今天检查满查询日志发现有个存储过程查询可以达17S
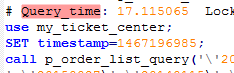
而且是订单列表查询,这个当然不能忍了,必须优化,接下来就是查找原因优化过程。过程使用动态语句,首先使用满查询的语句条件提取出来静态语句单独分析:
提取结果如下:
table1 表数据100W+ table3表数据200W+
SELECT b.*, A.value1, A.value2, A.value3, A.value4, A.value5, A.value6, FROM table1 b LEFT JOIN table2A ON b.order_no = A.order_no AND b.channel_no = A.channel_no WHERE 1 = 1 AND EXISTS (SELECT 1 FROM table3 t WHERE b.order_no = t.order_no AND t.ticket_no LIKE '%1792903240%') ORDER BY CREATE_TIME LIMIT 0, 20
为什么这个过程要10s+ 呢?
主要原因在于 exists这个部分,因为 table3有200W的数据,并且循环式和外表扫描查询,并且这里的like是不会走索引的,只能全扫描,所以慢就很明显了,由于是动态语句,并在存储过程中,所以优化就是拆解EXISTS这部分
主要思路就是 先从200W+ 的table3中查出来order_no 然后把order_no插入临时表,然后再使用in 临时表查询,减少关联扫描次数就能极大的优化查询时间
前提: table3中的ticket_no 重复率非常低,200W+的数据 有200W的非重复,为什么强调这个,临时表在处理少量数据时性能很优异,(一般只在确定不能用索引的时候才使用临时表,或者在存储过程中某些固定数据使用次数非常多的时候使用临时表,其他时候我一般不建议使用)
优化结果:
CREATE TEMPORARY TABLE tmp_order_no (ticket_order_no varchar(100)); INSERT INTO tmp_order_no SELECT tp.order_no FROM t_passenger tp WHERE tp.ticket_no LIKE CONCAT('%',2903240,'%'); SELECT b.*, A.value1, A.value2, A.value3, A.value4, A.value5, A.value6, FROM table1 b LEFT JOIN table2A ON b.order_no = A.order_no AND b.channel_no = A.channel_no WHERE 1 = 1 AND b.order_no IN (SELECT ticket_order_no FROM tmp_order_no) ORDER BY CREATE_TIME LIMIT 0, 20 DROP TEMPORARY TABLE IF EXISTS tmp_order_no;
优化后查询时间1.2S左右,速度提升十几倍,性能提升明显