什么是算法?
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。
算法中的指令描述的是一个计算,当其运行时能从一个初始状态和(可能为空的)初始输入开始,经过一系列有限而清晰定义的状态,最终产生输出并停止于一个终态。一个状态到另一个状态的转移不一定是确定的。随机化算法在内的一些算法,包含了一些随机输入。简单来说,算法就是一个计算过程,解决问题的方法。
算法的特征
一个算法应该具有五个重要的特征:
- 有穷性(Finiteness):算法的有穷性是指算法必须在执行有限的步骤之后终止。
- 确切性(Definiteness):算法的每一个步骤必须有确切的定义。
- 输入项(Input):一个算法有0个或多个输入,以刻画运算对象的初始情况,0个输入是指算法本身定出了初始条件。
- 输出项目(Output):一个算法有1个或多个输出,以反映对输入数据加工后的结果,没有输出的算法是毫无意义的。
- 可行性(Effectiveness):算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作,每个计算步都可以在有限时间内完成(也称之为有效性)。
算法的评定
同一问题可以用不同的算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在于选择合适算法和改进算法。其一个算法的评价只要从(时间复杂度)和(空间复杂度)来考虑。
- 时间复杂度:算法的时间复杂度是指执行算法所需要的计算工作量。可以用O(n)来当单位衡量。
- 空间复杂度:算法的空间复杂度是指算法需要消耗的内存空间。一般用空间换时间。
- 正确性:算法的正确性是评价一个算法优劣的最重要标准、
- 可读性:算法的可读性是指一个算法可供人们阅读的容易程度。
- 健壮性:健壮性是指一个算法对不合理数据输入的反应能力和处理能力,也称为容错性。
Python中的算法排序


一般来说,时间复杂度高的算法比复杂度低的算法慢。 常见的时间复杂度(按效率排序) O(1)<O(logn)<O(n)<O(nlogn)<O(n**2)<O(n**2logn)<O(n**3) 不常见的空间复杂度 O(n!)n的阶乘 O(2**n)2的n次方 O(n**n)n的n次方 小技巧: 如果是循环减半的过程 -> O(logn) 几次循环就是n的几次方的复杂度 print("Hello World!") # 时间复杂度为O(1) for i in range(n): # 时间复杂度为O(n) print("Hello World!") for i in range(n): # 时间复杂度为O(n**2)n的二次方 for j in range(n): print("Hello World!") for i in range(n): # 时间复杂度为O(n**3)n的三次方 for j in range(n): for k in range(n): print("Hello World!") while n > 1: # 时间复杂度为O(logn)求n的幂的逆运算 print(n) n = n // 2
几种常见的算法
- 冒泡排序:相邻的两个数,如果前边比后边的大,那么久交换这两个数。
# 冒泡排序法的时间复杂度O(n**2) li = [1,9,2,8,3,6,4,5,7] # 一个列表需要排序 # 方式一: def bubble_sort(li): for i in range(0, len(li)-1): # 循环一下其索引(0,8)因为顾头不顾尾索引-1 for j in range(0, len(li) - i - 1): # 再次循环相邻换完最小值要去掉他最小值 if li[j] > li[j+1]: # 如果循环完的数大于相邻的数 li[j], li[j+1] = li[j+1], li[j] # 那么就交换这两个数 print(bubble_sort(li)) # 最后结果[1,2,3,4,5,6,7,8,9] # 方式二(优化方式一,代表冒泡排序法执行一趟之后没有交换,则代表列表是有序状态,可以直接结束算法。): def bubble_sort_2(li): for i in range(0, len(li)-1): for j in range(0, len(li) - i - 1): exchange = False if li[j] > li[j+1]: li[j], li[j+1] = li[j+1], li[j] exchange = True if not exchange: return print(bubble_sort_2(li)) # 如果有序的话,执行速度会加快
- 选择排序法:一趟遍历记录最小的数,放到第一个位置,接着在一趟遍历记录中剩余列表最小的数,继续放置,直至结束。
# 选择排序法的时间复杂度O(n**2) def select_sort(li): for i in range(len(li) - 1): # 第i趟:有序区li[0:i] 无序区li[i:n] min_loc = i for j in range(i + 1, len(li)): if li[min_loc] > li[j]: min_loc = j li[min_loc], li[i] = li[i], li[min_loc]
- 插入排序法:列表分为有序区和无序区两个部分,初始有序区只有一个元素。每次从无序区取出一个元素,插入到有序区的位置,直到无序区为空。
def insert_sort(li): for i in range(1, len(li)): # i既表示趟数,也表示数的下标 j = i - 1 tmp = li[i] while j >= 0 and li[j] > tmp: li[j + 1] = li[j] j -= 1 li[j + 1] = tmp
- 快速排序法:取一个元素,才用填坑法,让一个列表被这个元素分成两部分,左边都比这个元素小,反之右边比这个元素大,在用递归完成排序。
li = [5, 7, 4, 6, 3, 1, 2, 9, 8] def quick_sort(li, low, high): # 参数是(取第一个参数, 0, 列表中的元素个数) i = low j = high if i >= j: return li key = li[i] while i < j: while i < j and li[j] >= key: # 如果要是进行降序排序吧li[j] >= key 变成 <= j = j - 1 li[i] = li[j] while i < j and li[i] <= key: # 如果要是进行降序排序吧li[i] <= key 变成 >= i = i + 1 li[j] = li[i] li[i] = key quick_sort(li, low, i - 1) quick_sort(li, j + 1, high) return li print(quick_sort(li, 0, 8))
- 堆排序法:直到堆的概念需要先知道数与二叉树
树是一种数据结构,并且是可以递归定义的数据结构。
树是由n个节点组成的集合:如果n = 0,那么这就是一颗空树,如果n > 0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合又是一个树。
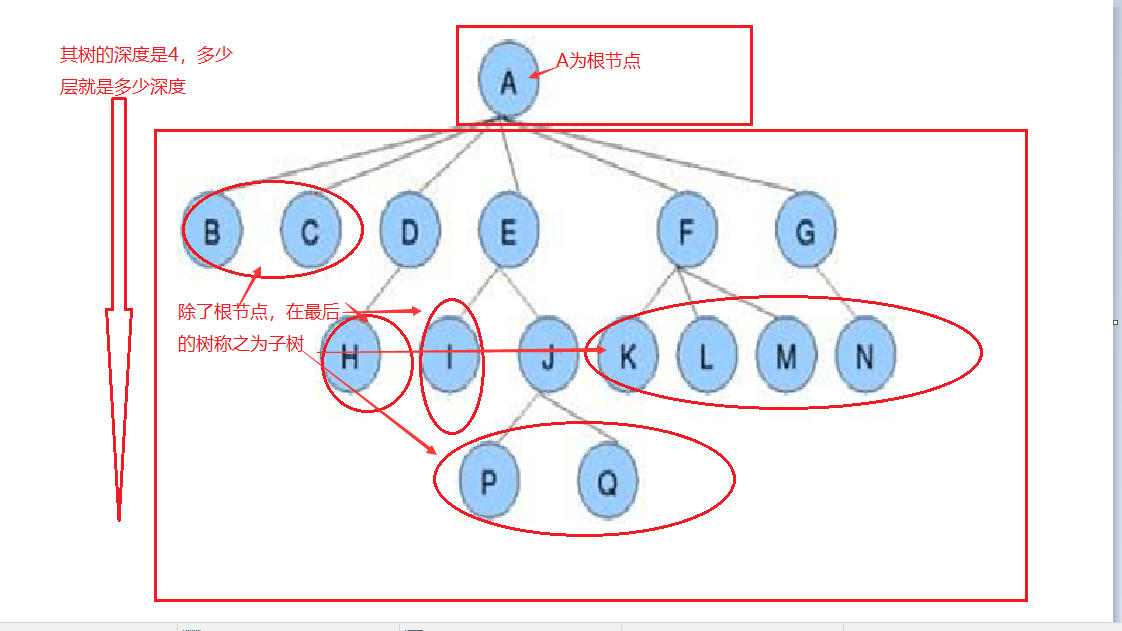
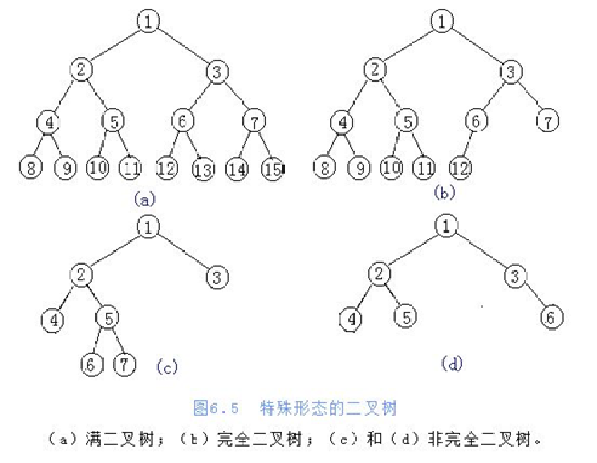
上面是树的概念,下面是特殊且常用的树 —— 二叉树(度不超过2的树(节点最多有两个叉))
两种特殊二叉树:
满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
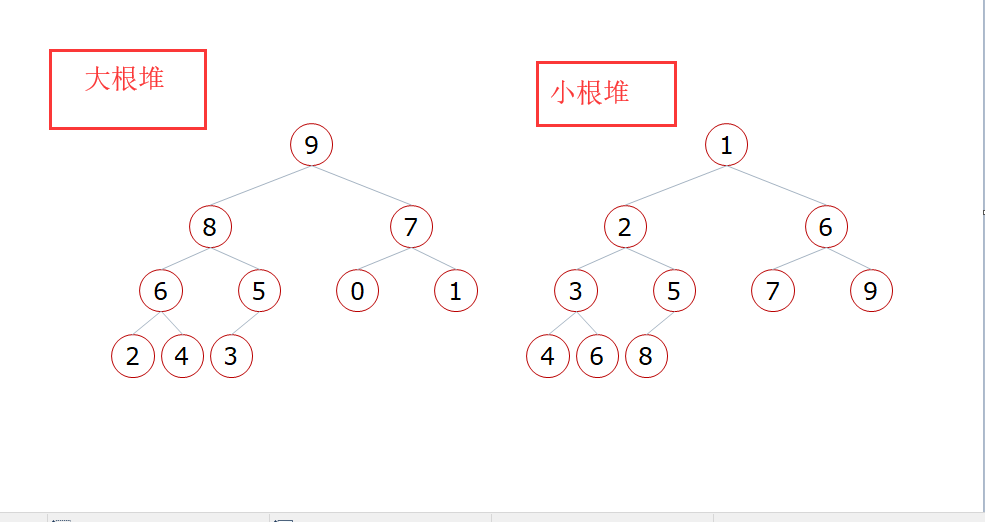
堆排序:
大跟堆:一颗完全二叉树,满足任一节点都比其孩子节点大。
小跟堆:一颗完全二叉树,满足任一节点都比其孩子节点小。
堆排序的过程:如果节点的左右子树都是堆,但自身不是堆,那么就可以通过向下调整来创造堆。
建立堆,并且保证堆顶元素是最大元素。去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序,直至堆边空。
在Python中有个内置模块——heapq,其中可以用这个模块来实现堆排序
from cal_time import cal_time import heapq def sift(li, low, high): tmp = li[low] # 最大元素 i = low j = 2 * i + 1 while j <= high: # 第二种跳出条件: j > high if j < high and li[j+1] > li[j]: # 如果右孩子存在并且大于左孩子 j += 1 if tmp < li[j]: li[i] = li[j] i = j j = 2 * i + 1 else: # 第一种跳出条件:li[j] <= tmp break li[i] = tmp @cal_time def heap_sort(li): n = len(li) # 1. 建堆 for i in range(n // 2 - 1, -1, -1): # 最后一个非叶子节点的位置是n//2-1 sift(li, i, n-1) # 2. 挨个出数 for i in range(n-1, -1, -1): # i 表示此时堆的high位置 li[0], li[i] = li[i], li[0] # 已经排序好的元素 sift(li, 0, i-1) import random li = list(range(100000)) random.shuffle(li) heap_sort(li) print(li)
- 归并排序法:将列表越分越小,直到分成一个元素,接下来合并,合并之后是有序列表,越来越大。
def merge(li, low, mid, high): # 一次归并方法 i = low j = mid + 1 li_tmp = [] while i <= mid and j <= high: if li[i] < li[j]: li_tmp.append(li[i]) i += 1 else: li_tmp.append(li[j]) j += 1 while i <= mid: li_tmp.append(li[i]) i += 1 while j <= high: li_tmp.append(li[j]) j += 1 for i in range(low, high+1): li[i] = li_tmp[i-low] def merge_sort(li, low, high): # 归并排序 if low < high: # 至少两个元素 mid = (low + high) // 2 print(li[low:mid + 1], li[mid + 1:high + 1]) merge_sort(li, low, mid) merge_sort(li, mid+1, high) print(li[low:mid+1], li[mid+1:high+1]) merge(li, low, mid, high) print(li[low:high + 1]) li = [10,4,6,3,8,2,5,7] merge_sort(li, 0, len(li)-1)
|
排序方法 |
空间复杂度 |
稳定性 |
|||
|
最坏情况 |
平均情况 |
最好情况 |
|||
|
冒泡排序 |
O(n2) |
O(n2) |
O(n) |
O(1) |
稳定 |
|
直接选择排序 |
O(n2) |
O(n2) |
O(n2) |
O(1) |
不稳定 |
|
直接插入排序 |
O(n2) |
O(n2) |
O(n) |
O(1) |
稳定 |
|
快速排序 |
O(n2) |
O(nlogn) |
O(nlogn) |
平均情况O(logn); 最坏情况O(n) |
不稳定 |
|
堆排序 |
O(nlogn) |
O(nlogn) |
O(nlogn) |
O(1) |
不稳定 |
|
归并排序 |
O(nlogn) |
O(nlogn) |
O(nlogn) |
O(n) |
稳定 |