实现过程
一、前期准备
首先打开要爬取的页面,作为根源页面。
我这里使用的百度百科的PHP词条,网址为https://baike.baidu.com/item/PHP/9337?fr=aladdin&fromid=6717846&fromtitle=%EF%BC%B0%EF%BC%A8%EF%BC%B0
然后选取其中适合收集信息的文字内容,右键审查。
可以发现该词条内关联的词条(url)非常多
装好软件和相关第三方库,开搞♂。
环境如下:
python3.6.2 PyCharm
Windows10 第三方库(jieba,wordcloud,bs4,Requests,re)
二、写代码
爬虫的架构大致如下
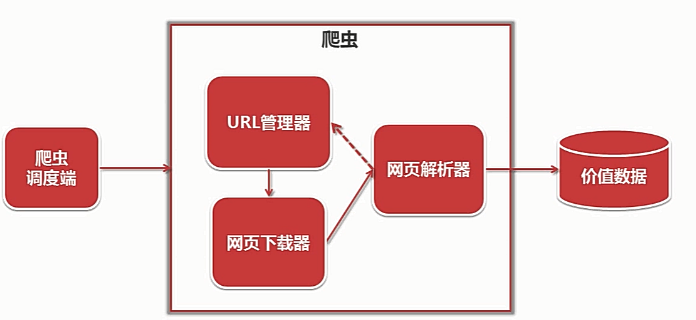
第一步先写个main来做调度,列好要实现的功能。
def __init__(self):
self.urls=url_manager.UrlManager() #url管理器
self.downloader=html_downloader.HtmlDownloader()#下载器
self.parser=html_parser.HtmlParser()#解析
self.outputer=html_outputer.HtmlOutouter()#输出
然后写
def craw(self,root_url):
count=1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url=self.urls.get_new_url()
print('craw %d:%s'%(count,new_url))
html_cont=self.downloader.download(new_url)
new_urls,new_data=self.parser.parse(new_url,html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collest_data(new_data)
if count>500:
break
count+=1
except Exception as e:
print(str(e))
self.outputer.output_html()
if __name__=="__main__":
root_url='https://baike.baidu.com/item/PHP/9337?fr=aladdin&fromid=6717846&fromtitle=%EF%BC%B0%EF%BC%A8%EF%BC%B0'
obj_spider=SpiderMain()
obj_spider.craw(root_url)
url管理器
class UrlManager(object):
def __init__(self):
self.new_urls =set()
self.old_urls = set()
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls)!=0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
接下来写下载器
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
url_ =quote(url,safe=string.printable)
response =request.urlopen(url_)
if response.getcode()!=200:
return None
return response.read()
解析器来一个,百度百科链接的规律是baike.baidu.com/item/*
from bs4 import BeautifulSoup
import re
import urllib.parse
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
links=soup.find_all('a',href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url=urllib.parse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# <div class="lemma-summary" label-module="lemmaSummary">
summary_node = soup.find('div', class_='lemma-summary')
if summary_node is None:
return
res_data['summary'] = summary_node.get_text()
#<div class="para" label-module="para">
para_node = soup.find('div', class_='para')
if para_node is None:
return
res_data['para'] = para_node.get_text()
return res_data
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return
soup=BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls=self._get_new_urls(page_url,soup)
new_data=self._get_new_data(page_url,soup)
return new_urls,new_data
输出到一个叫output.txt的文件
# -*- coding: UTF-8 -*-
class HtmlOutouter(object):
def __init__(self):
self.datas=[]
def collest_data(self, new_data):
if new_data is None:
return
self.datas.append(new_data)
def output_html(self):
fout=open('output.txt','w',encoding='utf-8')
for data in self.datas:
fout.write('%s' % ( data['title']))
fout.write('%s' % data['para'])
fout.write('%s' % data['summary'])
fout.close()
得到txt文件一个
里面有爬了五百个url搞到手的文字内容。
三、生成词云
装词云库时有点小麻烦,下面再说。
#通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
#my_wordcloud = WordCloud().generate(wl_space_split) 默认构造函数
my_wordcloud = WordCloud(
background_color='white', # 设置背景颜色
mask = abel_mask, # 设置背景图片
max_words = 800, # 设置最大现实的字数
stopwords = {}.fromkeys(['以及', '就是','可以','简称','位于','称为','之一','包括','一种','主要']), # 设置停用词
font_path = 'C:/Users/Windows/fonts/simkai.ttf',# 设置字体格式,如不设置显示不了中文
max_font_size = 50, # 设置字体最大值
random_state = 30, # 设置有多少种随机生成状态,即有多少种配色方案
scale=.5
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(abel_mask)
调用,运行
背景图为
生成的词云图为
完成
遇到的问题及解决办法
1.word cloud安装失败,根据错误报告提示缺少vs c++构建工具。通过安装一个vs2017解决。
2.一开始是打算爬百度贴吧的,但是爬百度贴吧的时候IP被拉黑了。本来打算通过动态IP的方式,但是没成功。所以去爬百度百科了。
3.词云生成的图片过于模糊,文字看不清楚。多次尝试发现跟原图的分辨率有关,换张分辨率高的图片获得不错的效果。
4.词云中无意义的词(如连接词等)太多。没搞到常用stopwords文件(csdn要三个积分),只能手动加了几个无意义的过滤词。
5.Windows10的字体文件格式是TTC,兼容TTF,使用ttf字体文件有一定概率失常。
6.尽量使用纯白色背景的图片来当背景图,不然根本看不出轮廓。
7.url,class后面要加_,不然一堆报错。
总结
写这个爬虫的时候暴露出了我的python基础很不好,需要再学好python。
爬虫是很有趣的东西,我会继续去学习更深入、更厉害的知识技能。