一、什么是数据模型
数据模型是抽象描述现实世界的一种工具和方法,是通过抽象的实体及实体之间联系的形式,来表示现实世界中事务的相互关系的一种映射。在这里,数据模型表现的抽象的是实体和实体之间的关系,通过对实体和实体之间关系的定义和描述,来表达实际的业务中具体的业务关系。
数据仓库模型是数据模型中针对特定的数据仓库应用系统的一种特定的数据模型,一般的来说,我们数据仓库模型分为几下几个层次,如图 2 所示。
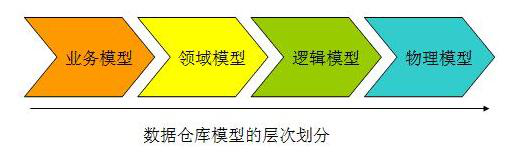
业务建模,生成业务模型,主要解决业务层面的分解和程序化。
领域建模,生成领域模型,主要是对业务模型进行抽象处理,生成领域概念模型。
逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
物理建模,生成物理模型,主要解决,逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题。
因此,在整个数据仓库的模型的设计和架构中,既涉及到业务知识,也涉及到了具体的技术,我们既需要了解丰富的行业经验,同时,也需要一定的信息技术来帮助我们实现我们的数据模型,最重要的是,我们还需要一个非常适用的方法论,来指导我们自己针对我们的业务进行抽象,处理,生成各个阶段的模型。
二、为什么需要数据仓库模型
- 进行全面的业务梳理,改进业务流程。
- 在业务模型建设的阶段,能够帮助我们的企业或者是管理机关对本单位的业务进行全面的梳理。通过业务模型的建设,我们应该能够全面了解该单位的业务架构图和整个业务的运行情况,能够将业务按照特定的规律进行分门别类和程序化,同时,帮助我们进一步的改进业务的流程,提高业务效率,指导我们的业务部门的生产。
- 建立全方位的数据视角,消灭信息孤岛和数据差异。
- 通过数据仓库的模型建设,能够为企业提供一个整体的数据视角,不再是各个部门只是关注自己的数据,而且通过模型的建设,勾勒出了部门之间内在的联系,帮助消灭各个部门之间的信息孤岛的问题,更为重要的是,通过数据模型的建设,能够保证整个企业的数据的一致性,各个部门之间数据的差异将会得到有效解决。
- 解决业务的变动和数据仓库的灵活性。
- 通过数据模型的建设,能够很好的分离出底层技术的实现和上层业务的展现。当上层业务发生变化时,通过数据模型,底层的技术实现可以非常轻松的完成业务的变动,从而达到整个数据仓库系统的灵活性。
- 帮助数据仓库系统本身的建设。
- 通过数据仓库的模型建设,开发人员和业务人员能够很容易的达成系统建设范围的界定,以及长期目标的规划,从而能够使整个项目组明确当前的任务,加快整个系统建设的速度。
三、如何建设数据仓库模型
1.数据仓库数据模型架构

- 系统记录域(System of Record):这部分是主要的数据仓库业务数据存储区,数据模型在这里保证了数据的一致性。
- 内部管理域(Housekeeping):这部分主要存储数据仓库用于内部管理的元数据,数据模型在这里能够帮助进行统一的元数据的管理。
- 汇总域(Summary of Area):这部分数据来自于系统记录域的汇总,数据模型在这里保证了分析域的主题分析的性能,满足了部分的报表查询。
- 分析域(Analysis Area):这部分数据模型主要用于各个业务部分的具体的主题业务分析。这部分数据模型可以单独存储在相应的数据集市中。
- 反馈域(Feedback Area):可选项,这部分数据模型主要用于相应前端的反馈数据,数据仓库可以视业务的需要设置这一区域。
2.数据仓库建模阶段规划
1. 业务建模,这部分建模工作,主要包含以下几个部分:
- 划分整个单位的业务,一般按照业务部门的划分,进行各个部分之间业务工作的界定,理清各业务部门之间的关系。
- 深入了解各个业务部门的内具体业务流程并将其程序化。
- 提出修改和改进业务部门工作流程的方法并程序化。
- 数据建模的范围界定,整个数据仓库项目的目标和阶段划分。
2. 领域概念建模,这部分得建模工作,主要包含以下几个部分:
- 抽取关键业务概念,并将之抽象化。
- 将业务概念分组,按照业务主线聚合类似的分组概念。
- 细化分组概念,理清分组概念内的业务流程并抽象化。
- 理清分组概念之间的关联,形成完整的领域概念模型。
3. 逻辑建模,这部分的建模工作,主要包含以下几个部分:
- 业务概念实体化,并考虑其具体的属性
- 事件实体化,并考虑其属性内容
- 说明实体化,并考虑其属性内容
4. 物理建模,这部分得建模工作,主要包含以下几个部分:
- 针对特定物理化平台,做出相应的技术调整
- 针对模型的性能考虑,对特定平台作出相应的调整
- 针对管理的需要,结合特定的平台,做出相应的调整
- 生成最后的执行脚本,并完善之。
3.常用建模方法
主要有范式建模、纬度建模、实体建模
这里适当展开纬度建模,其他参考https://www.cnblogs.com/benchen/p/6009532.html等
纬度建模:
维度建模法,Kimball 最先提出这一概念。其最简单的描述就是,按照事实表,维表来构建数据仓库,数据集市。这种方法的最被人广泛知晓的名字就是星型模式(Star-schema)。
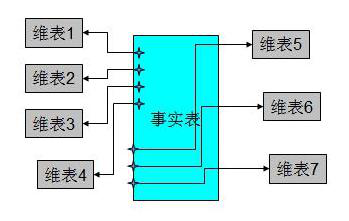
上图的这个架构中是典型的星型架构。星型模式之所以广泛被使用,在于针对各个维作了大量的预处理,如按照维进行预先的统计、分类、排序等。通过这些预处理,能够极大的提升数据仓库的处理能力。特别是针对 3NF 的建模方法,星型模式在性能上占据明显的优势。
同时,维度建模法的另外一个优点是,维度建模非常直观,紧紧围绕着业务模型,可以直观的反映出业务模型中的业务问题。不需要经过特别的抽象处理,即可以完成维度建模。这一点也是维度建模的优势。
但是,维度建模法的缺点也是非常明显的,由于在构建星型模式之前需要进行大量的数据预处理,因此会导致大量的数据处理工作。而且,当业务发生变化,需要重新进行维度的定义时,往往需要重新进行维度数据的预处理。而在这些与处理过程中,往往会导致大量的数据冗余。
另外一个维度建模法的缺点就是,如果只是依靠单纯的维度建模,不能保证数据来源的一致性和准确性,而且在数据仓库的底层,不是特别适用于维度建模的方法。
因此以笔者的观点看,维度建模的领域主要适用与数据集市层,它的最大的作用其实是为了解决数据仓库建模中的性能问题。维度建模很难能够提供一个完整地描述真实业务实体之间的复杂关系的抽象方法。
这里补充纬度表和事实表的定义:
一个典型的例子是,把逻辑业务比作一个立方体,产品维、时间维、地点维分别作为不同的坐标轴,而坐标轴的交点就是一个具体的事实。也就是说事实表是多个维度表的一个交点。而维度表是分析事实的一个窗口。
事实表是数据仓库结构中的中央表——用户关心的业务数据,它包含联系事实与维度表的数字度量值和键。事实数据表包含描述业务(例如产品销售)内特定事件的数据。
维度表是维度属性的集合——描述业务数据的数据。是分析问题的一个窗口。是人们观察数据的特定角度,是考虑问题时的一类属性,属性的集合构成一个维。