,spark程序,tez ……
6、 所以,spark、storm等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可
7、 Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
3.调度过程图

新旧Haoop的mapreduce对比:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/