原文地址:https://www.cnblogs.com/corvoh/p/5595130.html
最近临近期末的C语言课程设计比平时练习作业一下难了不止一个档次,第一次接触到了C语言的框架开发,了解了View(界面层)、Service(业务逻辑层)、Persistence(持久化层)的分离和耦合,一种面向过程的MVC的感觉。
而这一切的基础就在于对链表的创建、删除、输出、写入文件、从文件读出......
本篇文章在于巩固链表的基础知识(整理自《C语言程序设计教程--人民邮电出版社》第十章——指针与链表),只对链表的概念及增删改查作出探讨,欢迎指教。
一、链表结构和静态/动态链表
二、单链表的建立与遍历
三、单链表的插入与删除
四、双向链表的概念
五、双向链表的建立与遍历
六、双向链表的元素查找
七、循环链表的概念
八、合并两个链表的实例
九、链表实战
拓展思维、拉到最后去看看 (•̀ᴗ•́)و ̑̑
一、链表结构和静态/动态链表
链表是一种常见的数据结构——与数组不同的是:
1.数组首先需要在定义时声明数组大小,如果像这个数组中加入的元素个数超过了数组的长度时,便不能正确保存所有内容;链表可以根据大小需要进行拓展。
2.其次数组是同一数据类型的元素集合,在内存中是按一定顺序连续排列存放的;链表常用malloc等函数动态随机分配空间,用指针相连。
链表结构示意图如下所示:
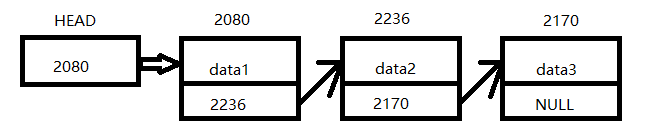
在链表中,每一个元素包含两个部分;数据部分和指针部分。数据部分用来存放元素所包含的数据,指针部分用来指向下一个元素。最后一个元素的指针指向NULL,表示指向的地址为空。整体用结构体来定义,指针部分定义为指向本结构体类型的指针类型。
静态链表需要数组来实现,即把线性表的元素存放在数组中。数组单元存放链表结点,结点的链域指向下一个元素的位置,即下一个元素所在数组单元的下标。这些元素可能在物理上是连续存放的,也有可能是不连续的,它们之间通过逻辑关系来连接——这就要涉及到数组长度定义的问题,实现无法预知定义多大的数组,动态链表随即出现。
动态链表指在程序执行过程中从无到有地建立起一个链表,即一个一个地开辟结点和输入各结点的数据,并建立起前后相连的关系。
二、单链表的建立与遍历
单链表中,每个结点只有一个指针,所有结点都是单线联系,除了末为结点指针为空外,每个结点的指针都指向下一个结点,一环一环形成一条线性链。
链表的创建过程:
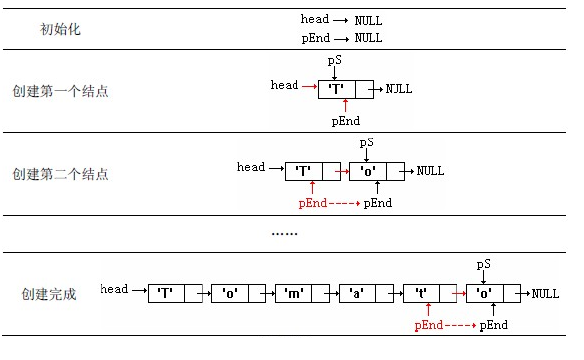
接下来在源码中建立并遍历输出一个单链表。
#include <stdio.h> #include <stdlib.h> #include <malloc.h> /*单向链表*/ struct Student/*建立学生信息结构体模型*/ { char cName[20];/*学生姓名*/ int iNumber;/*学生学号*/ struct student *next;/*指向本结构体类型的指针类型*/ }; int iCount;/*全局变量表示链表长度*/ struct Student *Create();/*创建链表函数声明*/ void print(struct Student *);/*遍历输出链表函数声明*/ int main() { int insert_n=2;/*定义并初始化要插入的结点号*/ int delete_n=2;/*定义并初始化要删除的结点号*/ struct Student *pHead;/*声明一个指向学生信息结构体的指针作pHead为头结点传递*/ pHead=Create();/*创建链表,返回链表的头指针给pHead*/ print(pHead);/*将指针pHead传入输出函数遍历输出*/ return 0; } struct Student *Create() { struct Student *pHead=NULL;/*初始化链表,头指针为空*/ struct Student *pEnd,*pNew; iCount=0;/*初始化链表长度*/ pEnd=pNew=(struct Student *)malloc(sizeof(struct Student));/*动态开辟一个学生信息结构体类型大小的空间,使得pEnd和pNew同时指向该结构体空间*/ scanf("%s",pNew->cName);/*从输入流获取第一个学生姓名*/ scanf("%d",&pNew->iNumber);/*从输入流获取第一个学生学号*/ while(pNew->iNumber!=0)/*设定循环结束条件——学号不为0时*/ { iCount++;/*链表长度+1,即学生信息个数+1*/ if(iCount==1)/*如果链表长度刚刚加为1,执行*/ { pNew->next=pHead;/*使指针指向为空*/ pEnd=pNew;/*跟踪新加入的结点*/ pHead=pNew;/*头结点指向首结点*/ } else/*如果链表已经建立,长度大于等于2时,执行*/ { pNew->next=NULL;/*新结点的指针为空*/ pEnd->next=pNew;/*原来的结点指向新结点*/ pEnd=pNew;/*pEnd指向新结点*/ } pNew=(struct Student *)malloc(sizeof(struct Student));/*再次分配结点的内存空间*/ scanf("%s",pNew->cName);/*从输入流获取第一个学生姓名*/ scanf("%d",&pNew->iNumber);/*从输入流获取第一个学生学号*/ } free(pNew);/*释放结点空间*/ return pHead;/*返回创建出的头指针*/ } void print(struct Student *pHead) { struct Student *pTemp;/*定义指向一个学生信息结构体类型的临时指针*/ int iIndex=1;/*定义并出事哈变量iIndex,用来标识第几个学生(信息)*/ printf("总共%d个学生(信息): ",iCount); pTemp=pHead;/*指针得到首结点的地址*/ while(pTemp!=NULL)/*当临时指针不指向NULL时*/ { printf("第%d个学生信息: ",iIndex); printf("姓名:%s",pTemp->cName); /*输出姓名*/ printf("学号:%d",pTemp->iNumber);/*输出学号*/ pTemp=pTemp->next;/*移动临时指针到下一个结点*/ iIndex++;/*进行自加运算*/ } }
三、单链表的插入与删除
在本实例中,插入时根据传递来的学号,插入到其后。
删除时根据其所在链表的位置,删除并释放该空间。
主函数增加如下:
int main() { int insert_n=2;/*定义并初始化要插入的结点号*/ int delete_n=2;/*定义并初始化要删除的结点号*/ struct Student *pHead;/*声明一个指向学生信息结构体的指针作pHead为头结点传递*/ pHead=Create();/*创建链表,返回链表的头指针给pHead*/ pHead=Insert(pHead,insert_n);/*将指针pHead和要插入的结点数传递给插入函数*/ print(pHead);/*将指针pHead传入输出函数遍历输出*/ Delete(pHead,delete_n);/*将指针pHead和要删除的结点数传递给删除函数*/ print(pHead);/*将指针pHead传入输出函数遍历输出*/ return 0; }
插入函数:
struct Student *Insert(struct Student *pHead,int number) { struct Student *p=pHead,*pNew;/*定义pNew指向新分配的空间*/ while(p&&p->iNumber!=number) p=p->next;/*使临时结点跟踪到要插入的位置(该实例必须存在学号为number的信息,插入其后,否则出错)*/ printf("姓名和学号: "); /*分配内存空间,返回该内存空间的地址*/ pNew=(struct Student *)malloc(sizeof(struct Student)); scanf("%s",pNew->cName); scanf("%d",&pNew->iNumber); pNew->next=p->next;/*新结点指针指向原来的结点*/ p->next=pNew;/*头指针指向新结点*/ iCount++;/*增加链表结点数量*/ return pHead;/*返回头指针*/ }
删除函数:
void Delete(struct Student *pHead,int number) { int i; struct Student *pTemp;/*临时指针*/ struct Student *pPre;/*表示要删除结点前的结点*/ pTemp=pHead;/*得到链表的头结点*/ pPre=pTemp; for(i=0;i<number;i++) {/*通过for循环使得Temp指向要删除的结点*/ pPre=pTemp; pTemp=pTemp->next; } pPre->next=pTemp->next;/*连接删除结点两边的结点*/ free(pTemp);/*释放要删除结点的内存空间*/ iCount--;/*减少链表中的结点个数*/ }
四、双向链表的概念
双向链表基于单链表。单链表是单向的,有一个头结点,一个尾结点,要访问任何结点,都必须知道头结点,不能逆着进行。而双链表添加了一个指针域,通过两个指针域,分别指向结点的前结点和后结点。这样的话,可以通过双链表的任何结点,访问到它的前结点和后结点。
在双向链表中,结点除含有数据域外,还有两个链域,一个存储直接后继结点的地址,一般称为右链域;一个存储直接前驱结点地址,一般称之为左链域。
双向链表结构示意图:
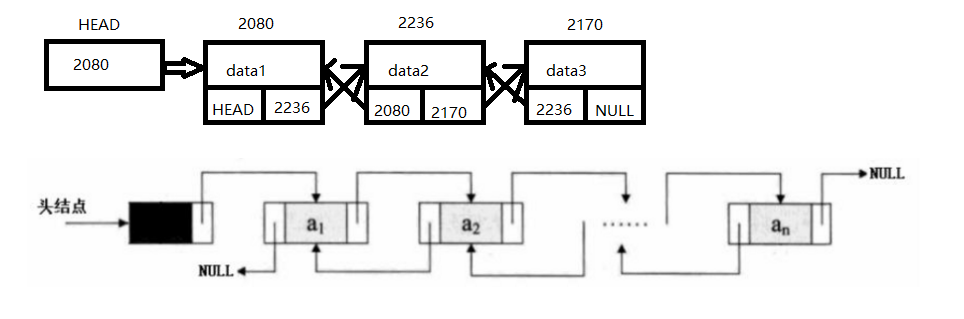
五、双向链表的建立与遍历
双向链表的源码实战和单链表类似,只是多了第二个指针域的控制,这里直接贴上没有注释的源代码。
#include <stdio.h> #include <stdlib.h> #include <malloc.h> #define N 10 typedef struct Node { char name[20]; struct Node *llink,*rlink; }STUD; STUD *creat(int);void print(STUD *); int main() { int number; char studname[20]; STUD *head,*searchpoint; number=N; head=creat(number); print(head); printf("请输入你要查找的人的姓名:"); scanf("%s",studname); searchpoint=search(head,studname); printf("你所要查找的人的姓名是:%s",*&searchpoint->name); return 0; } STUD *creat(int n) { STUD *p,*h,*s; int i; if((h=(STUD *)malloc(sizeof(STUD)))==NULL) { printf("不能分配内存空间"); exit(0); } h->name[0]='�'; h->llink=NULL; h->rlink=NULL; p=h; for(i=0;i<n;i++) { if((s=(STUD *)malloc(sizeof(STUD)))==NULL) { printf("不能分配内存空间"); exit(0); } p->rlink=s; printf("请输入第%d个人的姓名",i+1); scanf("%s",s->name); s->llink=p; s->rlink=NULL; p=s; } h->llink=s; p->rlink=h; return(h); } void print(STUD *h) { int n; STUD *p; p=h->rlink; printf("数据信息为: "); while(p!=h) { printf("%s ",&*(p->name)); p=p->rlink; } printf(" "); }
六、双向链表的元素查找
查找函数 STUD *search(STUD *,char *);
STUD *search(STUD *h,char *x) { STUD *p; char *y; p=h->rlink; while(p!=h) { y=p->name; if(strcmp(y,x)==0) return(p); else p=p->rlink; } printf("没有查到该数据!"); }
七、循环链表的概念
类似于单链表,循环链表也是一种链式的存储结构,由单链表演化而来。
单链表的最后一个结点的指针指向NULL,而循环链表的最后一个结点的指针指向链表头结点。
这样头尾相连,形成了一个环形的数据链。
循环链表的建立不需要专门的头结点。
判断循环链表是否为尾结点时,只需判断该节点的指针域是否指向链表头节点。
八、合并两个链表的实例
建立两个带头节点的学生链表,每个节点包含学号、姓名和成绩,链表都按学号升序排列,将它们合并为一个链表仍按学号升序排列。
算法分析:
合并链表用merge()函数实现。函数中定义3个工作指针a、b、c,其中a、b分别指向La链表、Lb链表的当前结点,C指向合并后的链表尾结点。合并后链表的头结点共用La链表的头结点。
①合并前,先让a和b分别指向两个链表的第一个结点,c指向La链表的头结点。
②合并时应该分3种情况讨论,即La和Lb都没有处理完;La没处理完,但Lb处理完毕;Lb没处理完,但La处理完毕。
③合并过程中应始终将La和Lb链表中较小的一个链接在Lc中,方能保持有序。
void merge(struct stud *La,struct stud *Lb) { struct stud *a,*b,*c; c=La; a=La->next;/* 合并前 */ b=Lb->next; while(a!=NULL && b!=NULL)/* La和Lb都没处理完 */ { if(a->num <= b->num) { c->next=a; c=a; a=a->next; } else { c->next=b; c=b; b=b->next; } } if(a!=NULL) c->next=a;/* 若La没有处理完 */ else c->next=b;/* 若Lb没有处理完 */ free(Lb); /* 释放Lb的头结点 */ }
九、实战
亲自将《C语言程序设计教程--人民邮电出版社》第十章——综合实例影片信息管理系统补成一个完整的程序。
#include <stdio.h> #include <stdlib.h> #include <string.h> // 没有 // 每重新进一次main(),都产生一层函数嵌套,很多次后会发生什么 typedef struct Movie { int id;/*影片编号*/ char name[20];/*影片名称*/ char director[10];/*导演*/ char actor[20];/*主演*/ char date[10];/*上映日期*/ float score;/*影片评分*/ struct Movie *next;/*指向下一个节点的指针*/ }Film; int iCount; Film *pMain=NULL; void menu();/*菜单*/ Film *Create();/*创建链表函数声明*/ void printAll(Film *head);/*显示所有影片的信息*/ Film *findFilm(Film *,int);/*查询影片信息*/ void printFilm(Film *Film);/*输出单个影片信息*/ void modifyFilm(Film *,int);/*修改影片信息*/ void deleteFilm(Film *,int);/*删除影片信息*/ /* 统计链表长度,这里由iCount代替 */ //int length(Film *);/*显示影片总数*/ int main() { menu(); return 0; } void menu() { int choice; int id; printf(" "); printf(" ------------------------------------ "); printf(" | 欢迎使用影片信息管理系统 | "); printf(" ------------------------------------ "); printf(" | 1-录入影片信息 | "); printf(" | 2-查询影片信息 | "); printf(" | 3-修改影片信息 | "); printf(" | 4-删除影片信息 | "); printf(" | 5-显示所有影片 | "); printf(" | 6- 影片总数 | "); printf(" | 7- 退出程序 | "); printf(" 请选择功能 1-7 :"); scanf("%d",&choice); getchar(); system("cls"); switch(choice) { case 1: pMain=Create(); if(pMain==NULL) printf(" 录入出错了 =、= "); else { system("cls"); printf(" 成功录入%d个影片信息 ",iCount); } menu(); break; case 2: if(pMain==NULL) { printf(" 没有任何影片可供查询 "); } else { printf(" 输入查询的id:"); scanf("%d",&id); printFilm(findFilm(pMain,id)); } menu(); break; case 3: if(pMain==NULL) { printf(" 没有任何影片可供修改 "); } else { printf(" 输入修改的id:"); scanf("%d",&id); modifyFilm(pMain,id); system("cls"); printf(" 修改成功 "); } menu(); break; case 4: if(pMain==NULL) { printf(" 没有任何影片可供删除 "); } else { printf(" 输入删除的id:"); scanf("%d",&id); deleteFilm(pMain,id); system("cls"); printf(" 删除成功 "); } menu(); break; case 5: if(pMain==NULL) { printf(" 没有任何影片可供显示 "); menu(); } else printAll(pMain); menu(); break; case 6: printf(" 影片总数为:%d",iCount); menu(); break; case 7: exit(0); break; default: menu(); break; } } Film *Create() { int flag; Film *pHead=NULL; Film *pNew,*pEnd; Film *qq; pEnd=pNew=(Film *)malloc(sizeof(Film)); iCount=0; printf(" 该录入将重新赋值。 "); printf(" 请输入影片编号:"); scanf("%d",&pNew->id); printf(" 请输入影片名称:"); scanf("%s",pNew->name); printf(" 请输入导演:"); scanf("%s",pNew->director); printf(" 请输入主演:"); scanf("%s",pNew->actor); printf(" 请输入上映日期:"); scanf("%s",pNew->date); printf(" 请输入影片评分:"); scanf("%f",&pNew->score); printf(" "); printf(" 是否继续输入(1继续,其它则退出并返回主菜单):"); scanf("%d",&flag); while(flag==1) { iCount++; if(iCount==1) { pNew->next=pHead; pEnd=pNew; pHead=pNew; } else { pNew->next=NULL; pEnd->next=pNew; pEnd=pNew; } pNew=(Film *)malloc(sizeof(Film)); printf(" 请输入影片编号:"); scanf("%d",&pNew->id); printf(" 请输入影片名称:"); scanf("%s",pNew->name); printf(" 请输入导演:"); scanf("%s",pNew->director); printf(" 请输入主演:"); scanf("%s",pNew->actor); printf(" 请输入上映日期:"); scanf("%s",pNew->date); printf(" 请输入影片评分:"); scanf("%f",&pNew->score); printf(" "); printf(" 是否继续输入(1继续,其它则退出并返回主菜单):"); scanf("%d",&flag); } iCount++; pNew->next=NULL; pEnd->next=pNew; pEnd=pNew; pNew=(Film *)malloc(sizeof(Film)); free(pNew); return(pHead); } void printAll(Film *head) { Film *p=head; if(p)/*链表不为空时才输出表头*/ { printf(" 编号 名称 导演 主演 上映时间 评分 "); printf("-------------------------------------------------------- "); } while(p)/*遍历链表,输出每个结点的信息*/ { printf(" %d %s %s %s %s %f ",p->id,p->name,p->director,p->actor,p->date,p->score); p=p->next; } } Film *findFilm(Film *head,int id) { Film *p=head; while(p&&p->id!=id)/*如果p不为空并且p不是要找的结点*/ p=p->next;/*令p指向下一个结点*/ return p; } void printFilm(Film *film) { if(!film)/*如果指针为空,即不存在该结点*/ printf(" %s ","没有查询到该影片的信息,请检查输入"); else/*若指针不为空则输出影片信息*/ { printf(" 编号 名称 导演 主演 上映时间 评分 "); printf("-------------------------------------------------------- "); printf(" %d %s %s %s %s %f ",film->id,film->name,film->director,film->actor,film->date,film->score); } } void modifyFilm(Film *head,int id) { Film *p=findFilm(head,id);/*首先查找该id的影片,将结果保存在p中*/ if(p)/*如果查找到影片,则可以修改*/ { printf(" ====================================================== "); printf(" ***** 修改影片信息 ***** "); printf(" ====================================================== "); printf("该影片的信息如下: "); printFilm(p); printf(" 请输入影片编号:"); scanf("%d",&p->id); printf(" 请输入影片名称:"); scanf("%s",p->name); printf(" 请输入导演:"); scanf("%s",p->director); printf(" 请输入主演:"); scanf("%s",p->actor); printf(" 请输入上映日期:"); scanf("%s",p->date); printf(" 请输入影片评分:"); scanf("%f",&p->score); } else printf(" 未查询到该影片的信息,请检查输入. "); } void deleteFilm(Film *head,int id) { Film *q,*p=head; if(head->id==id)/*如果要删除的是头结点*/ { head=(head->next); free(p); } else/*若要删除的不是头结点*/ { while(p)/*遍历链表寻找要删除的结点*/ { if(p->id==id) { q->next=p->next; free(p);/*释放内存空间*/ break; } q=p;/*q为p的前驱结点*/ p=p->next; } } } /* 统计链表长度,这里由iCount代替 */ //int length(Film *head)/*统计链表长度*/ //{ // Film *p=head; // int count=0; // while(p)/*遍历链表*/ // { // p=p->next; // ++count; // } // return count; //} 影片信息管理系统
课程设计·账号系统
拓展思维、(•̀ᴗ•́)و ̑̑
既然双向链表可以多出一个指针域用来指向前一个结点,用llink和rlink区分这两个指针域;
那么有没有可能再多几个指针域来放ulink和dlink呢(指向上面的结点和指向下面的结点)?
这样就构成了形象的二维链表而不是一维链表了。
当然,在物理内存上这些链表依然是线性关系。
理论可以实现,那么三维链表呢?
画面太美,有待自己下学期大二学数据结构的时候再拓展。