对于集成学习,由于是多个基学习期共同作用结果,因此在做参数调节时候就有基学习器的参数和集成学习的参数两类
在scikit-learn中,RF的分类类是RandomForestClassifier,回归类是RandomForestRegressor
官方文档:http://scikit-learn.org/stable/modules/ensemble.html#ensemble
RandomForestClassifier : http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier
RandomForestRegressor :http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html#sklearn.ensemble.RandomForestRegressor


1、RF框架参数
参数说明:
1、n_estimators:随机森林的基学习器数量
2、oob_score:是否使用袋外数据来评价模型
2、基学习器参数
基学习器由于可选的很多,sklearn里面的好像默认是决策树
参数说明:
1、max_features:这个最重要:在做决策树时候选择的特征数量 。默认是"None",意味着划分时考虑所有的特征数;如果是"log2"意味着划分时最多考虑log2Nlog2N个特征;如果是"sqrt"或者"auto"意味着划分时最多考虑N−−√N个特征。
2、criterion:决策树划分的衡量,gini是基尼系数,回归树种是mse均方误差
3、max_depth:决策树的最大深度
4、min_samples_split:最小划分的样本数,如果低于这个样本数,决策树不做划分
实例说明:
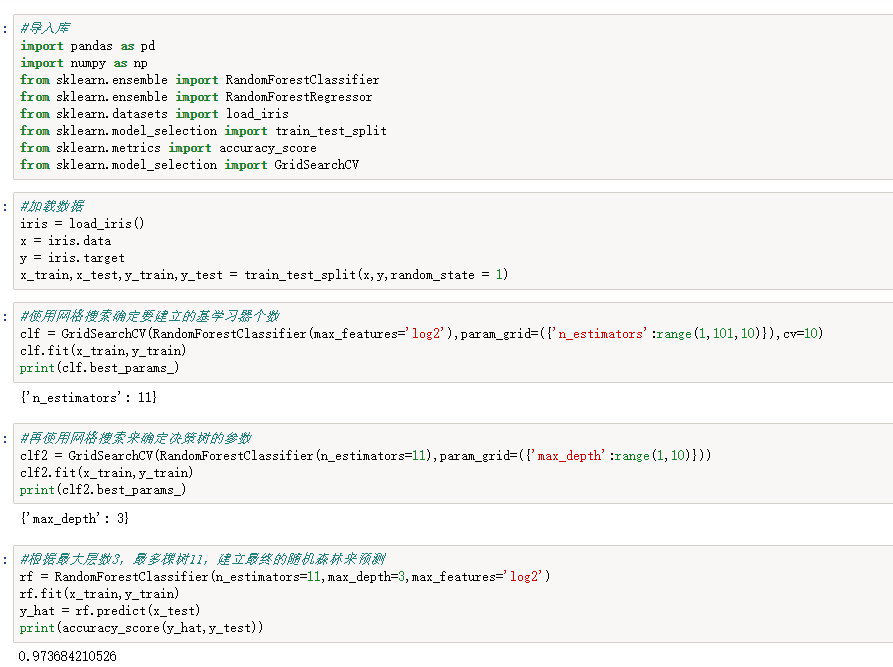
#导入库 import pandas as pd import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import RandomForestRegressor from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.model_selection import GridSearchCV #加载数据 iris = load_iris() x = iris.data y = iris.target x_train,x_test,y_train,y_test = train_test_split(x,y,random_state = 1) #使用网格搜索确定要建立的基学习器个数 clf = GridSearchCV(RandomForestClassifier(max_features='log2'),param_grid=({'n_estimators':range(1,101,10)}),cv=10) clf.fit(x_train,y_train) print(clf.best_params_) #再使用网格搜索来确定决策树的参数 clf2 = GridSearchCV(RandomForestClassifier(n_estimators=11),param_grid=({'max_depth':range(1,10)})) clf2.fit(x_train,y_train) print(clf2.best_params_) #根据最大层数3,最多棵树11,建立最终的随机森林来预测 rf = RandomForestClassifier(n_estimators=11,max_depth=3,max_features='log2') rf.fit(x_train,y_train) y_hat = rf.predict(x_test) print(accuracy_score(y_hat,y_test))