原文链接:一文弄懂Flink基础理论
Flink分布式程序包含2个主要的进程:JobManager和TaskManager.当程序运行时,不同的进程就会参与其中,包括Jobmanager、TaskManager和JobClient。
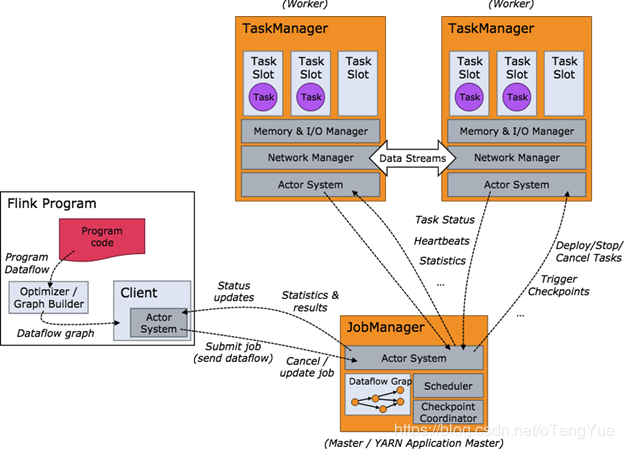
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
JobManager
Master进程,负责Job的管理和资源的协调。包括任务调度,检查点管理,失败恢复等。
当然,对于集群HA模式,可以同时多个master进程,其中一个作为leader,其他作为standby。当leader失败时,会选出一个standby的master作为新的leader(通过zookeeper实现leader选举)。
JobManager包含了3个重要的组件:
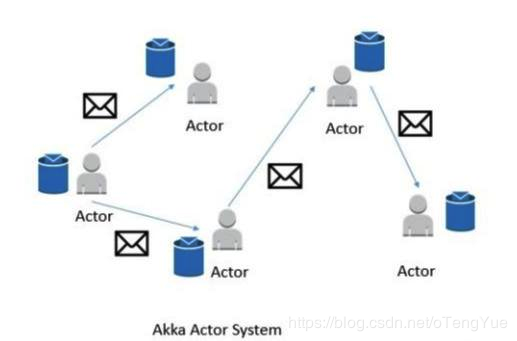
###(1)Actor系统
Flink内部使用Akka模型作为JobManager和TaskManager之间的通信机制。
Actor系统是个容器,包含许多不同的Actor,这些Actor扮演者不同的角色。Actor系统提供类似于调度、配置、日志等服务,同时包含了所有actors初始化时的线程池。
所有的Actors存在着层级的关系。新加入的Actor会被分配一个父类的Actor。Actors之间的通信采用一个消息系统,每个Actor都有一个“邮箱”,用于读取消息。如果Actors是本地的,则消息在共享内存中共享;如果Actors是远程的,则消息通过RPC远程调用。
每个父类的Actor都负责监控其子类Actor,当子类Actor出现错误时,自己先尝试重启并修复错误;如果子类Actor不能修复,则将问题升级并由父类Actor处理。
在Flink中,actor是一个有状态和行为的容器。Actor的线程持续的处理从“邮箱”中接收到的消息。Actor中的状态和行为则由收到的消息决定。
###(2)调度
Flink中的Executors被定义为task slots(线程槽位)。每个Task Manager需要管理一个或多个task slots。
Flink通过SlotSharingGroup和CoLocationGroup来决定哪些task需要被共享,哪些task需要被单独的slot使用。
###(3)检查点
Flink的检查点机制是保证其一致性容错功能的骨架。它持续的为分布式的数据流和有状态的operator生成一致性的快照。Flink的容错机制持续的构建轻量级的分布式快照,因此负载非常低。通常这些有状态的快照都被放在HDFS中存储(state backend)。程序一旦失败,Flink将停止executor并从最近的完成了的检查点开始恢复(依赖可重发的数据源+快照)。
运行架构
常用的类型和操作

参考:
Flink 原理与实现:数据流上的类型和操作:http://wuchong.me/blog/2016/05/20/flink-internals-streams-and-operations-on-streams
Flink Stream 算子:https://flink.sojb.cn/dev/stream/operators
程序结构介绍
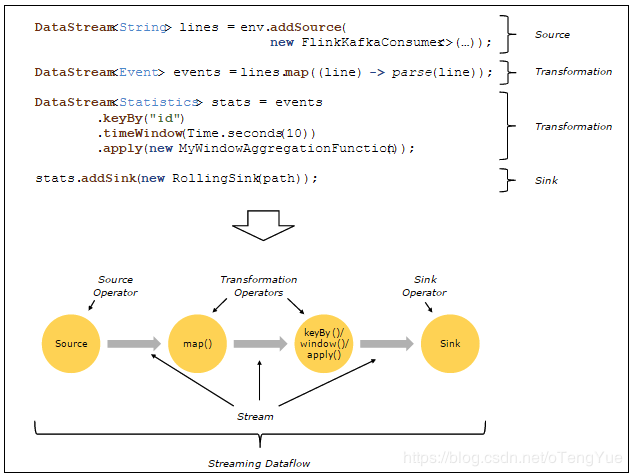
Source,它是整个stream的入口。
Transformation,用于转换一个或多个DataStream从而形成一个新的DataStream对象。
Sink,它流的数据出口。
并行数据流
Flink程序本质上是并行和分布式的。在程序执行期间,一个流会生成一个或者多个stream partition,并且一个operator会生成一个或者多个operator subtask。operator的 subtask 彼此之间是独立的,分别在不同的线程里去执行并且可能分布在不同的机器上或者containers上。
operator的subtasks的数量等于该操作算子的并行度的数量。流的并行度有总是取决于产生它的操作算子的并行度决定的。同一个flink程序中的不同的operators可能有不同的并行度。
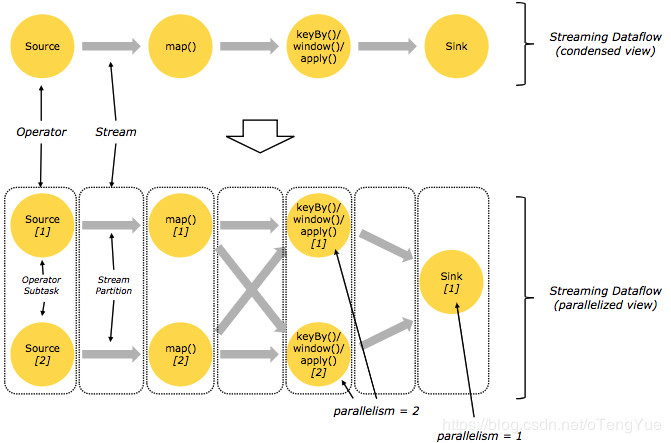
数据流在两个operators之间进行传递的方式有两种:one-to-one 模式 和 redistributing 模式
- one-to-one 模式
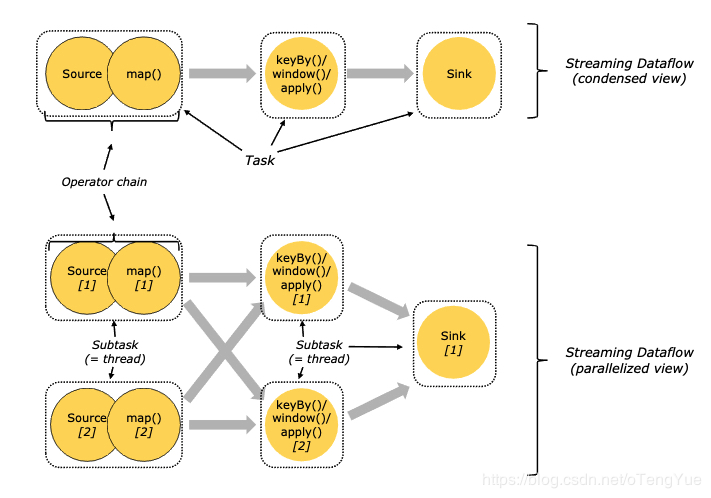
两个operator用此模式传递的时候,会保持数据的分区数和数据的排序,比如:在下图中Source和map() operators之间的数据传递方式;
- Redistributing 模式(重新分配模式)
这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区,比如:在下图中map()和keyBy/window ,keyBy/window和Sink之间的数据传递方式;
Flink每个算子都可以设置并行度,然后就是也可以设置全局并行度。
api设置.map(new RollingAdditionMapper()).setParallelism(10)
全局配置在flink-conf.yaml文件中,parallelism.default,默认是1
Task and Operator Chains
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
可以进行Operator chains的条件
1、上下游的并行度一致
2、下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
3、上下游节点都在同一个 slot group 中(下面会解释 slot group)
4、下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
5、上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
6、两个节点间数据分区方式是 forward(参考理解数据流的分区)
7、用户没有禁用 chain
————————————————