Flume安装
介绍
Flume本身的安装比较简单(flume的介绍请参考http://blog.csdn.net/rzhzhz/article/details/7448633),安装前先说明几个概念,先看flume的架构
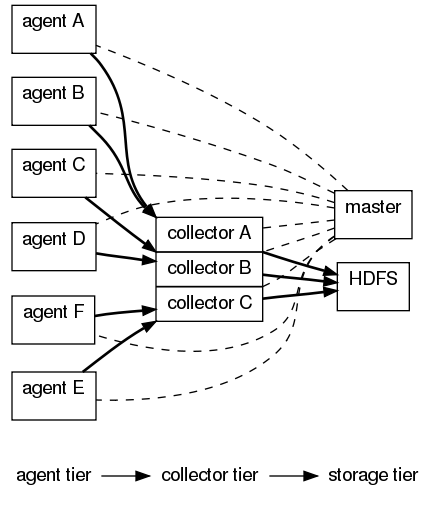
1. Flume分三种角色
Mater: master负责配置及通信管理,是集群的控制器。
Collector: collector用于对数据进行聚合,往往会产生一个更大的流,然后加载到storage中。
Agent: Agent用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector
2. Collector和Agent的配置数据必须指定Source(可以理解为数据入口)和Sink(可以理解为数据出口)
常用的source如:
text(“filename”):将文件filename作为数据源,按行发送
tail(“filename”):探测filename新产生的数据,按行发送出去
fsyslogTcp(5140):监听TCP的5140端口,并且接收到的数据发送出去
常用的sink如:
console[("format")] :直接将将数据显示在桌面上
text(“txtfile”):将数据写到文件txtfile中
dfs(“dfsfile”):将数据写到HDFS上的dfsfile文件中
syslogTcp(“host”,port):将数据通过TCP传递给host节点
具体介绍可以参考
http://blog.csdn.net/rzhzhz/article/details/7457956
http://blog.csdn.net/rzhzhz/article/details/7449662
安装
1. 下载解压安装
a) Flume的下载地址http://archive.cloudera.com/cdh/3/
b) 这里所说的安装包括jdk,flume本身及zookeeper的安装,这里就不再赘述jdk的安装过程。Zookeeper集群安装请参考http://blog.csdn.net/rzhzhz/article/details/7448894
c) 把下载好的flume包解压到相应位置(flume集群每台机器都需安装),以下以$FLUME_HOME代替安装路径,至于以哪个用户安装按本身实际情况而定。
d) 我们暂且先配置一个master,一个collector,一个agent,主机名对应如下
Mater: master
Collector : collector
Agent : agent
2. 配置相关路径
a) 这里要配置相关路径无非也就是因为flume在启动的时候如果依赖到相关软件(如java,hadoop,zookeeper)时会去其根目录下加载jar包和去conf目录下加载配置文件
b) 我习惯在/etc/profile下配置export,当然你也可以去$FLUME_HOME/bin目录下flume-env.sh配置(由flume-env.sh.template改名而成)
配置大致如下(内容仅供参考,加载过程大家可参考$FLUME_HOME/bin/flume脚本内容)
|
#Java export JAVA_HOME=/usr/java/jdk1.6.0_25 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
#hadoop export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin
#zookeeper export ZOOKEEPER_HOME=/usr/local/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin
#flume export FLUME_HOME=/usr/local/flume export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin |
3. 修改配置文件
a) $FLUME_HOME/conf目录下本身有flume-conf.xml和flume-site.xml.template两个文件,flume-conf.xml是默认的配置文件,虽说也可以修改,但不建议修改,用户配置应该在flume-site.xml(由flume-site.xml.template改名而成)文件中(即相当于覆盖flume-conf.xml文件中的原有配置)。flume-site.xml文件应该是针对节点在集群中的不同角色而做不同的修改(详细的配置参数可以参考flume-conf.xml,针对不同角色做了分门别类,一目了然),这里就不具体描述了,可参考http://blog.csdn.net/rzhzhz/article/details/7457956。
b) Collector和Agent的用户配置文件中flume-site.xml必须指定master的地址flume.master.servers,如下:
|
<property> <name>flume.master.servers</name> <value>master</value> </property> |
4. 启动zookeeper集群
a) 这里zookeeper集群会在master的配置文件里配置。
|
<property> <name>flume.master.zk.use.external</name> <value>true</value> </property> <property> <name>flume.master.zk.servers</name> <value>master:2181,collector:2181,agent:2181</value> </property> |
flume.master.zk.use.external 是否使用外部zookeeper集群
flume.master.zk.servers zookeeper集群地址
b) 如果不配置则使用flume内部提供的zookeeper。flume使用使用zookeeper进行管理和负载均衡.
c) 关于zookeeper保存的master的配置数据是可以配置(flume.master.store)的,可以选择存在zookeeper中(zookeeper),也可以选择存储在内存中(memory)
5. 启动master,collector,Agent
a) 启动master: flume master
b) 启动node(collector): flume node_nowatch
c) 启动node(agent): flume node_nowatch
后两者的启动方式是一样的,只是在配置参数中有所差异
启动node的时候可以选择指定node的名字的参数 -n ,默认为主机名
如(flume node_nowatch –n node1)
6. 查看
a) Web查看
Master :
http://master:35871/flumemaster.jsp
可以在master页面查看和配置node参数
node :
http://collector:35862/flumeagent.jsp
http://agent:35862/flumeagent.jsp
单机部署的时候,如果启动了多个node,则端口以此增加(如35863,35864)
b) Shell连接(简略介绍下,更详细的命令请参考help)
flume shell
collect master
7. 在master修改节点配置
a) 这里我们其实可以这样先易后难,不要一开始就弄复杂的配置,这样很难定位错误,还有flume本身的错误基本就是在控制台输出,这与我们的调试思路有点违背,我们一般的查错首先都会想到日志文件,但它的日志文件实在是没什么东西
b) 配置界面大致如下

当然你也可以在shell端配置,此处就不多做介绍。
Web界面配置步骤如下
首先选择configure node选择要选择的node,或者指定不存在于list中的节点(or specify another node)
配置source
配置sink
提交
提交之后可以在master的界面查看是否成功,大致如下图

c) Collector配置
SOURCE: collectorSource(35853)
监听35853端口,接受agent发送的消息
SINK: collectorSink("file:///tmp/flume/collected","sink")
将数据加载到文件中
d) Agent配置
从控制台接受输入
SINK: agentE2ESink( "collector",35853 )
指定collector的名字及端口
下面简单介绍一下调试流程
首先我们可以这么配置 先配置最简单的source ,console(控制台输入)
最简单的sink,collectorSink("file:///tmp/flume/collected", "file")
然后看file:///tmp/flume/collected文件目录下是否有控制台输入的内容
调试成功后说明agent与collector是相通的。
再把source换成text或者其他再做调试
最后把sink换成hdfs或者hbase什么的
8. 配置生效(自动),查看结果
略