1.hive窗口函数语法
提到Hive SQL的窗口函数,很多开发者就想到row_number() over()或者rank() over()。甚至许多开发者包括之前本人也觉得row_number(),rank()就是最常用的窗口函数。其实这个理解是错误的。hive的窗口函数其实只有一个就是over(),但是大多数情况下over()不单独使用,而是和分析函数组合使用,也就是说row_number()和rank()是分析函数。之所以有这样的误区是因为没用弄清楚窗口函数的语法结构。下面就是HiveSQL的窗口函数的语法结构,其实其他支持SQL的数据库的窗口函数语法结构和hive大体相同。
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
说明:
在一般情况下,分析函数式不可缺的,rows between and可以忽略,partition by和order by可以都有,可以只需要其中一个,这个具体看你查询的业务而定。
与窗口函数over()一起使用的分析函数有如下几类:
a.聚合类
avg()、sum()、max()、min()
这类比较常用
b.排名类
row_number() --按照值排序时产生一个自增编号,不会重复(如:1、2、3、4、5、6)
rank() --按照值排序时产生一个自增编号,值相等时会重复,会产生空位(如:1、2、3、3、3、6)
dense_rank() --按照值排序时产生一个自增编号,值相等时会重复,不会产生空位(如:1、2、3、3、3、4)
这类是最常用的
c.其他类
lag --(列名,往前的行数,[行数为null时的默认值,不指定为null]),可以计算用户上次购买时间,或者用户下次购买时间。
lead --(列名,往后的行数,[行数为null时的默认值,不指定为null])
ntile(n) --把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号
这类用得比较少,具体看业务查询的要求
2.hive窗口函数实例1-模拟抖音用户埋点数据
准备测试数据
如下是模拟抖音用户埋点数据,当用户上线,有一条埋点记录,用户下线也有一点埋点记录
1,1,20201210,1607558400
2,2,20201210,1607558402
3,3,20201210,1607558403
4,4,20201210,1607558406
5,1,20201210,1607558500
6,2,20201210,1607558510
7,3,20201210,1607558520
8,5,20201210,1607558525
9,6,20201210,1607558529
10,4,20201210,1607558532
11,2,20201210,1607558535
12,5,20201210,1607558540
13,1,20201210,1607558545
14,6,20201210,1607558550
15,2,20201210,1607558560
16,1,20201210,1607558570
17,1,20201211,1607644805
18,2,20201211,1607644806
19,3,20201211,1607644809
20,4,20201211,1607644812
21,1,20201211,1607644815
22,2,20201211,1607644820
23,3,20201211,1607644828
24,5,20201211,1607644832
25,6,20201211,1607644843
26,4,20201211,1607644849
27,2,20201211,1607644856
28,5,20201211,1607644860
29,1,20201211,1607644863
30,6,20201211,1607644878
31,2,20201211,1607644885
32,1,20201211,1607644899
创建测试表并导入数据
CREATE EXTERNAL TABLE IF NOT EXISTS `douyin_maidian_log`
(
id string,
user_id string,
day string,
time_stamp int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath '/home/test/maidian.log' into table douyin_maidian_log;
查询用户明细及当前表中数据总量
select *,count(user_id) over() as total from douyin_maidian_log;
查询结果
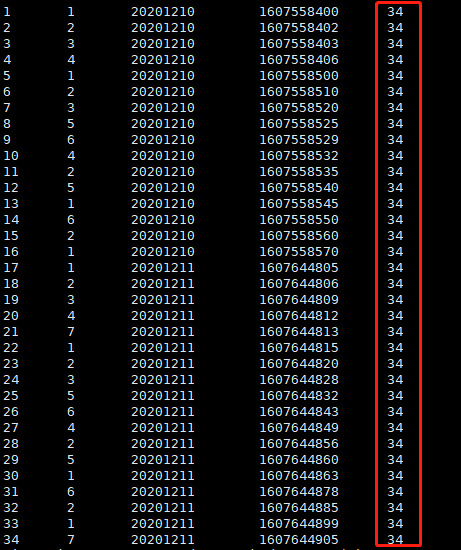
可能会觉得不用窗口函数也可以实现,但是需要先查询总数再与埋点明细表做关联。
查询用户明细及当前每天的用户埋点总数
select *,count(user_id) over(partition by day) from douyin_maidian_log;
查询结果
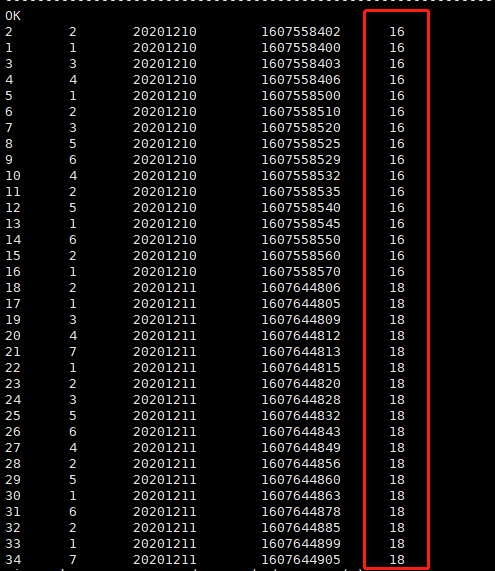
查询用户明细及当前每天的用户个数
select t1.*,t2.total from douyin_maidian_log t1,(select day,count(distinct user_id) total from douyin_maidian_log group by day) t2 where t1.day=t2.day;
查询结果
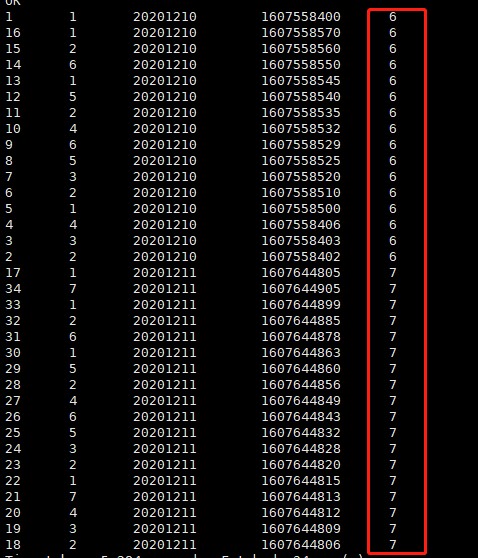
这个查询开窗函数查不出来
查询每个用户每次在线时的在线时长
埋点日志是一个user_id最早的一条记录为上线时间,该user_id的下一条记录为下线时间,紧挨着该条记录的下一条记录为再一次上线时间,依次类推
select t12.user_id,t11.time_stamp-t12.time_stamp,row_number() over(partition by t12.user_id) from
(select t1.user_id user_id,t1.time_stamp time_stamp,t1.rn rn from
(select user_id,time_stamp,row_number() over(partition by user_id order by time_stamp) as rn from douyin_maidian_log) t1 where t1.rn%2=1) t12,
(select t1.user_id user_id,t1.time_stamp time_stamp,t1.rn-1 rn from
(select user_id,time_stamp,row_number() over(partition by user_id order by time_stamp) as rn from douyin_maidian_log) t1 where t1.rn%2=0) t11
where t12.user_id=t11.user_id and t12.rn=t11.rn;
查询结果
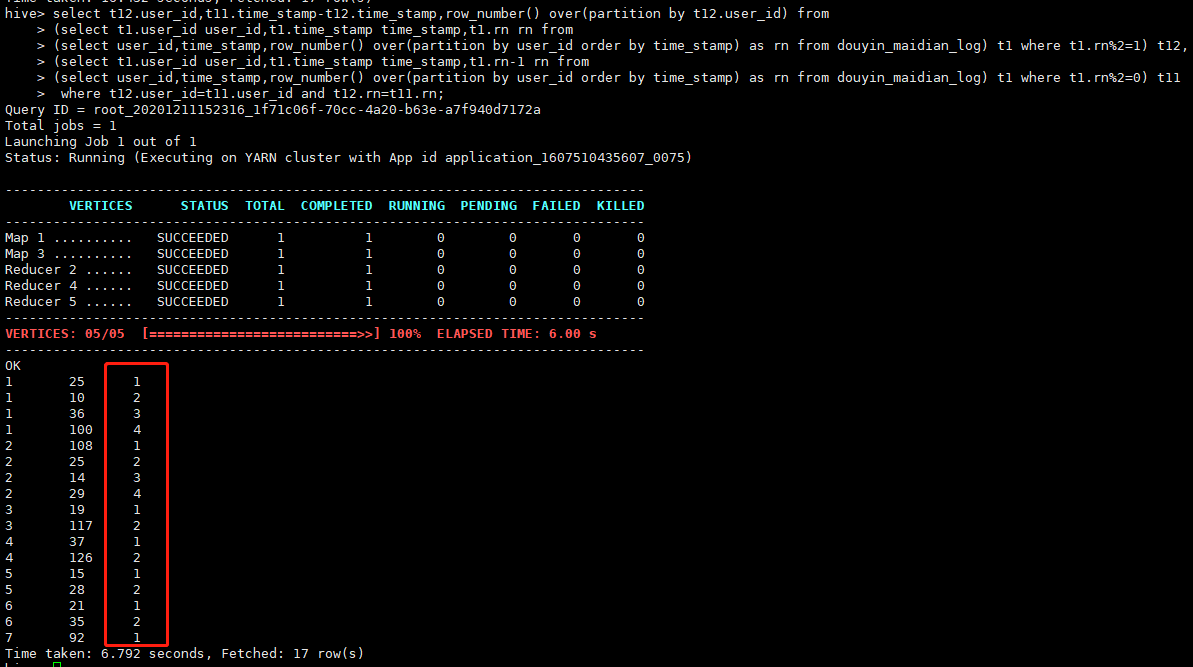
如上结果可以看出user_id为1的用户有四次在线,有一次在线时长为25s,有一次在线时长为10s。关于这个查询有优化空间或其他写法,还有很多奥妙在,欢迎感兴趣的读者留言探讨
引申出一个查询:查询当前埋点表每个用户的总在线时长
select tb.user_id,max(tb.total) from
(select t12.user_id user_id,t11.time_stamp-t12.time_stamp total,row_number() over(partition by t12.user_id) rn from
(select t1.user_id user_id,t1.time_stamp time_stamp,t1.rn rn from
(select user_id,time_stamp,row_number() over(partition by user_id order by time_stamp) as rn from douyin_maidian_log) t1 where t1.rn%2=1) t12,
(select t1.user_id user_id,t1.time_stamp time_stamp,t1.rn-1 rn from
(select user_id,time_stamp,row_number() over(partition by user_id order by time_stamp) as rn from douyin_maidian_log) t1 where t1.rn%2=0) t11
where t12.user_id=t11.user_id and t12.rn=t11.rn) tb group by tb.user_id;
当然还可以引申出很多查询:如当前每个用户在线时长最大的一次是多长,总在线时长最多的user_id,在线次数最多的user_id,依照上面查询,这些查询都较为简单不做举例
可能有细心的读者注意到,如果某个user_id的用户只有一条上线记录,或者以前user_id有上线或下线再次上线没有下线时间,上面SQL是不是有问题,可以通过造数据验证上面的SQL是没有问题的。如果一直在线没有下线的记录,上线的这条记录不会被统计在线时长上的
当然以上两个查询也可以查某一天当前所有用户的在线时长,这里SQL就不举例了,非常简单。
3.hive窗口函数实例2
准备测试数据
20191020,11111,85
20191020,22222,83
20191020,33333,86
20191021,11111,87
20191021,22222,65
20191021,33333,98
20191022,11111,67
20191022,22222,34
20191022,33333,88
20191023,11111,99
20191023,22222,33
创建测试表并导入数据
CREATE EXTERNAL TABLE IF NOT EXISTS user_score
(day string,
userid string,
score int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath '/home/test/user_score.log' into table user_score;
查询每一天所有score大于80分的用户总数
select t.day,max(t.total) from
(select day,userid,score,count(userid) over(partition by day rows between unbounded preceding and current row) total
from user_score
where score>80) t group by t.day;
查询结果
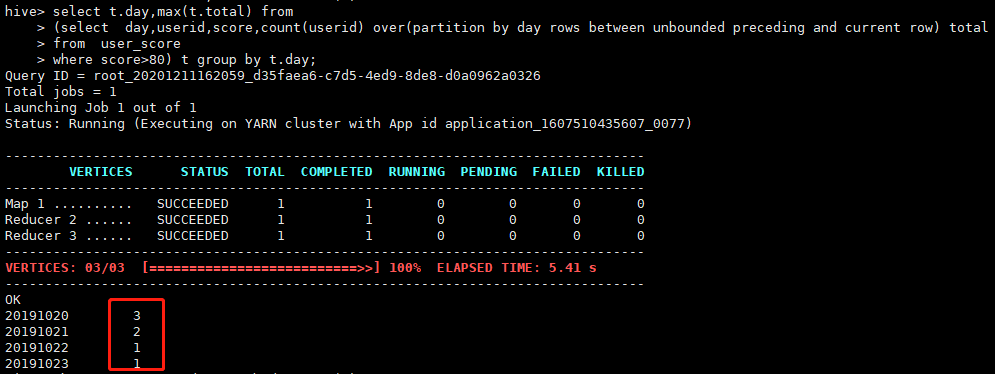
这里这句rows between unbounded preceding and current row加不加不影响查询结果
查询每个用户到当前日期分数大于80的天数
select *,count(userid) over(partition by userid order by day) as total
from user_score where score>80 order by day,userid;
查询结果
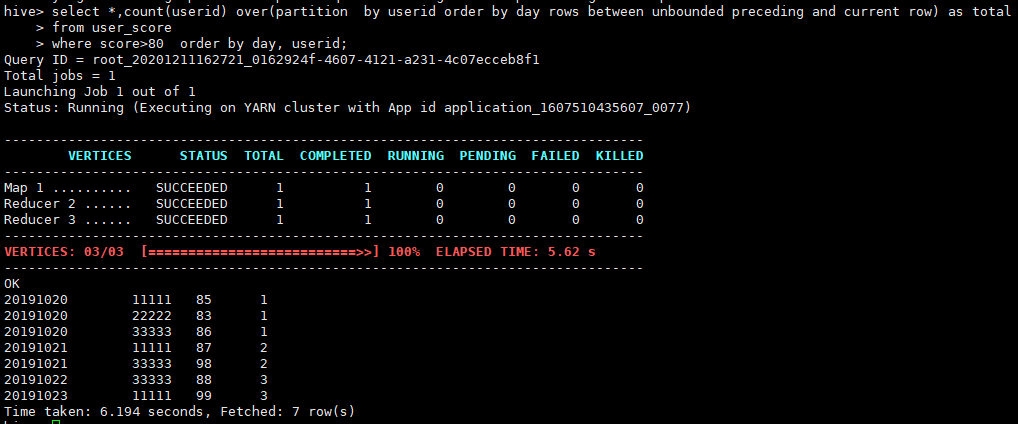
这里这句rows between unbounded preceding and current row加不加不影响查询结果
4.hive窗口函数实例3
准备测试数据
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
创建测试表并导入数据
create table business
(
name string,
orderdate string,
cost int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
#加载数据
load data local inpath "/home/test/business.log" into table business;
查询在2017年4月份购买过的顾客及总人数
select *,count(name) over() as total from business where substr(orderdate,1,7)='2017-04';
查询结果
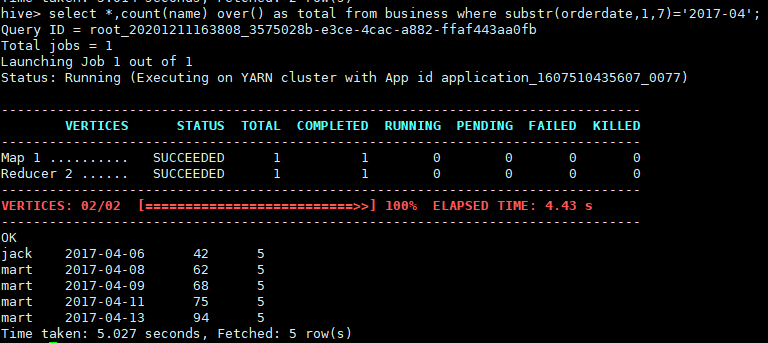
这里用group by查询不出来的,比如用
select name,count(name) from business where substr(orderdate,1,7)='2017-04' group by name;
只能查询出那些人购买及他购买的次数,如果想要得到以上结果就需要做子表关联查询
查询每个顾客的购买明细及每个月购买总额
select *,sum(cost) over(partition by name,substr(orderdate,1,7)) total_amount from business;
查询结果
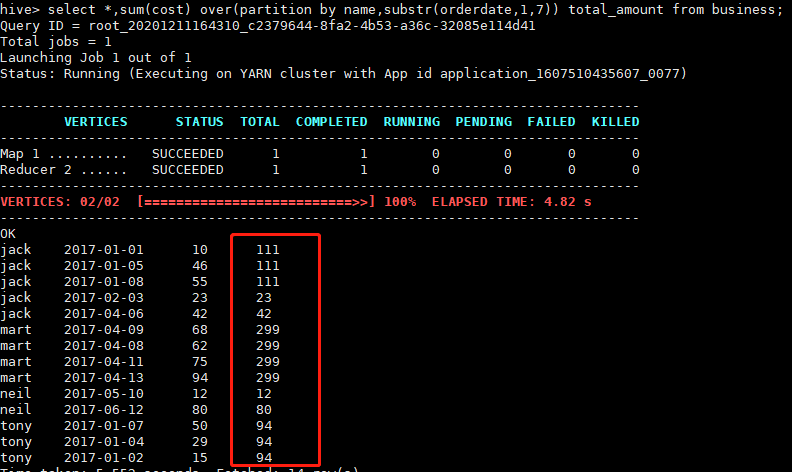
查询顾客的购买明细及到目前为止每个顾客购买总金额
select *,sum(cost) over(partition by name order by orderdate ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) total_amount from business;
查询结果
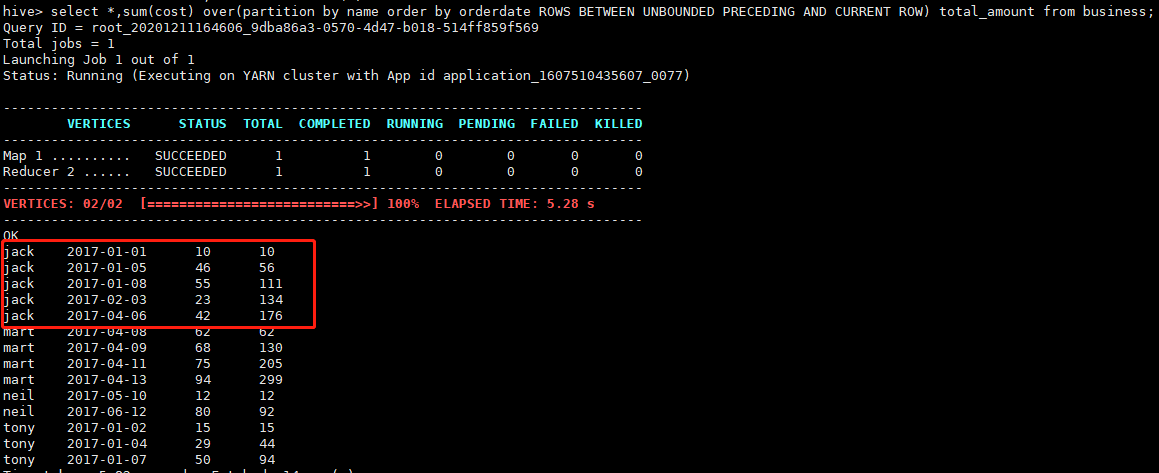
注意观察查询出的结果,结果是累加的,这种查询在数据分析中比较常用,在实时数仓应用中也用得比较多
查询顾客上次的购买时间,如果是第一次购买上次购买时间为null
select name,orderdate,cost,lag(orderdate,1) over(partition by name order by orderdate) last_date from business;
查询结果
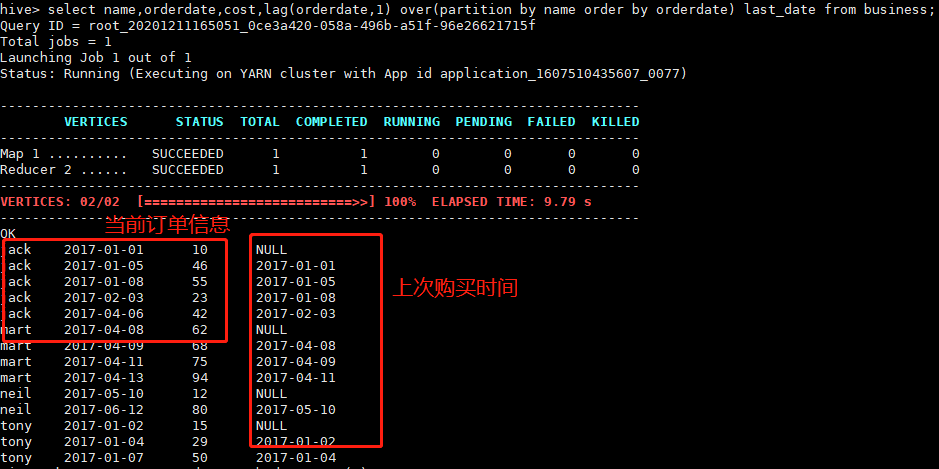
注意观察查询出的结果,这种查询在数据分析中比较常用,在实时数仓应用中也用得比较多
5.hive窗口函数实例4
准备测试数据
孙悟空,语文,87
孙悟空,数学,95
孙悟空,英语,68
大海,语文,94
大海,数学,56
大海,英语,84
宋宋,语文,64
宋宋,数学,86
宋宋,英语,84
婷婷,语文,65
婷婷,数学,85
婷婷,英语,78
创表并加装数据
create table score
(
name string,
subject string,
score int
) row format delimited fields terminated by ",";
#加载数据
load data local inpath '/home/test/score.log' into table score;
查询每门学科学生成绩排名
select *,
row_number() over(partition by subject order by score desc),--不并列排名
rank() over(partition by subject order by score desc),--并列空位排名
dense_rank() over(partition by subject order by score desc)--并列不空位
from score;
查询结果

查询每门学科成绩排名top n的学生
select * from
(select *,row_number() over(partition by subject order by score desc) rmp from score
) t where t.rmp<=3;
查询结果
