1.服务器信息
192.168.195.136 master
192.168.195.137 slave1
192.168.195.139 slave2
2.主要配置
第一步
上传es安装包到master节点的指定的目录,这里安装版本是elasticsearch-5.3.3
解压安装包
tar -zxvf elasticsearch-5.3.3.tar.gz
第二步
在解压的安装包下,进入配置文件目录,修改配置,vim config/elasticsearch.yml,只需要关注以下几个配置
cluster.name: my-es #集群名称
node.name: master #当前服务器的ip或hostname
path.data: /home/bigdata/software/elasticsearch-5.3.3/data #数据存放的路径,目录可以多个,以,分隔
network.host: 192.168.195.136 #当前服务器的IP
http.port: 9200 #http端口
discovery.zen.ping.unicast.hosts: ["master", "slave1", "slave2"] #集群全部节点IP或hostname
第三步
创建数据存放目录
mkdir -p /home/bigdata/software/elasticsearch-5.3.3/data
第四步
修改jvm配置:vim config/jvm.options
-Xms1g
-Xmx1g
这里的修改最好是服务器总内存的一半
第五步
将master节点上配置好的scp到其他节点并修改对应的node.name和network.host
scp -r elasticsearch-5.3.3 root@slave1:/home/bigdata/software/
scp -r elasticsearch-5.3.3 root@slave2:/home/bigdata/software/
slave1节点对应的node.name:slave1,network.host:192.168.195.137
slave2节点对应的node.name:slave2,network.host:192.168.195.139
第六步
由于elasticsearch5版本的启动需要非root用户,所以要创建普通用户,修改elasticsearch目录权限,
在root用户下到elasticsearch目录的上一层目录执行下面命令
chown -R esuser:esuser elasticsearch-5.3.3
注意每个节点都需要
3.启动及部署不成功排错
按上面布置配置好后,启动es集群,在es目录下执行,只能用esuser用户执行启动脚本
sh bin/elasticsearch
注意每个节点都需要执行上面的命令
如果出现以下信息,证明当前节点执行成功

也可以通过http服务验证,浏览器输入http://nodeIp:9200/

说明:出现以上内容则证明该节点的elasticsearch安装成功。如果cluster_uuid的值为“na”,表示没有安装成功。
启动不成功排错
在配置过程中,只要创建了对应的目录和配置的端口没有被占用的情况下不会出现问题,可能出现的问题是下面截图红色表红处

第一个问题是因为当前linux文件读写的并发数太低,解决方案如下:
查看并发数:ulimit -Hn
修改并发数:ulimit -Hn 65536
第二个问题是因为elasticsearch用户拥有的内存权限太小,至少需要262144,解决方案如下:
切换到root用户
执行命令:
sysctl -w vm.max_map_count=262144
重启服务器
查看结果:
sysctl -a|grep vm.max_map_count
显示:
vm.max_map_count = 262144
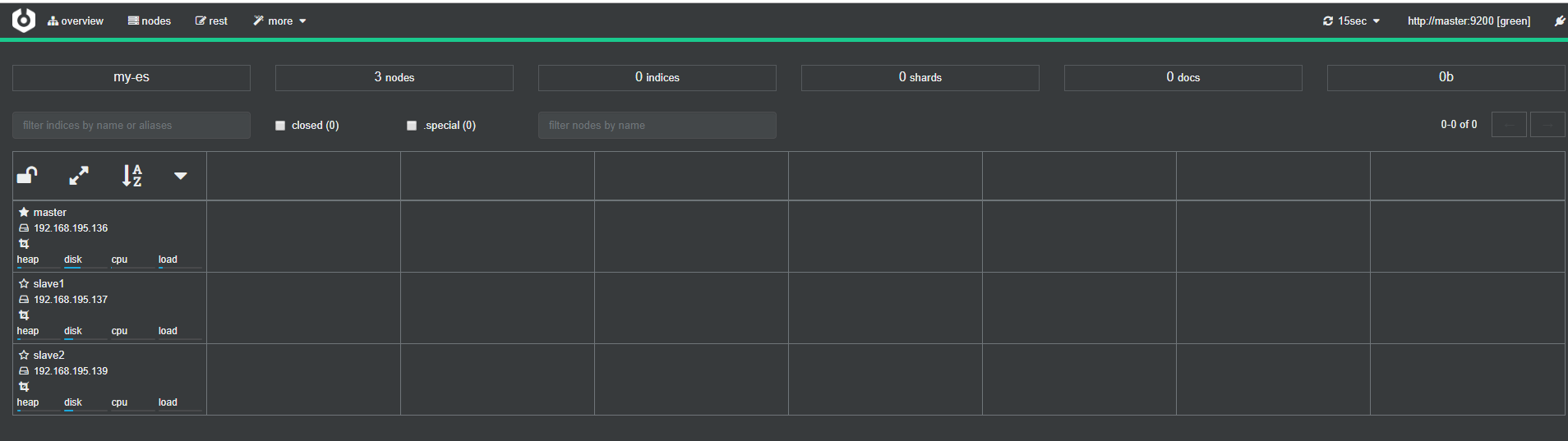
4.客户端工具cerebro部署安装
将cerebro对应的安装包拷贝到服务器的指定目录,这里只需要选一个节点安装就可以了
下载地址:https://github.com/lmenezes/cerebro/releases
解压:tar -zxvf cerebro-0.8.1.tgz
在解压后的当前目录,进去配置文件vim conf/application.conf,只需要配置如下信息:
hosts = [
#{
# host = "http://localhost:9200"
# name = "Some Cluster"
#},
# Example of host with authentication
{
host = "http://master:9200"
# name = "Secured Cluster"
auth = {
username = "admin"
password = "admin"
}
}
]
其他的可以忽略,配置好后启动,在cerebro当前目录执行
sh bin/cerebro -Dhttp.port=9001
注意:
启动之前es集群最好的启动成功状态
最好指定端口,默认端口是9000,如果es集群和hadoop共用,则会出现端口冲突导致启动不成功
页面访问验证,地址http://master:9001/,如果结果入下面,就是正确的