import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris from sklearn import metrics %matplotlib inline
#载入数据 iris = load_iris() x = iris.data y = iris.target x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=0) #数据处理 sc = StandardScaler() x_train_std = sc.fit_transform(x_train) x_test_std = sc.transform(x_test) #建立模型 dt = DecisionTreeClassifier(criterion='entropy',max_depth=3) #先设置一个三层的决策树,设置划分标准为信息增益 dt.fit(x_train_std,y_train) y_pred = dt.predict(x_test_std) accuracy = metrics.accuracy_score(y_test,y_pred) accuracy
输出结果:0.97777777777777775
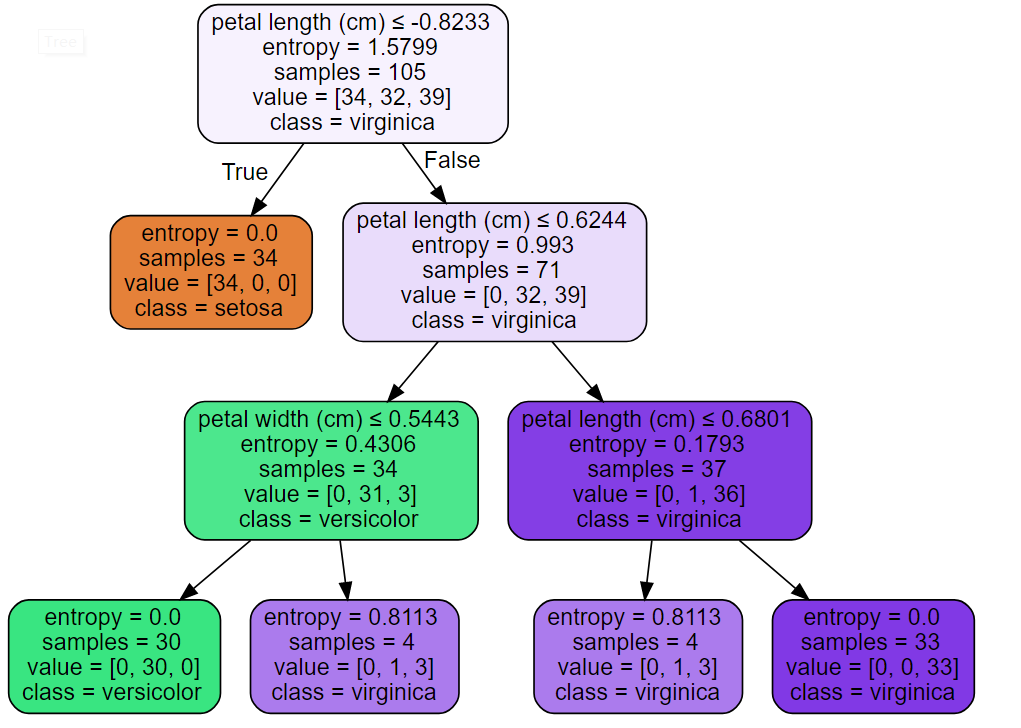
#决策树输出到pdf from sklearn import tree import graphviz dot_data = tree.export_graphviz(dt,out_file=None) graph = graphviz.Source(dot_data) graph.render('iris') #直接输出决策树 dot_data = tree.export_graphviz(dt, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) graph = graphviz.Source(dot_data) graph
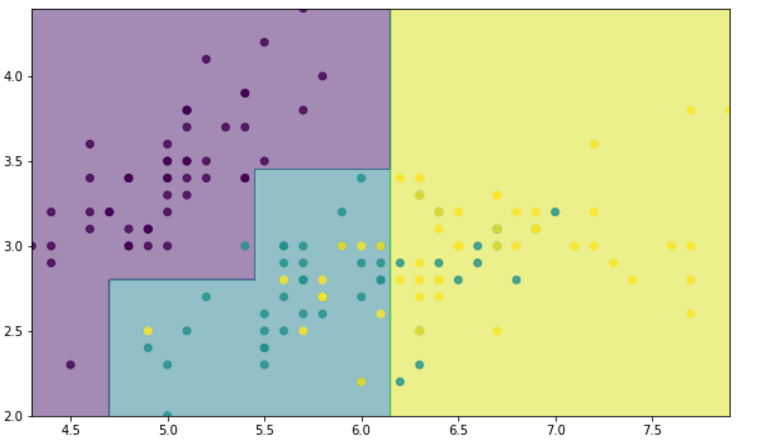
#分类效果画图出来,只选择其中两个变量做图 x = iris.data x = x[:,:2] y = iris.target M,N = 500,500 x1_min,x1_max = x[:,0].min(),x[:,0].max() x2_min,x2_max = x[:,1].min(),x[:,1].max() t1 = np.linspace(x1_min,x1_max,M) t2 = np.linspace(x2_min,x2_max,N) x1,x2 = np.meshgrid(t1,t2) x_test = np.stack((x1.flat,x2.flat),axis=1) dt = DecisionTreeClassifier(max_depth=3) dt.fit(x,y) y_show = dt.predict(x_test) y_show = y_show.reshape(x1.shape) fig = plt.figure(figsize=(10,6),facecolor='w') plt.contourf(x1,x2,y_show,alpha=0.5) plt.scatter(x[:,0],x[:,1],c = y.ravel(),alpha=0.8) plt.xlim(x1_min,x1_max) plt.ylim(x2_min,x2_max)
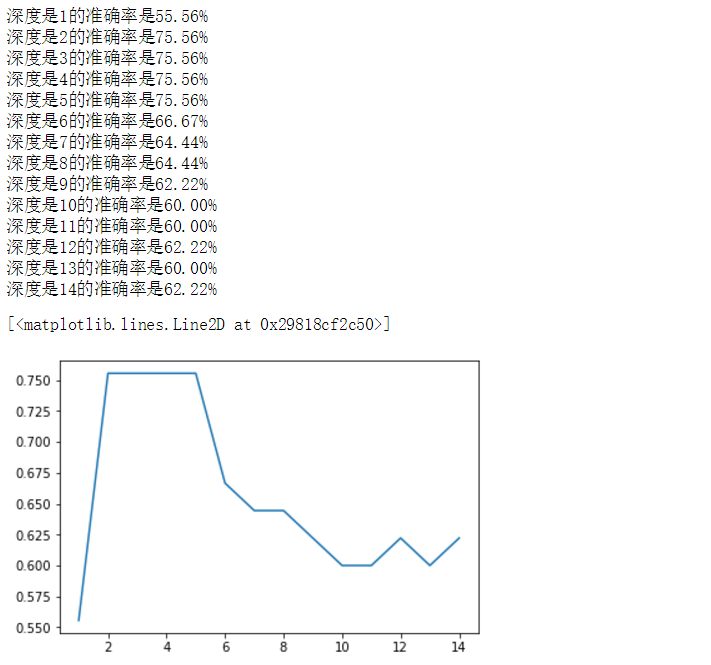
#不同深度的树,对预测结果的好坏 x = iris.data x = x[:,:2] y = iris.target x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=1) sc = StandardScaler() x_train_std = sc.fit_transform(x_train) x_test_std = sc.transform(x_test) err_list = [] for depth in range(1,15): dt = DecisionTreeClassifier(max_depth=depth) dt.fit(x_train_std,y_train) y_pred = dt.predict(x_test_std) print('深度是%s的准确率是%.2f%%'%(depth,metrics.accuracy_score(y_test,y_pred)*100)) err_list.append(metrics.accuracy_score(y_test,y_pred)) plt.plot(range(1,15),err_list)