LSTM隐层状态h0, c0通常初始化为0,大部分情况下模型也能工作的很好。但是有时将h0, c0作为随机值,或直接作为模型参数的一部分进行优化似乎更为合理。
这篇post给出了经验证明:
Non-Zero Initial States for Recurrent Neural Networks
给出的经验结果:

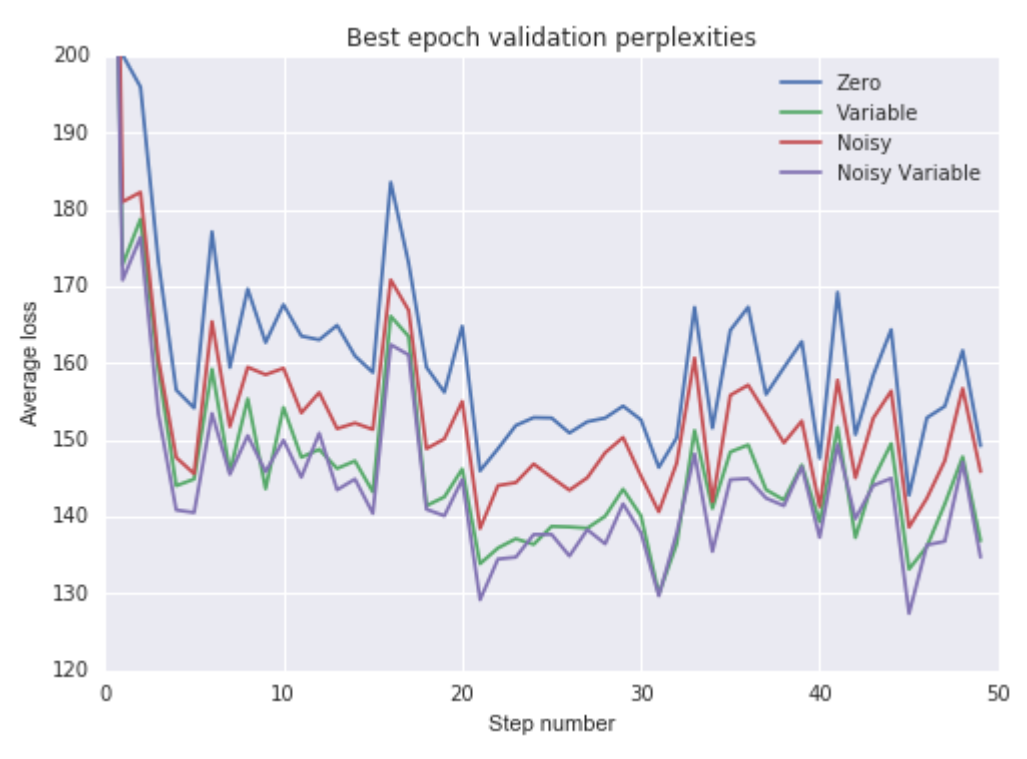

给出的结论是:(1)非零的初始状态初始化能够加速训练并改善模型泛化性能,(2)将初始状态作为模型参数去训练要比具有零均值的噪声初始化更有效, (3)如果选择学习隐层初始状态,添加噪声并不能带来额外的收益。
基本上,如果你的数据包括许多短序列,那么训练初始状态可以加速学习。相反,如果数据仅包含少量的长序列,那么可能没有足够的数据来有效地训练初始状态;在这种情况下,使用一个有噪声的初始状态可以加速学习。他们没有提到的一个想法是如何恰当地确定随机噪声发生器的均值和std。此外,这篇文章Forecasting with Recurrent Neural Networks: 12 Tricks 中的Trick 4提出了一种基于反向传播误差的自适应方法,使初始状态噪声的大小根据反向传播的误差自适应变化。

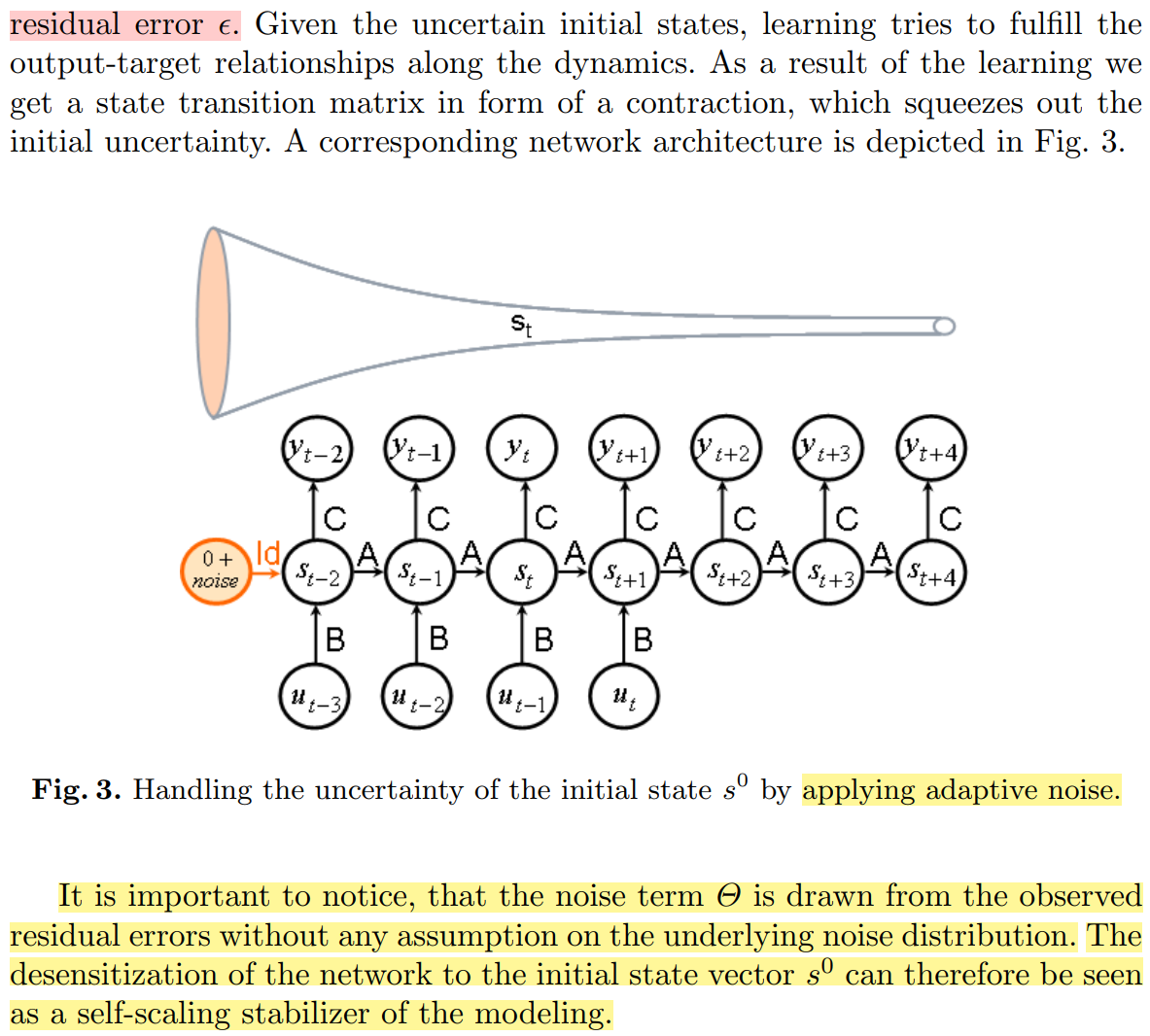

实际效果有待进一步验证。
事实上,LSTM的隐藏层初始状态h0, c0可以看做是模型的一部分参数,并在迭代中更新。这里给出pytorch中LSTM更新隐藏层初始状态h0, c0的一种实现方法(来自知乎)。
1 作者:郑华滨 2 链接:https://www.zhihu.com/question/270772480/answer/358198157 3 来源:知乎 4 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 5 6 import torch 7 import torch.nn as nn 8 from torch.autograd import Variable 9 10 class EasyLSTM(nn.LSTM): 11 12 def __init__(self, *args, **kwargs): 13 nn.LSTM.__init__(self, *args, **kwargs) 14 self.num_direction = 1 + self.bidirectional 15 state_size = (self.num_layers * self.num_direction, 1, self.hidden_size) 16 self.init_h = nn.Parameter(torch.zeros(state_size)) 17 self.init_c = nn.Parameter(torch.zeros(state_size)) 18 19 def forward(self, rnn_input, prev_states = None): 20 batch_size = rnn_input.size(1) 21 if prev_states is None: 22 state_size = (self.num_layers * self.num_direction, batch_size, self.hidden_size) 23 init_h = self.init_h.expand(*state_size).contiguous() 24 init_c = self.init_c.expand(*state_size).contiguous() 25 prev_states = (init_h, init_c) 26 rnn_output, states = nn.LSTM.forward(self, rnn_input, prev_states) 27 return rnn_output, states
LSTM、GRU、LSTMCell、GRUCell ?
1 import torch 2 import torch.nn as nn 3 from torch.autograd import Variable 4 5 class EasyLSTM(nn.LSTM): 6 7 def __init__(self, *args, **kwargs): 8 nn.LSTM.__init__(self, *args, **kwargs) 9 self.num_direction = 1 + self.bidirectional 10 state_size = (self.num_layers * self.num_direction, 1, self.hidden_size) 11 self.init_h = nn.Parameter(torch.zeros(state_size)) 12 self.init_c = nn.Parameter(torch.zeros(state_size)) 13 14 def forward(self, rnn_input, prev_states = None): 15 batch_size = rnn_input.size(1) 16 if prev_states is None: 17 state_size = (self.num_layers * self.num_direction, batch_size, self.hidden_size) 18 init_h = self.init_h.expand(*state_size).contiguous() 19 init_c = self.init_c.expand(*state_size).contiguous() 20 prev_states = (init_h, init_c) 21 rnn_output, states = nn.LSTM.forward(self, rnn_input, prev_states) 22 return rnn_output, states 23 24 class EasyGRU(nn.GRU): 25 26 def __init__(self, *args, **kwargs): 27 nn.GRU.__init__(self, *args, **kwargs) 28 self.num_direction = 1 + self.bidirectional 29 state_size = (self.num_layers * self.num_direction, 1, self.hidden_size) 30 self.init_h = nn.Parameter(torch.zeros(state_size)) 31 32 def forward(self, rnn_input, prev_states = None): 33 batch_size = rnn_input.size(1) 34 if prev_states is None: 35 state_size = (self.num_layers * self.num_direction, batch_size, self.hidden_size) 36 init_h = self.init_h.expand(*state_size).contiguous() 37 prev_states = init_h 38 rnn_output, states = nn.GRU.forward(self, rnn_input, prev_states) 39 return rnn_output, states 40 41 42 class EasyLSTMCell(nn.LSTMCell): 43 44 def __init__(self, *args, **kwargs): 45 nn.LSTMCell.__init__(self, *args, **kwargs) 46 state_size = (1, self.hidden_size) 47 self.init_h = nn.Parameter(torch.zeros(state_size)) 48 self.init_c = nn.Parameter(torch.zeros(state_size)) 49 50 def forward(self, rnn_input, prev_states=None): 51 batch_size = rnn_input.size(0) 52 if prev_states is None: 53 state_size = (batch_size, self.hidden_size) 54 init_h = self.init_h.expand(*state_size).contiguous() 55 init_c = self.init_c.expand(*state_size).contiguous() 56 prev_states = (init_h, init_c) 57 h, c = nn.LSTMCell.forward(self, rnn_input, prev_states) 58 return h, c 59 60 61 class EasyGRUCell(nn.GRUCell): 62 63 def __init__(self, *args, **kwargs): 64 nn.GRUCell.__init__(self, *args, **kwargs) 65 state_size = (1, self.hidden_size) 66 self.init_h = nn.Parameter(torch.zeros(state_size)) 67 68 def forward(self, rnn_input, prev_states=None): 69 batch_size = rnn_input.size(0) 70 if prev_states is None: 71 state_size = (batch_size, self.hidden_size) 72 init_h = self.init_h.expand(*state_size).contiguous() 73 prev_states = init_h 74 h = nn.GRUCell.forward(self, rnn_input, prev_states) 75 return h 76 77 if __name__ == '__main__': 78 79 lstm = EasyLSTM(10, 20, 2) 80 input = torch.randn(5, 3, 10) 81 h0 = torch.randn(2, 3, 20) 82 c0 = torch.randn(2, 3, 20) 83 output, (hn, cn) = lstm(input, (h0, c0)) 84 85 gru = EasyGRU(10, 20, 2) 86 input = torch.randn(5, 3, 10) 87 h0 = torch.randn(2, 3, 20) 88 output, hn = gru(input, h0) 89 90 lstmcell = EasyLSTMCell(10, 20) 91 input = torch.randn(6, 3, 10) 92 h = torch.randn(3, 20) 93 c = torch.randn(3, 20) 94 out = [] 95 for i in range(6): 96 h, c = lstmcell(input[i], (h, c)) 97 out.append(h) 98 99 grucell = EasyGRUCell(10, 20) 100 input = torch.randn(6, 3, 10) 101 h = torch.randn(3, 20) 102 out = [] 103 for i in range(6): 104 h = grucell(input[i], h) 105 out.append(h)
参考:
Non-Zero Initial States for Recurrent Neural Networks
Best way to initialize LSTM state
https://danijar.com/tips-for-training-recurrent-neural-networks/